XiaoMi-AI文件搜索系统
World File Search Systemword2vec

基于Word2vec和Stacking集成学习的文本驱动的飞机故障诊断模型
摘要:传统的飞机维修保障工作主要基于结构化数据。非结构化数据,如文本数据,尚未得到充分利用,这意味着资源的浪费。这些非结构化数据蕴含着巨大的故障知识库,可以为飞机维修保障工作提供决策支持。因此,本文提出了一种基于文本的故障诊断模型。所提方法利用Word2vec将文本单词映射到向量空间,然后将提取的文本特征向量输入基于堆叠集成学习方案的分类器。使用真实的飞机故障文本数据集验证了其性能。结果表明,所提方法的故障诊断准确率为97.35%,比次优方法提高了约2%。


JIOS Vol44 No2.indd
测量文本的语义相似度在自然语言处理领域的各种任务中起着至关重要的作用。在本文中,我们描述了一组我们进行的实验,以评估和比较用于测量短文本语义相似度的不同方法的性能。我们对四种基于词向量的模型进行了比较:Word2Vec 的两个变体(一个基于在特定数据集上训练的 Word2Vec,另一个使用词义的嵌入对其进行扩展)、FastText 和 TF-IDF。由于这些模型提供了词向量,我们尝试了各种基于词向量计算短文本语义相似度的方法。更准确地说,对于这些模型中的每一个,我们测试了五种将词向量聚合到文本嵌入中的方法。我们通过对两种常用的相似度测量进行变体引入了三种方法。一种方法是基于质心的余弦相似度的扩展,另外两种方法是 Okapi BM25 函数的变体。我们在两个公开可用的数据集 SICK 和 Lee 上根据 Pearson 和 Spearman 相关性对所有方法进行了评估。结果表明,在大多数情况下,扩展方法的表现优于原始方法。关键词:语义相似度、短文本相似度、词嵌入、Word2Vec、FastText、TF-IDF

人工智能框架设计研究...
摘要 —本研究旨在研究人工智能 (AI) 思维的定义和属性,以支持 AI 教育,从而帮助教育工作者确定应如何在 K-12 年级开展此类教育。采用文本挖掘方法,使用文本爬取和共词分析,使用 Python 编程语言设计和定义 AI 思维。使用余弦相似度和 word2vec 技术进行共词分析。余弦相似度通过根据出现频率分配权重来提取配对词。word2Vec 的 skip-gram 检查周围的单词并预测配对词。根据共词分析结果,AI 思维正在使用综合思维过程通过讨论、提供、演示和证明过程来解决决策问题。此外,未来的 AI 教育研究必须考虑 AI 思维。本研究旨在作为推动 AI 教育发展的基础研究。
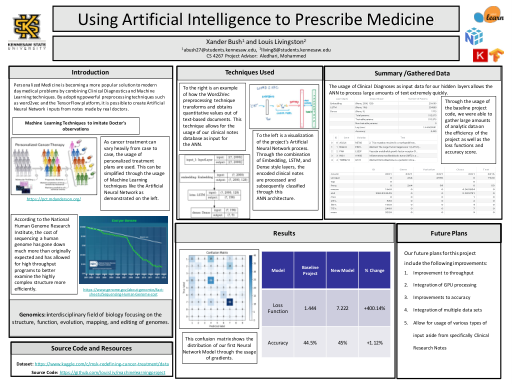
使用人工智能开药 - CS 4732
个性化医疗通过结合临床诊断和机器学习技术,正在成为解决现代医疗问题的更受欢迎的解决方案。通过采用 word2vec 和 TensorFlow 平台等强大的预处理技术,可以根据真实医生的笔记创建人工神经网络输入。

教学大纲-ADASCI认证的生成AI工程师
a。机器学习(ML)范式b。神经网络,体系结构,激活功能,优化技术c。表示学习,嵌入,功能工程d。概率模型,贝叶斯网络,隐藏的马尔可夫模型(HMMS)e。推理和计划f。自然语言处理,令牌化,言论部分(POS)标记,命名实体识别(NER),Word2Vec g。计算机视觉,图像分类,对象检测,图像分割h。基础模型及其角色

基于图的机器学习方法
本研究文章使用图理论和机器学习技术探讨了Instagram影响者网络。随着社交媒体人物的日益影响,了解其网络结构和动态对于有效的营销和品牌参与至关重要。我们将Instagram的影响者生态系统建模为图形,并应用几种机器学习算法,包括Node2VEC和Word2Vec,以执行诸如链接预测和社区检测之类的任务。我们的分析揭示了影响者互动和网络连接性的重要模式,从而为有影响力的行为和在线社区的形成提供了可行的见解。这些发现为优化营销策略和增强社交媒体环境中的品牌合作提供了宝贵的影响。

量子计算文献综述关键词提取与分析
摘要:由于科学出版物数量巨大,且大多为非结构化数据,文献审查过程的复杂性和工作量不断增加。近年来,量子计算研究领域的科学出版物数量也大幅增加。本文概述了如何使用文本挖掘方法在量子计算文献研究中进行信息提取。主要研究目标是应用文本挖掘技术根据科学出版物的摘要自动提取和可视化关键词。该方法一方面利用TF-IDF方法,另一方面利用Word2Vec算法,实现相关文献的自动检测和处理。随后,对结果进行可视化表示,例如动态词云。该分析为量子计算研究领域提供了见解。

比较医学概念表示和患者轨迹预测的神经语言模型
医学概念的有效表示对于电子健康记录的次要分析至关重要。神经语言模型在自动从临床数据中得出医学概念表示方面已显示出希望。但是,尚未对不同语言模型的比较性能,用于创建这些经验表示形式及其编码医学语义的程度,尚未得到广泛的研究。本研究旨在通过评估三种流行语言模型的有效性 - word2vec,fastText和手套 - 在创建捕获其语义含义的医学概念嵌入中的有效性。通过使用大量的数字健康记录数据集,我们创建了患者轨迹,并用它们来训练语言模型。然后,我们通过与生物医学术语进行明确比较来评估学到的嵌入式编码语义的能力,并通过预测具有不同级别可用信息的患者结果和轨迹来隐含。我们的定性分析表明,FastText学到的嵌入的经验簇与从生物医学术语获得的理论聚类模式表现出最高的相似性,分别在0.88、0.80和0.92的经验簇和0.92之间的诊断,过程和医疗代码分别为0.88、0.80和0.92之间。相反,为了预测,Word2Vec和Glove倾向于优于快速文本,而前者的AUROC分别高达0.78、0.62和0.85,分别用于现场长度,再入院和死亡率预测。在预测患者轨迹中的医疗法规时,手套在诊断和药物代码(分别为0.45和0.81)的最高级别上达到了语义层次结构的最高性能(AUPRC分别为0.45和0.81),而FastText优于其他模型的过程代码(AUPRC为0.66)。我们的研究表明,子词信息对于学习医学概念表示至关重要,但是全球嵌入向量更适合于更高级别的下游任务,例如轨迹预测。因此,可以利用这些模型来学习传达临床意义的表示形式,而我们的见解突出了使用机器学习技术来编码医学数据的潜力。

CSCI S-89深度学习课程简介信息
课程描述:在本课程中,将学生介绍到深神经网络的体系结构,即开发出来提取数据的高级特征表示的算法。除了神经网络的理论基础(包括反向传播和随机梯度下降)之外,学生还可以通过Python进行动手实践经验。课程中涵盖的主题包括图像分类,时间序列预测,文本矢量化(TF-IDF和Word2Vec),自然语言翻译,语音识别和深度强化学习。学生学习如何使用应用程序界面(API),例如Tensorflow和Keras来构建各种深神经网络:卷积神经网络(CNN),复发性神经网络(RNN),自组织图(SOM),生成对抗网络(GANS)和长期的短期记忆(LSTM)。某些模型将需要在Amazon Web Services(AWS)云中使用图形处理单元(GPU)启用的Amazon Machine Images(AMI)。