XiaoMi-AI文件搜索系统
World File Search System于表

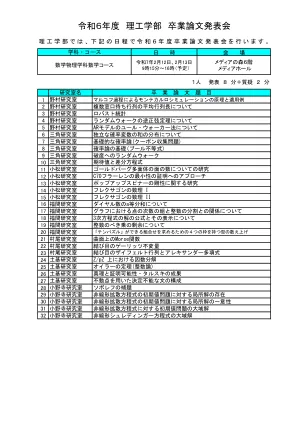
2024科学与工程学院毕业论文介绍
实验室名称1富士实验室2山摩托实验室3山原实验室4萨萨哈拉实验室5木马实验室6 Murata实验室7 Murata实验室8 Kawabata Laboratory 9 Kawabata实验室9 Okubo实验室10 Shibuo Laboratory 10 Shibuo实验室实验室11 Matsuoka Laboratory 12 Yamada Laboratory 13 YAMADA Laboratory 14 Okub sheratory 14 Okuubi fujiuchi 14 o实验室18 SASA实验室19 Shibuo实验室20 Noguchi实验室21 Fujiuchi Laboratory 22 Kawabata Laboratory 23 SASA实验室23 SASA实验室24 Noguchi Laboratory 25 Shibuo实验室25 Shibuo实验室26 IWAI实验室27 SASA实验室27 Sasa Laboratory 28 Kawabata Labotoration 28 Kawabata实验室29 Haseguchi Laguchi Laguchi Laboratory 30 Noguchi Laboratory 31 Noguchi Laboration 31 31 Murata实验室32 Fujiuchi实验室33 Yamada Laboratory 34 Fujiuchi Laboratory 35 Sakamoto Laboratory 36 SASA实验室37 Hasegawa Laboratory 38 Hasegawa Laboratory

优秀発表赏エントリー演题
(1个农业和生命科学研究生院,东京大学)[目的]近年来,由于人们担心能源和食物自给自足的减少以及全球变暖,进口资源的兴起以及Yen的弱点,可持续生物量作物引起了人们的关注。生物量作物不仅用作生物产品的原材料,而且还用作饲料。在这项研究中,使用基因组编辑技术生产了“非盛大的大米”,其用途是通过测量其户外培养,生物量和可溶性糖和淀粉含量来评估作为生物质和饲料作物的。 [材料和方法]具有栽培的水稻品种“ koshihikari”,这是一种双突变体(去除异国基因),florogen基因和㻴ニ㻟ニックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロックロック这种突变抑制了开花,但是通过自我产生异态性的个体,突变体系统得以维持。此外,使用该双重突变体在背景中,使用一种技术在茎和茎中涉及糖和淀粉代谢的技术创建了参与茎和叶中糖和淀粉代谢的基因的突变。在户外培养这些基因组编辑系统时,他们已提前向教育,文化,体育,科学和技术咨询,并提交了一项实验计划,以便接受它们。每个突变体的收获分为黄色成熟期(从㻟㻜㻜㻠㻜㻜㻜㻜㻜㻜㻜㻜です),这是普通饲料水稻品种的收获期,黄色成熟期后约几周。除了测量收获个体的干重外,还从代表性的分er中测量了每个器官中可溶性糖和淀粉的浓度,并估计每个器官的产量。此外,测量了整个收获个体的可溶性糖和淀粉的浓度,并计算每个个体的可溶性糖和淀粉的重量。 [结果和讨论]收集了每个菌株(゚㻩ン),并测量其干重,结果表明,在黄色成熟期间收获的koshihikari是㻟㻜±㻤㻌ランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドラ㻤㻌ランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドラ㻟㻜±㻤㻌ランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドランドラ-riptherore,黄色成熟期后收获的干重是㻣㻣±㻝㻌ラック㻝㻌ラック±㻝㻌ラック,并且对非透性突变剂的生物量显着增加。此外,根据代表性耕种器的每个器官的可溶性糖浓度计算估计的产率,结果表明,Koshihikari大约是㻜㻚㻠㻛ロックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセックセック的,另一方面,估计的淀粉产量大约是㻞㻚㻞㻌㻌㻌㻠ラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドラインドライン进一步,目前正在测量每个菌株的溶剂糖和淀粉的重量。此外,我们将报道在不开放的菌株中涉及糖和淀粉代谢的基因中引入突变的菌株的分析结果。以上结果表明,非灌木菌株中生物量显着增加,茎和叶片中可溶性糖和淀粉的显着积累,表明不明显的koshihikari大米植物作为高生物量的水稻品种的有用性。此外,它被认为是饲料稻的非常有用的,因为它在喂养牛时不包含高度未消除的稻田。此外,为了实施“脸红的大米”血统,该公司还致力于开发技术,以选择不以种子表型为指标从单独群体中开花的个人。

2025年度日本人工智能学会全国大会(第39届)◆提交您的演讲稿(...
● 第一类:国际会议 1(在研) 论文为相关领域指定的人工智能及相关领域的学术论文、病例报告类英文论文、英文演讲。 “正在进行的工作”类别提供了展示、接受反馈以及讨论仍处于探索阶段的新想法或研究的机会。该类别的论文应准备扩展摘要(遵循国家会议网站指定的格式的 1-2 页 PDF 文件)。申请发表时,请选择您的论文所属领域,并指定描述论文内容的关键字。这适用于下述纸质字段中的 E-1 至 E-5。请在作者信息下方的摘要部分中包含 1) 目标和 2) 结果或结论的概述。如有必要,请在摘要中包括方法论的要点。摘要中不包含上述①和②项或不遵循论文格式的投稿可能会被拒绝。 ● 第 2 类:国际会议 2(常规)论文为相关领域指定的人工智能及相关领域的学术论文、病例报告类英文论文、英文演讲。常规类别提供了展示未发表研究成果的机会。此类论文请按照国家会议网站指定的格式,创建 2 至 8 页的 PDF 文件。申请发表时,请选择您的论文所属领域,并指定描述论文内容的关键字。这适用于下述纸质字段中的 E-1 至 E-5。在作者信息下方的摘要部分中,请包括 1) 目标和 2) 结果或结论的摘要。如有必要,请在摘要中包括方法论的要点。摘要中不包含上述①和②项或不遵循论文格式的投稿可能会被拒绝。此外,在提交给常规类别的论文中,我们将鼓励那些被认为与本次会议特别相关且优秀的论文提交到扩展的新一代计算期刊的特刊。 ● 第 3 类:综合会议定期举办与论文相关的人工智能及相关领域的学术论文和案例报告。申请发表时,请选择您的论文所属领域,并指定描述论文内容的关键字。这适用于下述纸质领域的J-1至J-11。 在作者信息下方的摘要部分中,请包括 1) 目标和 2) 结果或结论的摘要。如有需要,请提供方法。摘要中不包含上述①和②项或不遵循论文格式的投稿可能会被拒绝。
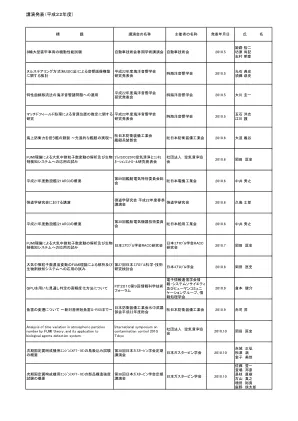
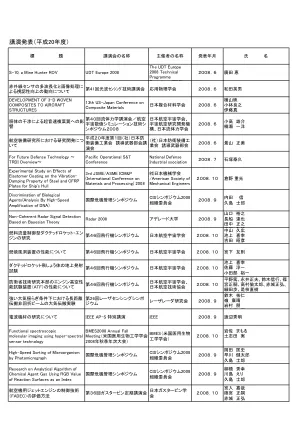
讲座 (2008) - 防卫省/自卫队
利用 TOF-MS 检测微生物 国际危机管理研讨会 CIS 研讨会组织委员会 2008.9 Naohiro Muronoi Hideyuki Hayashi Shiro Kushima 使用 RGB 值自动识别化学剂的变色反应 国际危机管理研讨会 CIS 研讨会组织委员会 2008.9 Eri Kawashima Hideyuki Yanagibashi串岛四郎
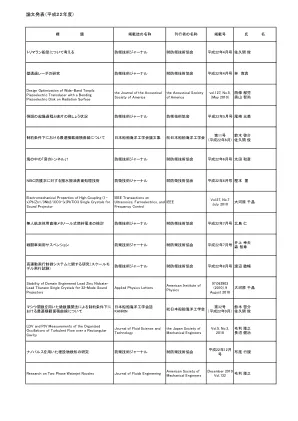

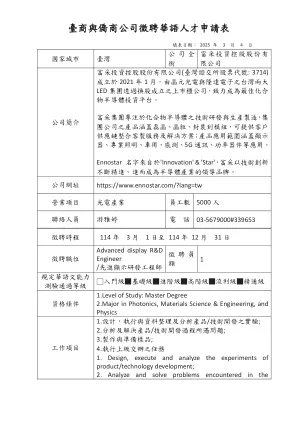
台商与侨商公司征聘华语人才申请表
3。负责新产品制程的导入,并进行制程的检测定期检测制程设备的重点参数。5。持续改善现有生产制程。6。调查并处理生产制程的异常状况。7。负责技术文件之撰写与维护。8。负责每日产量及良率的分析、监控及改善。9。推行生产制程的相关教育训练计划。1。制定制造程序和产品标准。2。评估过程项目计划并制定最合适的制造过程。3。负责引入新产品制造过程和过程测试,以便可以稳定生产新产品并符合相关标准。4。定期测试过程设备的关键参数。5。不断改善现有的生产过程。6。在生产过程中调查并处理异常条件。7。负责撰写和维护技术文档。8。负责分析,监视和改善每日产量和产量。9。实施与生产过程有关的教育和培训计划。
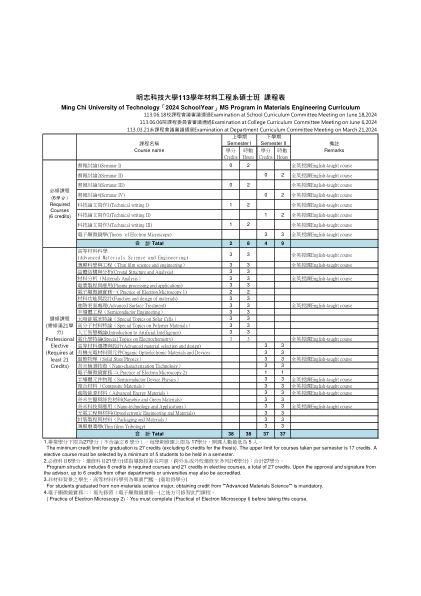
明志科技大学113学年材料工程系硕士班课程表
薄膜科学与工程(薄膜科学与工程) 3 3 全英授课 晶体结构与分析(晶体结构与分析) 3 3 材料分析(材料分析) 3 3 全英授课 电浆制造工艺与应用(等离子体加工与应用) 3 3 电子显微镜实务一(电子显微镜实践1) 2 2 材料功能与设计(电子显微镜的功能与设计)材料) 3 3 进阶表面处理(Advanced Surface Treatment) 3 3 全英授课半导体工程(Semiconductor Engineering) 3 3 太阳能电池特论(Special Topics on Solar Cells) 3 3 高分子材料特论(Special Topics on Polymer Materials) 3 3 人工智慧概论(Introduction to Artificial Intelligence) 3 3 电化学特论(Special Topics on Electrochemistry) 3 3 全英授课英语授课课程《高等材料选择与设计》(Advanced Material Selection and Design) 3 3 有机光电材料与元件有机光电材料与器件 3 3 固体物理(Solid StatePhysics) 3 3 全英授课英语授课课程奈米检测技术(Nano-writing Technology) 3 3 电子实验室实务二(Practice of Electron Microscopy) 2) 1 1 半导体元件物理(Semiconductor Device Chemistry) 3 3 全英授课 复合材料(Composite Materials) 3 3 全英授课 进阶能源物理材料(Advanced Energy Materials) 3 3 全英授课 奈米生医与绿色材料(纳米与绿色材料) 3 3 奈米科技与应用(纳米技术与应用) 3 3 全英授课 光电工程与材料(光电工程与材料) 3 3 封装工艺与材料(包装与材料) 3 3 薄膜磨润学(薄膜摩擦学) 3 3