XiaoMi-AI文件搜索系统
World File Search System交叉验证

基于调查的人工智能在传染病管理临床决策支持中的开发和应用:对越南中部一家医院的一项试点研究
方法:我们选择了越南中部地区疾病负担较重的七种传染病类别:蚊媒疾病、急性胃肠炎、呼吸道感染、肺结核、败血症、原发性神经系统感染和病毒性肝炎。我们开发了一套问卷,收集疑似传染病患者的当前症状和病史信息。我们使用从 1,129 名患者收集的数据来开发和测试诊断模型。我们使用 XGBoost、LightGBM 和 CatBoost 算法来创建用于临床决策支持的人工智能。我们使用 4 倍交叉验证方法来验证人工智能模型。经过 4 倍交叉验证后,我们在单独的测试数据集上测试了人工智能模型,并估计了每个模型的诊断准确性。

基于调查的人工智能在传染病管理临床决策支持中的开发和应用:对越南中部一家医院的一项试点研究
方法:我们选择了越南中部地区疾病负担较重的七种传染病类别:蚊媒疾病、急性胃肠炎、呼吸道感染、肺结核、败血症、原发性神经系统感染和病毒性肝炎。我们开发了一套问卷,收集疑似传染病患者的当前症状和病史信息。我们使用从 1,129 名患者收集的数据来开发和测试诊断模型。我们使用 XGBoost、LightGBM 和 CatBoost 算法来创建用于临床决策支持的人工智能。我们使用 4 倍交叉验证方法来验证人工智能模型。经过 4 倍交叉验证后,我们在单独的测试数据集上测试了人工智能模型,并估计了每个模型的诊断准确性。
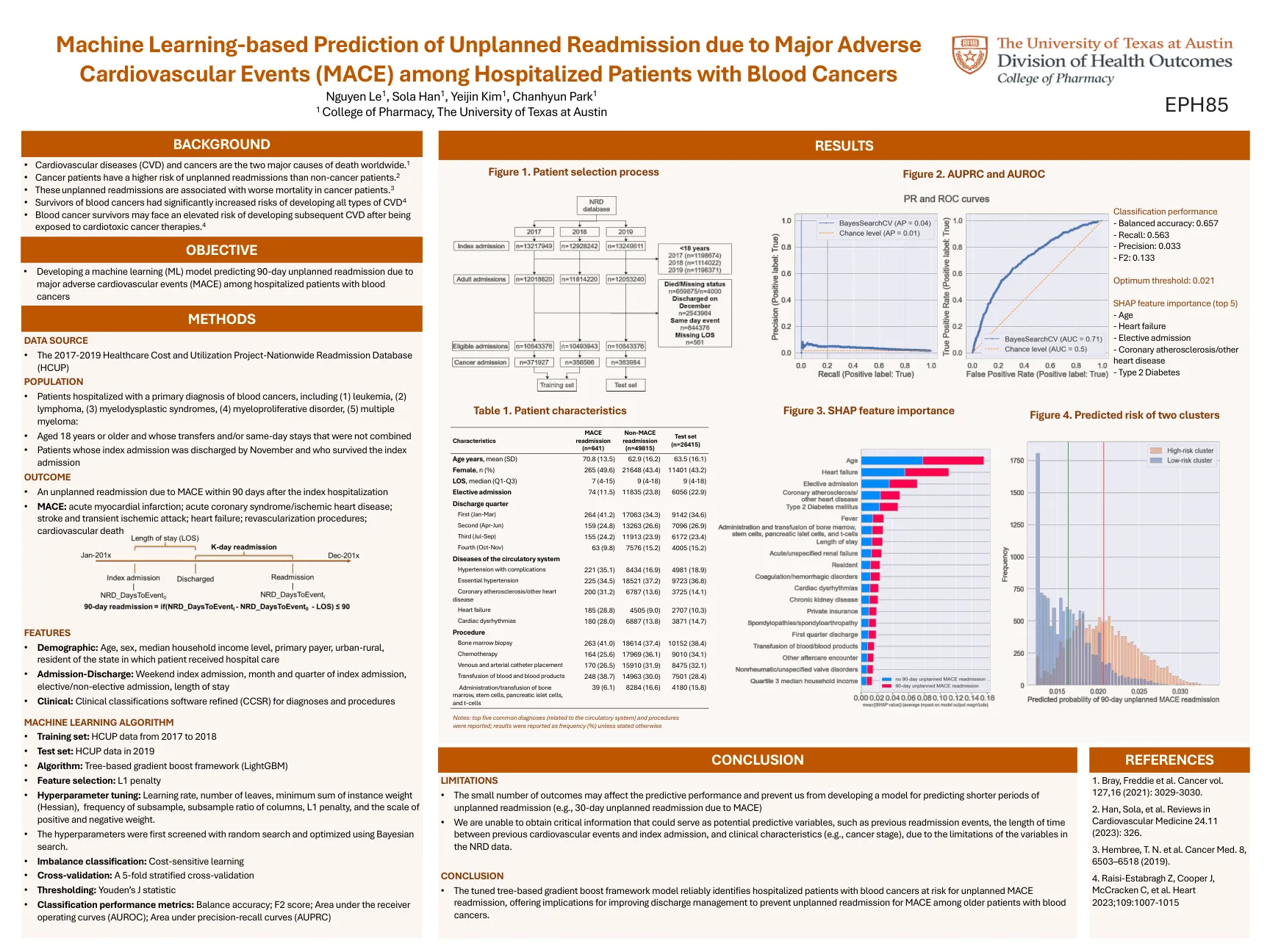
基于机器学习的预测未计划的重新入学,这是由于主要不利
MACHINE LEARNING ALGORITHM • Training set: HCUP data from 2017 to 2018 • Test set: HCUP data in 2019 • Algorithm: Tree-based gradient boost framework (LightGBM) • Feature selection: L1 penalty • Hyperparameter tuning: Learning rate, number of leaves, minimum sum of instance weight (Hessian), frequency of subsample, subsample ratio of columns, L1 penalty, and the scale of positive and negative weight.•首先对超参数进行筛选,并使用贝叶斯搜索进行优化。•不平衡分类:成本敏感的学习•交叉验证:5倍分层的交叉验证•阈值:Youden的J统计量•分类性能指标:平衡精度; F2分数;接收器操作曲线(AUROC)下方; Precision-Recall曲线(AUPRC)下的区域

大脑通讯 AIN 通讯
帕金森病的早期和准确鉴别诊断仍然是临床医生面临的重大挑战。近年来,许多研究利用磁共振成像数据结合机器学习和统计分类器成功区分了不同形式的帕金森病。然而,为了尽量减少偏差和伪影驱动的分类,仍存在一些问题和方法问题。在本研究中,我们比较了不同的特征选择方法和不同的磁共振成像模式,并匹配良好的患者组,并严格控制与患者运动相关的数据质量问题。我们的样本来自 69 名健康对照者,以及特发性帕金森病 (n = 35)、进行性核上性麻痹理查森综合征 (n = 52) 和皮层基底节综合征 (n = 36) 患者。参与者接受了标准化 T1 加权和弥散加权磁共振成像。严格的数据质量控制和组匹配将对照组和患者组的数量分别减少到43、32、33 和 26。我们比较了两种不同的特征选择和降维方法:全脑主成分分析和基于解剖感兴趣区域的方法。在这两种情况下,支持向量机都用于构建健康对照组和患者的成对分类的统计模型。使用留二交叉验证方法以及使用不同受试者集的独立验证来估计每个模型的准确度。我们的交叉验证结果表明,与基于感兴趣区域的方法相比,使用主成分分析进行特征提取可提供更高的分类准确度。然而,当使用独立样本进行验证时,两种特征提取方法之间的差异显著缩小,这表明主成分分析方法可能更容易受到交叉验证过度拟合的影响。 T1 加权和扩散磁共振成像数据均可用于成功区分受试者组,在交叉验证分析的所有成对比较中,两种方式均不优于另一种方式。但是,当使用独立验证队列时,从扩散磁共振成像数据获得的特征可显著提高分类准确率。总体而言,我们的结果支持使用统计分类方法对帕金森病进行鉴别诊断。但是,分类准确率可能会受到组大小、年龄、性别和运动伪影的影响。通过适当的控制和样本外交叉验证,包括基于磁共振成像的分类器在内的诊断生物标志物评估可能是临床评估的重要辅助手段。

使用机器学习预测心血管疾病
摘要 —心血管疾病 (CVD) 是全球主要死亡原因之一。早期诊断和干预对于降低与这些疾病相关的风险至关重要。在本研究中,我们提出了一种基于机器学习的系统,使用极端梯度提升 (XGBoost) 技术预测心血管疾病。我们采用随机搜索的特征选择和超参数优化来提高模型的准确性。通过交叉验证评估模型的性能,并与其他算法进行比较,包括 K 最近邻 (KNN)、朴素贝叶斯、支持向量机 (SVM) 和随机森林。实验结果表明,我们基于 XGBoost 的模型优于其他算法,准确率为 98%,ROC 曲线下面积为 0.98。索引词 —心血管疾病、机器学习、XG-Boost、特征选择、超参数调整、随机搜索、交叉验证、预测模型、算法比较。

使用多壳自由水重建显著提高大脑年龄估计的准确性
图 4 脑年龄和观察年龄的散点图。该图报告了通过留一交叉验证获得的预测以及受试者的观察年龄。黑线代表身份线。10 次重复 10 倍交叉验证的完整散点图集如图 S5 所示

全球海平面可能会在2100年达到190万,超过了早期的预测:NTU研究|海峡时间
“最近,已经发现(在这些冰川)被低估或预测的水下熔化的贡献。在格陵兰等许多地方,水下熔化正在加快整体冰的损失。这要求在这些冰川上更准确地测量冰损,并通过多种方式进行了交叉验证。”

一种提高智能计算有效性的智能方法揭示了信用卡欺诈的最佳方法...
卡拉奇,巴基斯坦摘要这项研究比较了信用卡欺诈检测的机器学习(ML)和深度学习(DL)技术。我们评估了不同数据集的16种ML算法和交叉验证方法的组合。在所有模型中,具有重复k折的随机森林分类器的精度最高99.0%,而F1得分为99.1%。表现最高的深度学习模型,人工神经网络(ANN)的精度为91.3%,F1得分为91.1%,而结合这些方法的混合模型达到98.9%的精度和F1分数。随机森林分类器继续是最佳选择。我们的发现表明,随机森林分类器具有重复的K折交叉验证,根据其他机器学习模型,深度学习模型和混合模型作为平衡数据集中信用卡欺诈检测的最可靠方法的21种组合进行了测试,提供了有价值的洞察力,提供了增强安全性预处理和针对各种银行业领域的国防范围的宝贵见解。

speciateit和vspeciateB:每序列16S rRNA基因分类学分类
图1。(a)VspeciatedB V1V3,V3V4和V4模型的十倍交叉验证表明,来自“已知物种”的序列的出色分类,模型中至少存在1个序列。“新物种”的大多数序列在某些分类级别正确分类。(b)“新物种”的查询序列的后验概率往往相对于不正确的分类而正确分类。