XiaoMi-AI文件搜索系统
World File Search System中文

获得中文作为第一语言和第二语言
过去二十年来,人们见证了将中文作为第二语言(L2中文)的兴趣激增。兴趣在多个方面都反映在包括教育,中文课程入学,学生体内复合材料和学习动机。中文课程和课程已经兴起,尤其是为了回应大学董事会的决定,即提前安置(AP)中文和文化考试将于2006年在美国实施。中文教育在许多美国学校都迅速制度化;例如,从2004年到2008年,在K-12美国公立学校中,汉语课程的入学率增加了195%(ACTFL 2011)。除了对中文兴趣的总体增长外,中文学习者种族背景的多样性也扩展了。二十多年前,L2学习者主要是高加索人。相比之下,最近的一项大规模调查发现,高加索人现在仅占学生团体的51%(Li等人2014)。中国遗产学生和来自亚裔美国人背景的学生占30%以上,来自拉丁美洲和非裔美国人背景的学生又占16%。遗产学习者中的一个特征是他们的语言背景和经验。以及学生团体的这些重大变化,学习中文的学习目标也在不断发展。与中国教育的迅速发展相反,对中文作为第一的研究以及其他语言的研究落后了。传统的目标,例如要上学和成为官方学家,已被语言的功能和工具使用以及中国文化和语言的能力取代(Comanaru and Noels 2009; Sung 2013; sung 2013; xie 2014; Xie 2014; Wen 2011; Wen and Piao 2020)。在回顾有关中文动机文献的当前状态时,WEN(2018)仅在详尽的搜索后才找到有关该主题的16项实证研究。自六十年前成立以来,只有五个中文教师协会(CLTA)专着就出版了。近年来,L2中国书籍实证研究的发展有了更多的发展(Everson and Shen 2010; Han 2014; Tao 2016; Wen 2012; Wen and Jiang 2019)和期刊。这些书和期刊中的文章提出了更严格的研究方法和更广泛的询问范围。然而,对汉语获取的研究,尤其是实证研究,是稀疏的,并且是一般语言习得的研究发展背后的滞后。缺乏对汉语获取的研究直接影响中文教学,这是一种障碍的缺乏效率,使学习并忽略了学生。需要在当前的研究发现中更新教师,以便进行有效的教学。什么决定课堂教学质量的是基于研究的学习者和学习过程的知识。知识渊博的讲师能够为学生选择适当的教学方法和教学条件。作者多归功于语言,这是一本主要的同行评审期刊,具有了解中文获取的急性要求要求对广泛的主题进行更多的实证研究,以审查中文学习和学习过程的本质。

制定隐形评估以评估年轻中文...
本研究探讨了在数字游戏中使用隐形评估来评估第二语言(L2)中国学习者的阅读理解。日志数据跟踪学习者的游戏内行为是为中文双语言浸入教室设计的游戏(Poole等,2022),用于构建贝叶斯信仰网络以建模阅读理解。变量包括在单词查找中使用内词汇表,阅读文本花费的时间,词汇知识,文本长度,响应要求以及重复的数量。网络首先是使用类级游戏数据构建的,然后是应用于单个学生的。结果表明,学生的建模理解力与他们在外部阅读理解评估(r = .52)以及教师的非正式阅读评估(r = .66)之间的表现之间存在显着相关性,这表明隐形评估对不可思议的阅读理解测量的潜力。这些发现有助于对语言教育中基于数字游戏的学习和评估的理解,尤其是在阅读《普通话中文》(如普通话)中的非字母语言理解的背景下。
![[中文] 2024年数据科学学院年度报告.pdf](/simg/e\e3cc0b78546a9814bc55bacd3a5acbe18542bdc1.webp)
[中文] 2024年数据科学学院年度报告.pdf
研究领域和重点概述 ........................................................................................................... 15 聯合實驗室建設情況 ........................................................................................................... 16 邀請演講、主題演講和會議參與 ....................................................................................... 17 教師發展與成就 ................................................................................................................. 21

基于人工智能的中文教学的个性化策略的研究
版权所有©2024作者和Frontier Scientific Research Publishing Inc.这项工作是根据创意共享归因国际许可证(CC by 4.0)获得许可的。http://creativecommons.org/licenses/4.0/

1(3)个人详细信息和简历的日期•刘,杨(中文...
出生年份:1952年出生地点:美国公民婚姻状况:已婚(性别:男性)家庭住址:141 Erica Way,Portola Valley,CA 94028电话(650)714-7005替代电话(650)854-9114-9114教育和就业记录(当前的教育和就业记录)微生物学1970-74爱荷华州爱荷华州,爱荷华州博士微生物学1974 - 79年USPHS细胞和分子生物学领域的学期学会1975 - 78年芝加哥大学,芝加哥,伊利诺伊州芝加哥大学,伊利诺伊州博士后1979-83 USPHS病毒学博士学生学员1979-81 1979 - 81 Professor of Microbiology & Immunology 1983-89 Associate Professor of Microbiology & Immunology 1989-95 Chairman of the Department of Microbiology & Immunology 1995-99 Professor of Microbiology & Immunology 1995-06 Professor Emeritus 5/2006 Stanford University, Stanford, California Associate Dean of Research 2000-01 Emory University, Atlanta Georgia Robert W.伍德拉夫微生物学和免疫学教授2006-2021埃默里疫苗中心2006-2021名誉教授1/2022专业休假:Systemix,Palo Alto,California,California,1990年(6 Mo。)Aviron,山景,加利福尼亚,1995年(6个月)medimmune-astrazeneca杰出研究员11/2008-1/2011

理性行动理论背景下的中文房间论证
大约四十年前(1980 年),美国哲学家约翰·塞尔在他的论文《思想、大脑和程序》(Searle:1980)中发表了他对他所谓的强人工智能(人工智能)论题的著名驳斥,塞尔声称“经过适当编程的计算机确实具有认知状态,程序因此可以解释人类认知”(Searle:1980,417)。正如他所写,塞尔的论文的直接收件人是 R. Shank 和 R. Abelson 的研究(Shank,Abelson:1977,248),他们的作者声称他们设法创建了一个能够理解人类故事含义的计算机程序。例如,关于一个故事:“一个人去一家餐馆点了一个汉堡包;当汉堡包送来时发现它被烧焦了,这个人愤愤不平地离开了餐馆,没有付钱。”问题是:“他吃了汉堡包吗?”“适当”编程的计算机回答很可能没有。在他的文章中,Searle 既没有分析 Shank 和 Abelson 使用的测试计算机的程序,也没有分析他们程序的运行原理。他提出了一个问题,当计算机没有相应的视觉、嗅觉和味觉体验时,是否可能谈论理解,因为计算机无法知道“汉堡包”、“烧焦”等词的含义。正如 Searle 所相信的,Shank 和 Abelson 进行的人工智能研究遵循了 A. Turing 众所周知的测试范式,根据该测试,计算机对“人类答案”的令人满意的模仿与人的合理答案相似。在图灵测试中,扮演专家角色的人以硬拷贝格式提出问题,并以同样的方式从两个他看不见的对话者那里得到答案,其中一个是人,另一个是专门编程的计算机。根据图灵的说法,令人满意地通过测试的标准是,专家在五分钟的调查后,在不超过 70% 的情况下识别出计算机(图灵:1950,441),图灵认为这可以相信计算机具有思考能力。

中文剩余定理的文本编码对点椭圆曲线密码
这个数字时代最关键的要求之一是数据安全。现在几天的数据使用次数急剧增加,但是确保数据是非常大的问题,尽管我们有足够的加密算法来确保实时应用程序,但是尚未确定针对现代攻击的安全性水平。基于椭圆曲线的加密术(ECC)是机密性和身份验证的最重要的加密算法,与其他不对称算法(如RSA,Diffie-Hellman等)相比,用较小的长度键提供了较高的安全水平。由于计算复杂性,ECC的实时系统使用量很小。因此,为了增加实时系统的使用情况,我们提出了将ECC与中国剩余定理(CRT)相结合的新方法,以将较大的值降低到较小的值,以便与现有的基于ECC的算法相比,构建ECC点的复杂性可以降低接近40%。此外,它证明了安全级别的提高,可以用作实时通信系统中的基本组件。
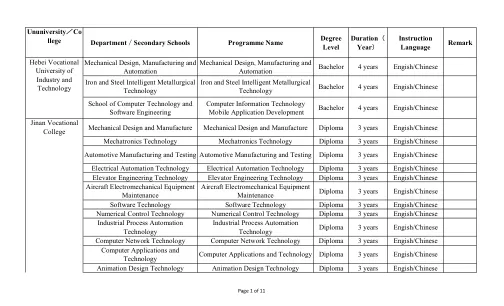
中国学院专业列表-2023.pdf
大数据技术 大数据技术文凭 3年 英语/中文 畜牧兽医 畜牧兽医文凭 3年 英语/中文 兽医 兽医文凭 3年 英语/中文 生物制药技术 生物制药技术文凭 3年 英语/中文 食品检验与检测技术食品检验与检测技术文凭 3年 英语/中文 宠物护理与训练 宠物护理与训练文凭 3年 英语/中文 园艺 园艺文凭 3年 英语/中文 水产养殖技术 水产养殖技术文凭 3年 英语/中文 电子商务 电子商务文凭 3年 英语/中文 计算机应用技术 计算机应用技术文凭 3年 英语/中文 现代农业应用技术

ChineseEEG:用于语义对齐和神经解码的中文语言语料库脑电图数据集
利用富文本刺激的脑电图 (EEG) 数据集可以促进对大脑如何编码语义信息的理解,并有助于脑机接口 (BCI) 中的语义解码。针对包含中文语言刺激的 EEG 数据集稀缺的问题,我们提出了 ChineseEEG 数据集,这是一个高密度 EEG 数据集,并辅以同步眼动追踪记录。该数据集是在 10 名参与者默读两部著名小说中约 13 小时的中文文本时编制的。该数据集提供长时间的 EEG 记录,以及预处理的 EEG 传感器级数据和由预训练的自然语言处理 (NLP) 模型提取的阅读材料的语义嵌入。作为源自自然中文语言刺激的试点 EEG 数据集,ChineseEEG 可以显著支持神经科学、NLP 和语言学的研究。为中文语义解码建立了基准数据集,有助于脑机接口的发展,并有助于探索大型语言模型与人类认知过程的契合。它还可以帮助研究中文自然语言背景下的大脑语言处理机制。
