XiaoMi-AI文件搜索系统
World File Search Systemxgboost

改善季节性influenza-forecasting-使用时间...
流感是一种高度传染性的呼吸道疾病,仍然对世界各地的公共卫生构成严重威胁。预测技术有助于监测季节性流感和其他类似流感的疾病,以及适当地管理资源以制定疫苗接种策略,并选择适当的公共卫生措施以减少疾病的影响。这项调查的目的是预测使用XGBoost模型在2020年和2021年的沙特阿拉伯每月发病率,并将其与Arima和Sarima模型进行比较。结果表明,与Arima和Sarima模型相比,XGBoost模型具有最低的MAE,MAE和RMSE,并且R-squared(R²)的最高值。本研究将XGBOOST模型与Arima和Sarima模型的准确性进行了比较,以提供每月季节性流感病例数量的预测。这些结果证实了以下概念:XGBoost模型的预测准确性高于Arima和Sarima模型,这主要是由于其捕获复杂的非线性关系的能力。因此,XGBoost模型可以预测沙特阿拉伯季节性流感病例的每月发生。

s3图。如VPA,LI2CO3和Tranilast的处理可减少DNA双链断裂,如! H2AX,但不恢复HMGB-1水平。 (a)
我们的结果与以前的研究一致,这些研究证明了基于树模型,尤其是随机森林和Xgboost在预测糖尿病杂志方面的有效性[12]。Alam等人的研究。报道说,随机森林和XGBoost在DR预测中实现了很高的AUC值和准确性,强调了这些模型在分析复杂的医疗保健数据中的实用性[13]。此外,最近的工作强调了XGBoost基于生化和成像数据准确预测DR风险的潜力,进一步验证了我们的发现[14-16]。在处理大数据集中随机森林的高预测能力和鲁棒性是有据可查的,我们的发现与这些观察结果保持一致,这表明随机森林可能是DR筛查的最佳选择[17]。Xgboost也表现良好,具有与随机森林相当的AUC值,表现出强大的分类能力并有效地处理可变重要性[15]。这些发现突出了在早期检测至关重要的医疗保健应用中基于树模型的实用性[18,19]。

使用间接太阳能烘干机对香蕉切片的干燥参数进行预后分析的高级机器学习开发
在这项研究中,使用了极端梯度提升(XGBoost)和光梯度提升(LightGBM)al-gorithms用间接太阳能干燥机的香蕉切片的干燥特性进行模型。建立了自变量(温度,水分,产品类型,水流量和产品质量)与因变量(能源消耗和降低)之间的关系。用于耗能,XGBoost在训练过程中以0.9957的r 2为0.9957,在测试过程中表现出优异的表现,在训练期间的最小MSE为0.0034,在训练期间为0.0008,在测试阶段表明高预测性获得率和低错误率。相反,LGBM显示较低的R 2值(0.9061训练,0.8809测试)和较高的MSE在训练过程中的MSE为0.0747,在测试过程中0.0337显示了0.0337,反映了较差的表现。同样,对于收缩预测,XGBOOST优于LGBM,较高的R 2(0.9887训练,0.9975测试)和较低的MSE(0.2527培训,0.4878测试)证明了LGBM。统计数据表明,XGBoost定期胜过LightGBM。基于游戏理论的Shapley功能表明,温度和产品类型是能源消耗模型的最具影响力的特征。这些发现说明了XGBoost和LightGBM模型在食品干燥操作中的实际适用性,以优化干燥调节,提高产品质量并降低能耗。
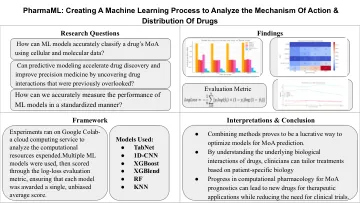
PharmAML:创建一个机器学习过程来分析动作机理&
●随机森林:一种合奏学习算法,该算法构建了多个决策树并结合了输出以提高准确性并减少过度效果。●XGBoost:像随机森林一样,XGBoost是一种集合学习算法,但它使用梯度提升来依次构建决策树,在每个步骤上纠正错误,以提高准确性和效率。●KNN:一种基于实例的学习算法,该算法基于其K最近的K最近邻居的多数类或通过平均值来预测值。●XGBlend:我们创建的XGBoost模型!将标准神经网络与XGBoost体系结构相结合,以提高算法处理的速度。●1D-CNN:使用卷积层将每一行视为1D序列的卷积神经网络,以捕获特征相互作用并提取图案,以提高预测性能。●TABNET:专为表格数据而设计的深度学习模型,利用注意机制动态选择相关特征,从而实现可解释性和有效的学习。

校正:免疫检查点抑制剂相关的甲状腺...
一般而言,LightGBM,Xgboost,随机森林和逐步增强模型的表现优于内部阀门。同时,采用LightGBM(0.96),XGBoost(0.92)和随机森林(0.92)的模型,较高的AUC值。关于灵敏度,逻辑回归(0.64)和LightGBM(0.57)模型的性能更好。虽然,KNN,随机森林,SVM和梯度增强模型达到了特异性和正面值1。此外,LightGBM(0.90),决策树(0.88)和逻辑回归(0.88)模型表现出更高的负预测值。使用LightGBM,XGBoost和随机森林组合歧视和校准,Brier得分分别为0.07、0.10和0.10(表3,图3,图。4,图S18 – S19)。

引用:李W,Song Y,Chen K等。使用机器学习的糖尿病性视网膜病变的预测模型和风险分析:回顾性队列
抽象目标旨在通过使用大型样本数据集进行机器学习来研究糖尿病性视网膜病(DR)风险因素和预测模型。基于大型样本和高维数据库的设计回顾性研究。在北京设立中国中央三级医院。参与者有关32 452型糖尿病(T2DM)住院患者的信息从2013年1月1日至2017年12月31日从电子病历系统中检索方法保留了六十个变量(包括人口统计信息,物理和实验室测量,系统疾病和胰岛素治疗)进行基线分析。通过递归特征消除选择了最佳17变量。预测模型是基于XGBoost算法构建的,并与其他三种流行的机器学习技术进行了比较:逻辑回归,随机森林和支持向量机。为了更视觉上解释XGBoost模型的结果,使用了Shapley添加说明(SHAP)方法。结果DR发生在2038年(6.28%)T2DM患者中。XGBoost模型被确定为具有最高AUC的最佳预测模型(曲线值为0.90),表明HBA1C值大于8%,肾病,血清肌酐值大于100 µmol/L,胰岛素治疗和糖尿病下极端疾病的风险与DR的风险增加相关。患者的年龄超过65岁,与DR的风险降低有关。结论具有更好的全面性能,XGBoost模型具有很高的可靠性来评估DR的风险指标。可以通过Shap方法找到DR的最关键危险因素和危险因素的临界因素,以使XGBoost模型的输出在临床上可以解释。

沃尔玛使用机器的销售预测...
摘要:销售预测对于当今的企业至关重要,因为它是改善它的关键因素。“销售预测”是一个人使用不同技术来预测即将到来的几周,几个月或几年的销售的过程。在本研究论文中,文献综述是关于不同研究人员应用的机器学习算法来预测沃尔玛的销售。不同的算法研究人员使用的是神经网络,OLS回归,XGBoost,SVM,Lasso回归,随机森林,额外的树回归,KNN和线性回归。从应用的所有算法中,额外的树回归表现良好,精度为98.20%。最后,我们比较了沃尔玛销售的随机森林,额外的树回归,XGBoost算法和KNN回归模型。Xgboost在其中排名最高,最高准确性为98.24%。这项研究证明了在这一销售预测领域中机器学习的潜力,并开辟了广泛的未来研究范围,以提高准确性。


使用Twitter情感分析
摘要 - 经济,政治和社会因素使股票价格预测具有挑战性且无法预测。本文着重于为股票价格预测开发人工智能(AI)模型。该模型利用了三个领域的LSTM和XGBoost技术:Apple,Google和Tesla。它旨在检测将情绪分析与历史数据相结合的影响,以了解人们的意见可以改变股票市场。提出的模型使用自然语言处理(NLP)技术计算情感分数,并根据日期将它们与历史数据结合在一起。RMSE,R²和MAE指标用于评估所提出模型的性能。与单独的历史数据相比,情感数据的整合已显示出显着的改善,并获得了更高的准确率。这提高了模型的准确性,并为投资者和金融部门提供了有价值的信息和见解。Xgboost和LSTM证明了它们在股票价格预测中的有效性; XGBoost优于LSTM技术。

通过对机器学习模型的比较分析改善心血管疾病预测:
摘要:心血管疾病仍然是当代世界中死亡率的主要原因。它与吸烟,血压升高和胆固醇水平的关联强调了这些危险因素的重要性。本研究解决了预测心肌疾病的挑战,这是医学研究中的一项艰巨任务。准确的预测是精炼医疗策略的关键。这项调查对六个不同的机器学习模型进行了比较分析:逻辑回归,支持向量机,决策树,包装,XGBoost和LightGBM。所达到的结果表现出希望,准确率如下:逻辑回归(81.00%),支持向量机(75.01%),XGBoost(92.72%),LightGBM(90.60%)(90.60%),决策树(82.30%)和装袋(83.01%)。值得注意的是,XGBoost作为表现最佳模型出现。这些发现强调了其增强冠状动脉梗塞预测精度的潜力。随着心血管危险因素的普遍性持续存在,结合了先进的机器学习技术,具有优化积极主动的医疗干预措施的潜力。