XiaoMi-AI文件搜索系统
World File Search System个流
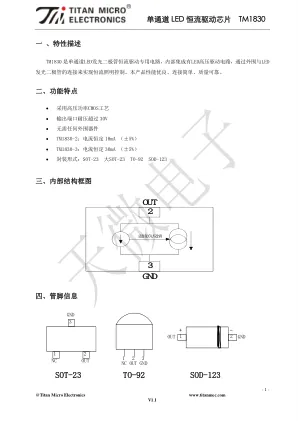
单通道LED 恒流驱动芯片TM1830
如图1 所示,要使TM1830 工作在恒流状态下,芯片OUT 引脚上电压应大于2.2V,即芯片的2、3 脚之间的电压应达到2.2V 以上。在应用时,电源串接LED 灯后加在OUT 引脚上的电压建议在3.0V 左右。 如果芯片持续工作在额定恒流状态下,TM1830-2 和TM1830-3 的OUT 引脚电压应分别在12.0V 和8.0V 以内为宜。
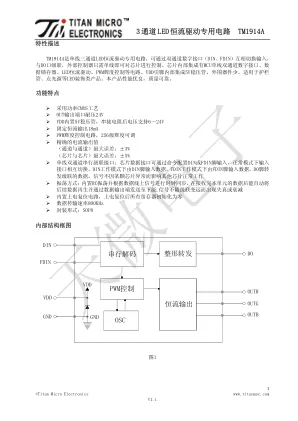
3通道LED恒流驱动专用电路TM1914A
功能说明 1、模式设置 本芯片为单线双通道通讯,采用归一码的方式发送信号。芯片接收显示数据前需要配置正确的工作 模式,选择接收显示数据的方式。模式设置命令共48bit,其中前24bit为命令码,后24bit为检验反码, 芯片复位开始接收数据,模式设置命令共有如下3种: (1)0xFFFFFF_000000命令: 芯片配置为正常工作模式。在此模式下,首次默认DIN接收显示数据,芯片检测到该端口有信号输 入则一直保持该端口接收,如果超过300ms未接收到数据,则切换到FDIN接收显示数据,芯片检测到该 端口有信号输入则一直保持该端口接收,如果超过300ms未接收到数据,则再次切换到DIN接收显示数据。 DIN和FDIN依此循环切换,接收显示数据。 (2)0xFFFFFA_000005命令: 芯片配置为DIN工作模式。在此模式下,芯片只接收DIN端输入的显示数据,FDIN端数据无效。 (3)0xFFFFF5_00000A命令: 芯片配置为FDIN工作模式。在此模式下,芯片只接收FDIN端输入的显示数据,DIN端数据无效。 2、显示数据

WS9032G 非隔离降压型LED 恒流驱动芯片 - NET
X-ON Electronics Largest Supplier of Electrical and Electronic Components Click to view similar products for LED Display Drivers category: Click to view products by Winsemi manufacturer: Other Similar products are found below :

WS9056X 非隔离降压型LED 恒流驱动芯片 - NET
X-ON Electronics 最大的电气和电子元件供应商 点击查看 LED 显示驱动器类别的类似产品: 点击查看 Winsemi 制造商的产品: 其他 类似产品如下:

滑流
首先,我必须感谢受邀为“滑流”做出贡献。作为一名非飞行员,我很荣幸有机会与我们海军舰队航空兵的(前任和现任)成员进行交流。距离“澳大利亚皇家海军”(RAN)这个新国家被授予英联邦海军部队已有近 100 年。在过去的这些年里,无论是在和平时期还是在战争时期,RAN 都多次应邀前往我们的国家。每次我们都做好准备,为我们有充分理由自豪地享受的持续自由和民主做出重大贡献。2014 年,在我们参加第一次冲突一百周年之际,我相信 RAN 将处于能力的分水岭时刻。五年后,海军将投入使用两级战舰,为澳大利亚国防军提供显著增强甚至全新的能力。从 2014 年开始,我相信澳大利亚皇家海军将在几十年来首次实现真正平衡的兵力结构和先进的作战能力——可以说是自我们成立以来首次。海军将在 2014 年迎来三艘霍巴特级 7,000 吨级宙斯盾防空驱逐舰中的第一艘。此外,27,000 吨级两栖舰(直升机登陆舰 - LHD)HMAS CANBERRA 将于同年交付。每个级别的战舰都将为澳大利亚国防军提供一套能力,这将大大增强我们在联合任务组环境中有效作战的能力。在霍巴特级中,我们将能够大大拓宽我们在区域空战中的视野,并引入令人印象深刻的指挥和控制 (C2) 能力以及先进的水面、水下和打击系统。堪培拉级将标志着澳大利亚持续两栖或远征作战能力的出现。引入海上联合 C2 能力、用于船岸“连接器”的可淹没对接以及用于多飞机作战的令人印象深刻的航空设施将带来挑战和显著优势。凭借升级后的 COLLINS 级潜艇、新型多船员 ARMIDALE 级巡逻艇、HUON 级扫雷艇和扫雷潜水队、补给舰、大大增强的 ANZAC 级护卫舰、不断发展的海洋科学部队,当然还有我们的舰队航空兵,澳大利亚皇家海军将同时拥有超越以往任何时候的广度和深度。澳大利亚将拥有新一代海军 (NGN)。五年内有很多事情要做,我期待您的支持和贡献,以充分实现我们的 NGN。我们有很多值得兴奋的事情。问候 S. R. GILMORE 海军少将,RAN


