XiaoMi-AI文件搜索系统
World File Search Systemwise

2024 年明智未来领袖研讨会 - 沃尔顿学院
欢迎参加第六届 WISE 未来领袖研讨会!六年前,来自 12 所大学的学生和教职员工参加了第一届 WISE 未来领袖研讨会。今天,我们有 30 所大学与众多行业合作伙伴齐聚一堂。活动主题为“WISE 来自各方”。活动将重点介绍供应链女性所扮演的众多角色(“各方”)。WISE(影响供应链卓越的女性)最初是阿肯色大学的一个学生组织,致力于为供应链职业做好准备、鼓励和激励女性和盟友。WISE 有 4 个战略举措:建立联系、个人和职业发展、领导技能和行业知识。WISE 分会和 WISE 活动已迅速传播到全国各地的大学。感谢在大学和其他地方传播 WISE 愿景的教职员工和学生。继续努力!研讨会是学生和行业领袖的合作。您将听到该领域顶尖女性和盟友的发言。冉冉升起的新星将分享他们的建议。您的人脉将以重大而有意义的方式发展

pg。 1附件-II学科 - 明智的ARS/Net教学大纲...
01。农业生物技术单元1:细胞结构和功能原核和真核细胞结构,细胞壁,质膜,细胞细胞器的结构和功能:液泡,线粒体,质体,高尔基体,Golgi Appratus,er,Er,er,过氧化物症。细胞分裂,细胞周期的调节,蛋白质分泌和靶向,细胞分裂,生长和分化。 单元2:碳水化合物,脂质,蛋白质和核酸的生物分子和代谢结构以及功能,碳水化合物的合成,糖酵解,HMP,柠檬酸周期和代谢调节,氧化磷酸化和氧化磷酸化和底物水平磷酸化磷酸化,植物磷酸化,植物,植物,植物,植物,Hormones,Hormones。 功能分子,抗氧化剂,营养前体,HSP,抗病毒化合物。 单元3:酶学酶,结构构象,分类,测定,分离,纯化和表征,催化特异性,作用机制,活性位点,调节酶活性。 Unit 4: Molecular Genetics Concept of gene, Prokaryotes as genetic system, Prokaryotic and eukaryotic chromosomes, methods of gene isolation and identification, Split genes, overlapping genes and pseudo genes, Organization of prokaryotic and eukaryotic genes and genomes including operan, exon, intron, enhancer promoter sequences and other regulatory elements. 突变自发,诱导和位置,在细菌,真菌和病毒中重组,转化,转导,结合,转座元素和转座。 翻译机制及其控制,翻译后修改。细胞分裂,细胞周期的调节,蛋白质分泌和靶向,细胞分裂,生长和分化。单元2:碳水化合物,脂质,蛋白质和核酸的生物分子和代谢结构以及功能,碳水化合物的合成,糖酵解,HMP,柠檬酸周期和代谢调节,氧化磷酸化和氧化磷酸化和底物水平磷酸化磷酸化,植物磷酸化,植物,植物,植物,植物,Hormones,Hormones。功能分子,抗氧化剂,营养前体,HSP,抗病毒化合物。单元3:酶学酶,结构构象,分类,测定,分离,纯化和表征,催化特异性,作用机制,活性位点,调节酶活性。Unit 4: Molecular Genetics Concept of gene, Prokaryotes as genetic system, Prokaryotic and eukaryotic chromosomes, methods of gene isolation and identification, Split genes, overlapping genes and pseudo genes, Organization of prokaryotic and eukaryotic genes and genomes including operan, exon, intron, enhancer promoter sequences and other regulatory elements.突变自发,诱导和位置,在细菌,真菌和病毒中重组,转化,转导,结合,转座元素和转座。翻译机制及其控制,翻译后修改。单元5:遗传信息的基因表达,操纵子概念,原核生物和真核生物转录的转录机制,转录单位,调节序列,增强序列和增强剂,激活因子,激活因子,共激活因子,共激活因子,共抑制剂,原核生物和真核生物的转化因子和促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进剂,促进因遗传密码。
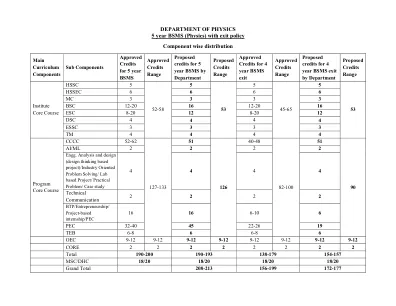


以下页面提供了已通知的中心领域的教学大纲。
后端 VLSI 设计流程知识 - 库、平面规划、布局、布线、验证、测试。规格和原理图单元设计、Spice 模拟、电路元件、交流和直流分析、传输特性、瞬态响应、电流和电压噪声分析、设计规则、微米规则、设计的 Lambda 规则和设计规则检查、电路元件的制造方法、不同单元的布局设计、电路提取、电气规则检查、布局与原理图 (LVS)、布局后模拟和寄生提取、不同的设计问题(如天线效应、电迁移效应、体效应、电感和电容串扰和漏极穿通等)、设计格式、时序分析、反向注释和布局后模拟、DFT 指南、测试模式和内置自测试 (BIST)、ASIC 设计实施。
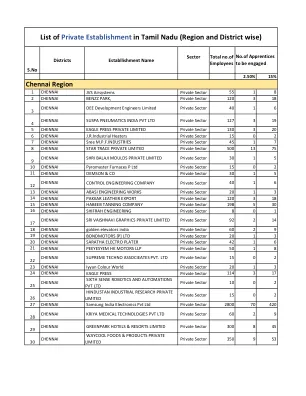
泰米尔纳德邦(区域和地区明智)的私人机构清单
98 Chennai Bimetal轴承有限的私营部门98 2 15 99 Chennai des Private Limited私营部门50 1 8 100 CHENNAI PIXAGONS DIGITION DIGITION私人有限私人私营部门85 2 13 101 Chennai ITC Limited私营部门1046 26 157 102部门330 8 50
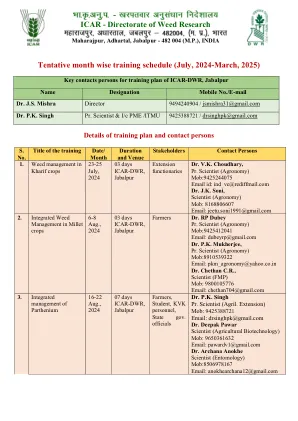
暂定月份的明智培训时间表(2024年7月,三月,2025年)
科学家V.K.博士Choudhary,Pr。科学家(农学)暴民:9422244075电子邮件:ind_vc@rediffmail.com科学家Deepak Pawar博士(农业生物技术)暴民:9650361632电子邮件:Pawardv1@gmail.com J.K. J.K. J.K. Soni,科学家(农学)暴民:8168806607电子邮件:jeetu.soni1991@gmail.com Dasari Sreekanth博士,科学家(植物生理学)暴民:9542681028电子邮件:

明智的生活技术有限公司,有限公司
根据上市规则的规则14.81,应将一系列连接的交易汇总,并将其视为如果它们全部在12个月内输入或其他相关的交易。在2025年2月13日同一天签订了三项销售和购买协议,根据每项协议的审议为3,000,000令吉。在制定三项销售和购买协议时,最高适用的比率超过0.1%,小于5%,总计9,000,000元的总额超过300万港元。因此,根据上市规则的规则14A.76,销售和购买协议下的交易构成了连接的交易,仅受到通知和公告要求的约束,但不受通告(包括独立的财务建议)和股东的批准要求。

策略弹性:在大流行世界中获得有关慈善策略的明智
具有复杂的问题,原因和效果 - 无法线性确定,从而使不合适的方法预先定义进度指标和更改途径。复杂性要求采用更灵活和适应性的方法,这些方法最近被封装在新兴或适应性慈善事业的列中,其核心宗旨涉及对资助者和受赠方在战略中的权力关系的重新平衡(Kania,Kramer,Kramer和Russell,2014年)。Patrizi&Heid Thompson(2011)暗示了这种重新平衡的外观:“基金会需要在战略制定,谈判和辩论中的核心合作伙伴 - 具有成功实施的经验和知识的合作伙伴,他们可以为成功实施而有效地挑战基础假设”(第56页)。
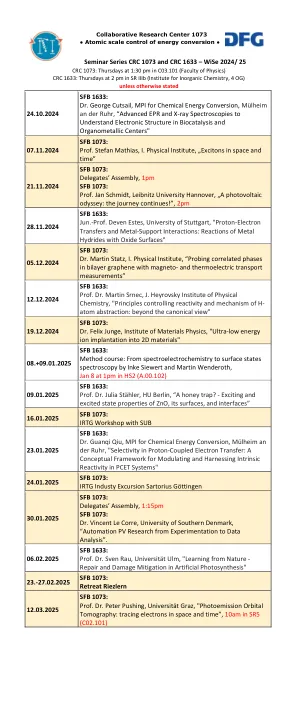
研讨会系列CRC 1073和CRC 1633 - 明智的2024/25 div div div div>
SFB 1633:Guanqi Qiu博士,MPI化学能量转换的MPI,Mülheiman der Ruhr,“质子耦合电子传输中的选择性:调节和利用PCET系统中内在反应性的概念框架”