XiaoMi-AI文件搜索系统
World File Search System使用约束

ECO 4270,经济增长 2022 年秋季课程大纲
讲师:乔纳森·亚当斯 (Jonathan Adams) adamsjonathan@ufl.edu 办公室:MAT 333 办公时间:每周二上午 9:30 - 11:30 助教:待定 办公室:待定 办公时间:待定 课程安排:周一和周三,第 7-8 节(下午 1:55 - 3:50) 房间:MAT 119 推荐文本:David Weil,经济增长 先决条件:ECO 2013、ECO 2023 和 ECO 3101(最高至中级微观) 您需要从中级微观和宏观课程中应用的一些特定工具包括:使用约束优化和多元优化解决消费者问题,以及用微分方程表征经济总量的动态。我们将回顾这些工具。但您需要理解几个概念而无需进一步解释,例如:包括 GDP 和投资在内的宏观经济总量,以及包括效用和预算约束在内的消费者概念。本课程还需要大量的微积分知识,因此学生应该熟悉基础微积分,并熟悉多元微积分。最后,学生应该熟悉基础统计学。期中考试:期中考试将于 10 月 17 日星期一举行。将在课堂上进行。期末考试:综合期末考试将在正式考试期间举行:12 月 14 日星期三上午 10:00 至下午 12:00 考试理念:考试的理论部分将测试您对在课堂上和问题集上学习的数学理论的理解。它们通常不会直接来自

机器学习与推理之间的协同作用-Orca
本文提出了对知识表示与推理(KRR)与机器学习(ML)之间的会议点的初步调查,这两个领域在过去的四十年中已经很分开开发。首先,确定并讨论了一些常见的问题,例如所使用的表示类型,知识和数据的作用,缺乏或信息过多,或者需要解释和因果理解。然后,调查是在七个部分中组织的,涵盖了KRR和ML相遇的大多数领域。我们从有关学习和推理的文献中涉及典型方法的部分开始:归纳逻辑编程,统计关系学习和Neurosymbolic AI,其中基于规则的推理的思想与ML结合在一起。然后,我们专注于在学习中使用各种形式的背景知识,范围从损失功能中的其他正规化项到对齐符号和向量空间表示的问题,或者使用知识图来学习。然后,下一节描述了KRR概念如何对学习任务有益。例如,可以像发表数据挖掘的那样使用约束来影响学习模式。或在低射击学习中利用语义特征,以弥补缺乏数据;或者我们可以利用类比来学习目的。相反,另一部分研究了ML方法如何实现KRR目标。例如,人们可以学习特殊类型的规则,例如默认规则,模糊规则或阈值规则,或特殊类型的信息,例如约束或偏好。本节还涵盖正式概念

机器学习与推理之间的协同作用
本文提出了对知识表示与推理(KRR)与机器学习(ML)之间的会议点的初步调查,这两个领域在过去的四十年中已经很分开开发。首先,确定并讨论了一些常见的问题,例如所使用的表示类型,知识和数据的作用,缺乏或信息过多,或者需要解释和因果理解。然后,调查是在七个部分中组织的,涵盖了KRR和ML相遇的大多数领域。我们从有关学习和推理的文献中涉及典型方法的部分开始:归纳逻辑编程,统计关系学习和Neurosymbolic AI,其中基于规则的推理的思想与ML结合在一起。然后,我们专注于在学习中使用各种形式的背景知识,范围从损失功能中的其他正规化项到对齐符号和向量空间表示的问题,或者使用知识图来学习。然后,下一节描述了KRR概念如何对学习任务有益。例如,可以像发表数据挖掘的那样使用约束来影响学习模式。或在低射击学习中利用语义特征,以弥补缺乏数据;或者我们可以利用类比来学习目的。相反,另一部分研究了ML方法如何实现KRR目标。例如,人们可以学习特殊类型的规则,例如默认规则,模糊规则或阈值规则,或特殊类型的信息,例如约束或偏好。本节还涵盖正式概念

sangea:可扩展和归因网络生成
深层生成模型(DGM)是用于学习数据表示的多功能工具,同时合并了域知识,例如条件概率分布的规范。最近提出的DGMS解决了比较来自不同来源的数据集的重要任务。这样的示例是对比分析的设置,该分析的重点是描述与背景数据集相比富含目标数据集中的模式。这些模型的实际部署通常假定DGM自然推断出可解释的和模块化的潜在表示,这在实践中是一个问题。因此,现有方法通常依赖于临时正规化方案,尽管没有任何理论基础。在这里,我们通过扩展非线性独立组件分析领域的最新进展,提出了对比较DGM的可识别性理论。我们表明,尽管这些模型在一般的混合功能上缺乏可识别性,但当混合函数在零件上时,它们令人惊讶地变得可识别(例如,由Relu神经网络参数化)。我们还研究了模型错误指定的影响,并从经验上表明,当未提前知道潜在变量的数量时,以前提出的用于拟合比较DGM的正则化技术有助于识别性。最后,我们引入了一种新的方法,用于拟合比较DGM,该方法通过多目标优化改善了多个数据源的处理,并有助于使用约束优化以可解释的方式调整正规化的超参数。我们使用模拟数据以及通过单细胞RNA测序构建的细胞中的遗传扰动数据集以及最新的数据集验证了我们的理论和新方法。关键字:非线性ICA;深层生成模型;变分推断;解开;

简历 - Benoit Scherrer
期刊论文 • B. Scherrer、F. Forbes、C. Garbay、M. Dojat,《用于组织和结构脑分割的分布式局部 MRF 模型》,IEEE 医学成像学报,28(8),1296-1307,2009。 • B. Scherrer、M. Dojat、F. Forbes、C. Garbay,《基于马尔可夫模型的分割的代理化:应用于 MRI 脑扫描》,《医学人工智能 (AIM)》,46(1),81-95,2009 章节书 • Scherrer B、Forbes F、Garbay C 和 Dojat M,《基于分布式马尔可夫代理的 MR 脑扫描组织和结构分割的联合贝叶斯框架》。在:I. Bichindaritz 和 L. Jain 编辑,《医疗计算智能》。 Springer-Verlag,柏林,309,81-101,2010。同行评审会议论文及论文集 • B. Scherrer、SK Warfield,面向临床实践的精确多纤维评估策略,2011 年 IEEE 国际生物医学成像研讨会 (ISBI) 论文集,芝加哥,2011 年,即将出版 • B. Scherrer、SK Warfield,多张量模型为什么需要多个 b 值。使用约束对数欧几里得模型进行评估,载于 2010 年 IEEE 国际生物医学成像研讨会 (ISBI) 论文集,鹿特丹,2010 年,1389-1392 • B. Scherrer、F. Forbes、M. Dojat,一种将局部配准与稳健组织和结构分割相结合的条件随机场方法,载于第 11 届医学图像计算和计算机辅助干预国际会议 (MICCAI) 论文集,Springer-Verlag Berlin,2009 年,540-548 • B. Scherrer、F. Forbes、C. Garbay、M. Dojat,用于 MR 脑部扫描组织和结构分割的完全贝叶斯联合模型,载于第 11 届医学图像计算和计算机辅助干预国际会议 (MICCAI) 论文集, Springer-Verlag Berlin,2008 年,p1066-1074 *青年研究员奖*

电源存储的机会和限制...
近年来,向商业和海军船舶推进系统的电气化有明显的转变,从而提高了设计灵活性,运营效率和潜在的延长节省燃油效益。降低性能和排放量的动力,再加上增加的负载可变性为储能系统(ESS)提供了机会。更大的电气ESS(超越专用的备份供应)可以为船舶带来许多关键好处。在平行行业驱动的ESS的快速发展的景观中,ESS的主要形式将是电池,飞轮和超级电容器。与使用ESS相关,是为了促进其在其最有效的操作范围内的Prime Mover Operation,ESS提供了外卖功能,以保持持续的Prim-Mover Over of prime-Mover of the Prime-Mover,从而优化,从而减少燃油消耗。本文将考虑ESS在船上的艺术状态及其未来的方向。将检查ESS设备的特征及其在商业和海军船上的应用,并比较ESS的挑战和含义,并通过案例研究来确定海军和商业部门的共同问题。本文以将ESS与未来船相结合的前景结束。关键字:储能系统;燃料消耗;优化1。在过去的20年中,商业和海军船只已朝着使用全电或杂交电源和推进系统的使用。2017; Bellamy and Bray 2015)。2。这种方法提供了一系列好处,包括有机会减少燃料消耗并因此有害环境排放。越来越具有挑战性的绩效标准,规则和立法限制(例如排放的规则和立法限制)是胁迫力量和推进系统设计师采用和适应海洋行业的技术。电池,飞轮和电容器中的电源存储已被限制为关键设备的小规模专用不间断的电源(UPS)(主要是电池)。Kuseian(2015)和Tate and Rumney(2017)同意,在海军部门,由于10至100的小规模UPS,这在海军部门增加了额外的维护。 集中的能源商店可以转移这一负担的一部分,但也提供了本文将探讨的许多其他关键收益。 已经针对商业船舶应用程序采用了储能系统(ESS),例如维京女士离岸供应船和Norled Ampere电池供电的渡轮(Stefanatos等人。Kuseian(2015)和Tate and Rumney(2017)同意,在海军部门,由于10至100的小规模UPS,这在海军部门增加了额外的维护。集中的能源商店可以转移这一负担的一部分,但也提供了本文将探讨的许多其他关键收益。已经针对商业船舶应用程序采用了储能系统(ESS),例如维京女士离岸供应船和Norled Ampere电池供电的渡轮(Stefanatos等人。2015),由于ESS的整合,预计这艘前船将节省其年度燃油消耗的15%。 商业应用具有为ESS定义特定用例的能力的好处,而在海军应用中这更困难,因为用例可能会有很大差异(Stevens等人。 但是,这两个部门共有的是减少燃料消耗和排放的野心。 本文的目的首先是要比较和总结有关商业和海军应用的最新相关性。2015),由于ESS的整合,预计这艘前船将节省其年度燃油消耗的15%。商业应用具有为ESS定义特定用例的能力的好处,而在海军应用中这更困难,因为用例可能会有很大差异(Stevens等人。但是,这两个部门共有的是减少燃料消耗和排放的野心。本文的目的首先是要比较和总结有关商业和海军应用的最新相关性。其次是评估ESS集成的机会和方法。为了实现这些目标,进行了以下目的,这是对当前最新存储的文献综述。然后对两艘候选船进行了介绍,以进行案例研究,以评估燃油消耗的降低,而柴油发电机(DG)在各个运营概况上运行时,当基于锂离子的ESS与每个船只基线的基线功率和推进系统集成时。每个系统都是在稳态条件下建模的,并使用约束优化方法进行了大小。根据Bellamy和Bray(2015)和Hebner等人的船上储能存储。(2015)主要的船舶ESS Technologies可能是电池,电容器或旋转机器。表1中的特征表明,基于锂的电池在能量密度和特定能量上更具竞争力,这通常是商业的关键参数
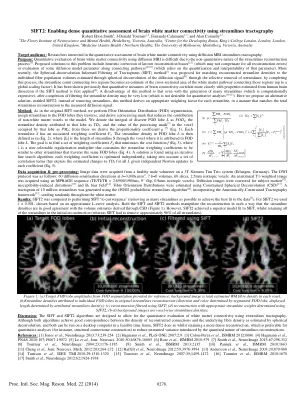
SIFT2:利用流线纤维束成像技术对大脑白质连接进行密集定量评估
目标受众:对使用扩散 MRI 流线纤维束成像定量评估大脑白质连接感兴趣的研究人员。目的:由于流线重建过程的非定量性质 [1],使用扩散 MRI 定量评估大脑白质连接非常困难。针对该问题提出的解决方案包括启发式校正已知的重建偏差 [2,3](可能无法补偿所有重建误差)或评估连接路径上某些扩散模型参数 [4,5,6](依赖于该参数的量化和可解释性)。最近,提出了球面反卷积信息纤维束成像滤波 (SIFT) 方法 [7],通过选择性去除流线,将重建的流线密度与通过扩散信号球面反卷积估计的单个纤维群体积 [8] 进行匹配;完成此过程后,连接两个区域的流线计数变为连接这些区域的白质通路横截面积的估计值(最高可达全局缩放因子)。之前已证明,如果首先应用 SIFT 方法 [9],大脑连接的定量测量与从人脑解剖估计的特性会更加密切相关。这种方法的缺点是,即使生成了许多流线(计算成本高昂),完成过滤后,流线密度可能非常低(这对于定量分析来说是不可取的 [10,11])。在这里,我们提出了一种替代解决方案,称为 SIFT2:此方法不是去除流线,而是为每条流线得出合适的加权因子,以使总流线重建与测量的扩散信号相匹配。方法:与原始 SIFT 方法一样,我们执行纤维方向分布 (FOD) 分割,将流线分配给它们穿过的 FOD 叶,并得出一个处理掩模,以减少非白质体素对模型的贡献。我们将离散 FOD 叶 L 的积分表示为 FOD L ,将归因于该叶的流线密度表示为 TD L ,将处理掩模 [7] 在该叶所占体素中的值表示为 PM L ;从这些中我们得出比例系数 μ [7](等式 1)。每条流线 S 都有一个关联的加权系数 FS 。FOD 叶 L 中的流线密度定义为(等式 2),其中 | SL | 是流线 S 穿过归因于 FOD 叶 L 的体素的长度。目标是找到一组加权系数 FS ,以最小化成本函数 f(等式 3),其中 λ 是用户可选择的正则化乘数,它将流线加权系数约束为与穿过相同 FOD 叶的其他流线相似(等式 4)。使用迭代线搜索算法可以找到解决方案:每个加权系数都经过独立优化,同时考虑一组相关项,这些相关项表示在对每个系数进行独立牛顿更新的情况下所有 L 的 TD L 的估计变化(等式 5)。数据采集和预处理:图像数据是从健康男性志愿者的 3T Siemens Tim Trio 系统(德国埃尔朗根)上采集的。DWI 协议如下:60 个弥散敏化方向,b =3,000s.mm -2,7 b =0 体积,60 个切片,2.5mm 各向同性体素。使用 MPRAGE 序列(TE/TI/TR = 2.6/900/1900ms,9° 翻转,0.9mm 各向同性体素)获取解剖 T1 加权图像。对弥散图像进行了校正以适应受试者运动 [12]、磁化率引起的扭曲 [13] 和 B 1 偏置场 [14]。使用约束球面反卷积 (CSD) [15] 估计纤维取向分布。使用 iFOD2 概率流线算法 [16] 生成了 1000 万条流线的纤维束图,该算法结合了解剖约束纤维束成像框架 [17] ,随机分布在整个白质中。结果:将 SIFT2 与执行 SIFT“收敛”(移除尽可能多的流线以实现与数据的最佳拟合 [7] )进行了比较。对于 SIFT2,我们使用了 λ = 0.001,这是基于近似 L 曲线分析选择的。SIFT 和 SIFT2 方法都以这样一种方式操纵重建,使得流线密度与通过 CSD 得出的体积估计值高度一致(图 1)。然而,SIFT2 实现了比 SIFT 更优秀的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须去除大约 96% 的流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。