XiaoMi-AI文件搜索系统
World File Search System伞式


生成式 AI
扩散概率模型 扩散概率模型是一类潜在变量模型,常用于图像生成等各种任务(Ho 等人,2020 年)。正式而言,扩散概率模型通过对数据点在潜在空间中扩散的方式进行建模来捕获图像数据,这是受统计物理学启发的。具体来说,它们通常使用经过变分推理训练的马尔可夫链,然后逆转扩散过程以生成自然图像。一个值得注意的变体是稳定扩散(Rombach 等人,2022 年)。扩散概率模型也用于 DALL-E 和 Midjourney 等商业系统。生成对抗网络 GAN 是一类具有自定义对抗学习目标的神经网络架构(Goodfellow 等人,2014 年)。GAN 由两个以零和博弈形式相互竞争的神经网络组成,从而生成特定分布的样本。正式来说,第一个网络 G 称为生成器,用于生成候选样本。第二个网络 D 称为鉴别器,用于评估候选样本来自期望分布的可能性。得益于对抗性学习目标,生成器学习从潜在空间映射到感兴趣的数据分布,而鉴别器则将生成器生成的候选样本与真实数据分布区分开来(见图 2)。(大型) 语言模型 (大型) 语言模型 (LLM) 是指用于建模和生成文本数据的神经网络,通常结合了三个特征。首先,语言模型使用大规模、顺序神经网络(例如,具有注意力机制的 Transformer)。其次,神经网络通过自我监督进行预训练,其中辅助任务旨在学习自然语言的表示而不存在过度拟合的风险(例如,下一个单词预测)。第三,预训练利用大规模文本数据集(例如,维基百科,甚至多语言数据集)。最终,语言模型可以由从业者使用针对特定任务(例如,问答、自然语言生成)的自定义数据集进行微调。最近,语言模型已经发展成为所谓的 LLM,它结合了数十亿个参数。大规模 LLM 的突出例子是 BERT(Devlin 等人,2018 年)和 GPT-3(Brown 等人,2020 年),分别具有 ∼ 3.4 亿和 ∼ 1750 亿个参数。提示是语言模型的特定输入(例如,“这部电影很精彩。从人类反馈中进行强化学习 RLHF 从人类反馈中学习顺序任务(例如聊天对话)。与传统强化学习不同,RLHF 直接从人类反馈中训练所谓的奖励模型,然后将该模型用作奖励函数来优化策略,该策略通过数据高效且稳健的算法进行优化(Ziegler 等人,2019 年)。RLHF 用于 ChatGPT(OpenAI,2022 年)等对话系统,用于生成聊天消息,以便新答案适应之前的聊天对话并确保答案符合预定义的人类偏好(例如长度、风格、适当性)。提示学习 提示学习是一种 LLM 方法,它使用存储在语言模型中的知识来完成下游任务(Liu 等人,2023 年)。一般而言,提示学习不需要对语言模型进行任何微调,这使其高效且灵活。情绪:“),然后选择最可能的输出 s ∈{“positive”,“negative”} 而不是空间。最近的进展允许更复杂的数据驱动提示工程,例如通过强化学习调整提示(Liu et al.,2023)。seq2seq 术语序列到序列(seq2seq)是指将输入序列映射到输出序列的机器学习方法(Sutskever et al.,2014)。一个例子是基于机器学习的不同语言之间的翻译。此类 seq2seq 方法由两个主要组件组成:编码器将序列中的每个元素(例如,文本中的每个单词)转换为包含元素及其上下文的相应隐藏向量。解码器反转该过程,将向量转换为输出元素(例如,来自新语言的单词),同时考虑先前的输出以对语言中的模型依赖关系进行建模。seq2seq 模型的思想已得到扩展,以允许多模态映射,例如文本到图像或文本到语音的映射。Transformer Transformer 是一种深度学习架构(Vaswani 等,2017),它采用自注意力机制,对输入数据的每个部分的重要性进行不同的加权。与循环神经网络 (RNN) 一样,Transformer 旨在处理顺序输入数据(例如自然语言),可用于翻译和文本摘要等任务。但是,与 RNN 不同,Transformer 会一次性处理整个输入。注意力机制为输入序列中的任何位置提供上下文。最终,Transformer(或一般的 RNN)的输出是文档嵌入,它呈现文本(或其他输入)序列的低维表示,其中相似的文本位于更近的位置,这通常有利于下游任务,因为这允许捕获语义和含义 (Siebers et al., 2022)。变分自动编码器 变分自动编码器 (VAE) 是一种神经网络,它被训练来学习输入数据的低维表示,方法是将输入数据编码到压缩的潜在变量空间中,然后从该压缩表示中重建原始数据。VAE 与传统自动编码器的不同之处在于,它使用概率方法进行编码和解码过程,这使它们能够捕获数据中的底层结构和变化,并从学习到的潜在空间中生成新的数据样本 (Kingma and Welling, 2013)。这使得它们不仅可用于异常检测和数据压缩等任务,还可用于图像和文本生成。零样本学习/小样本学习 零样本学习和小样本学习是指机器学习处理数据稀缺问题的不同范例。零样本学习是指教会机器如何从数据中学习一项任务,而无需访问数据本身,而小样本学习是指只有少数特定示例的情况。零样本学习和小样本学习在实践中通常是可取的,因为它们降低了建立 AI 系统的成本。LLM 是小样本或零样本学习器(Brown 等人,2020 年),因为它们只需要一些样本即可学习一项任务(例如,预测评论的情绪),这使得 LLM 作为通用工具具有高度灵活性。


生成式人工智能:
1.**生成对抗网络 (GAN)**:由两个相互竞争的神经网络组成——一个生成器和一个鉴别器。生成器试图生成令人信服的数据实例,而鉴别器则评估它们的真实性。随着时间的推移,这种对抗过程有助于生成器创建高度逼真的输出。2.**变分自动编码器 (VAE)**:它们将神经网络与概率方法相结合,以对数据进行编码和解码。VAE 特别适用于生成作为输入数据变体的新数据点。3.**Transformer 模型**:在自然语言处理领域尤为突出。像 OpenAI 的 GPT-3(生成式预训练 Transformer 3)这样的模型可以根据输入提示生成连贯且符合上下文的文本。**生成式 AI 的应用:** 1.**文本生成**:生成文章、诗歌、问题答案甚至计算机代码。2.**图像创建和编辑**:制作逼真的图像或转换现有图像(例如,将草图变成详细的图片)。3.**音乐创作**:创作各种风格的新音乐作品。4.**合成数据生成**:在真实数据稀缺或获取成本高昂时,生成有用的数据集以训练机器学习模型。5.**创意产业**:协助艺术家、作家和设计师集思广益并开发新概念。生成式人工智能不断发展,不断突破机器创造的界限,并对娱乐、医学和研究等各个领域产生广泛影响。



步入式访问
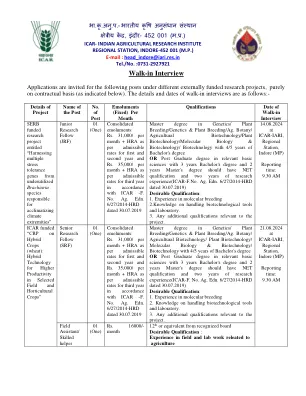
1。经验和资格将被认为是步入式访问日期。2。建议申请人提交与其名称更改有关的文件(如果适用)(即,结婚证书,更改名称的公报,Aadhar Card)。3。大学保留在未分配任何理由的情况下填写或不填写任何或所有职位的权利,并且在这方面不会发出任何通知。4。大学应在任命时验证候选人提交的前因和文件。,如果可以随时检测到,即使在服务期间,候选人提交的文件是假的,或者候选人具有秘密的先例背景,并抑制了所述信息,他 /她的服务应被终止。5。以防在选择的任何无意中的错误中,即使在签发任命信后可以检测到的任何阶段,大学保留修改/撤回/取消候选人的候选人资格和与候选人进行的任何沟通的权利。
步入式采访
i。年龄限制:SRF和JRF的最高年龄为35岁,年轻专业人士为45岁 - 我和30岁的现场助理/熟练助手助手(根据规则,年龄放松)。II。 这些职位纯粹是临时的,最初将按合同填写,直到2025年3月31日,但可以根据候选人的绩效或直到较早的项目终止。 iii。 候选人不得在该研究所要求定期任命该职位与该项目共同终止。 iv。 候选人必须在申请表中被强制填写(按照格式附件),从入学开始的所有复制证书,出生证书的日期,净/同等证书,原始证书或临时证书以及最新的照片以及最近封闭在申请表上的照片。 经验证明和出版物也需要附有申请表。 v。将要求选定的候选人在加入时生产所有原始文档。 vi。 没有任何其他费用来参加面试。 vii。 只有具有必要资格的候选人才能接受面试。 VIII。 以任何形式掩盖事实或拉票应导致取消资格或终止。II。这些职位纯粹是临时的,最初将按合同填写,直到2025年3月31日,但可以根据候选人的绩效或直到较早的项目终止。iii。候选人不得在该研究所要求定期任命该职位与该项目共同终止。iv。候选人必须在申请表中被强制填写(按照格式附件),从入学开始的所有复制证书,出生证书的日期,净/同等证书,原始证书或临时证书以及最新的照片以及最近封闭在申请表上的照片。经验证明和出版物也需要附有申请表。v。将要求选定的候选人在加入时生产所有原始文档。vi。没有任何其他费用来参加面试。vii。只有具有必要资格的候选人才能接受面试。VIII。 以任何形式掩盖事实或拉票应导致取消资格或终止。VIII。以任何形式掩盖事实或拉票应导致取消资格或终止。


基于Wrap-plictic-Flow基于式 - teTection-tracking-moving-objects ...
手稿版本:作者接受的手稿包装中呈现的版本是作者接受的手稿,可能与已发布的版本或记录的版本有所不同。持续的包裹URL:http://wrap.warwick.ac.uk/184584如何引用:有关最新的书目引用信息,请参阅发布版本。如果已知已发布的版本,则链接到上面的存储库项目页面将包含有关访问它的详细信息。版权所有和重复使用:沃里克研究档案门户(WARAP)使沃里克大学的研究人员在以下条件下可用开放访问权限。版权所有©以及此处介绍的论文版本的所有道德权利属于单个作者和/或其他版权所有者。在合理且可行的范围内,已在可用的情况下检查了包装中可用的材料是否有资格。未经事先许可或收费,可以将完整项目的副本用于个人研究或研究,教育或非营利目的。前提是作者,标题和完整的书目细节被认为是针对原始元数据页面提供的超链接和/或URL,并且内容不会以任何方式更改。发布者的声明:请参阅“存储库”页面,发布者的语句部分,以获取更多信息。有关更多信息,请通过以下网络与WARP团队联系:wrap@warwick.ac.uk。