XiaoMi-AI文件搜索系统
World File Search System内积


利用捕获离子实现量子非参数学习的协议
非参数学习能够通过从一组新输入数据与所有样本之间的相似性中提取信息来做出可靠的预测。这里我们指出了一种非参数学习的量子范式,它提供了样本大小的指数级加速。通过将数据编码到量子特征空间中,数据之间的相似性被定义为量子态的内积。引入量子训练态来叠加样本的所有数据,在其二分纠缠谱中编码用于学习的相关信息。我们证明了使用量子矩阵工具箱可以通过纠缠谱变换获得用于预测的训练状态。我们进一步制定了一个可行的协议来实现捕获离子的量子非参数学习,并展示了量子叠加对机器学习的强大作用。

量子力学转变概率的通用方法
马克斯·玻恩斯 (Max Borns) 的统计解释 [11] 使概率在量子理论中扮演了重要角色。他假定两个归一化的希尔伯特空间元素的内积的模平方应该解释为两个希尔伯特空间元素所表示的纯态之间的转移概率。数学形式主义并没有为这种解释提供任何理由,但实验证据迫使我们接受它。在 Birkhoffer 和 von Neumann [10] 开创了量子逻辑理论之后,各种版本的量子力学转移概率被引入该理论。大多数方法通过附加公理假定这种版本的存在 [25, 34, 35, 45]。作者早期的方法基于射影量子测量(吕德斯 - 冯诺依曼量子测量过程)或经典条件概率的扩展 [37, 38]。之前的一篇论文 [41] 采用了不同的方法。其目的是指出量子的代数起源
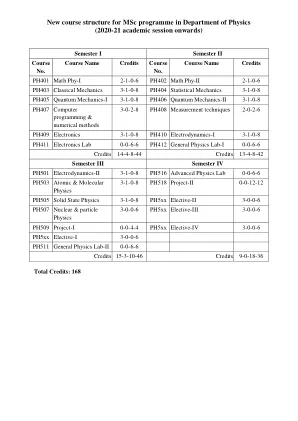
物理系理学硕士课程的新课程结构
PH401:数学物理 I (2-1-0-6) 线性代数:线性向量空间:对偶空间和向量、柯西-施瓦茨不等式、实数和复数向量空间的定义、度量空间、线性算子、子空间;跨度和线性独立性:行减少和方法;基础和维度:使用简化的跨度和独立性测试 (RREF) 方法;线性变换:图像、核、秩、基础变换、转移矩阵、同构、相似变换、正交性、Gram-Schmidt 程序、特征值和特征向量、希尔伯特空间]。张量:内积和外积、收缩、对称和反对称张量、度量张量、协变和逆变导数。常微分方程和偏微分方程:幂级数解、Frobenius 方法、Sturm-Liouville 理论和边界值问题、格林函数;笛卡尔和曲线坐标系中不同波动方程的分离变量法,涉及勒让德、埃尔米特、拉盖尔和贝塞尔函数等特殊函数以及涉及格林函数的方法及其应用。教材:

庞加莱对偶定理及其应用
在本次演讲中,我将解释流形 M 的德拉姆上同调与同一空间上的紧支撑上同调之间的对偶性。这种现象被称为“庞加莱对偶”,它描述了微分拓扑中的一种普遍现象,即流形上封闭的、精确可微形式空间与其紧支撑对应物之间的对偶性。为了定义和证明这种对偶性,我将从向量空间对偶空间的简单定义开始,再到向量空间上正定内积的定义,然后定义流形的概念。我将继续定义可微流形上的微分形式及其相应的空间,这些对于此分析是必要的。然后,我将介绍流形的良好覆盖、有限型流形和方向的概念,这些都是定义和证明庞加莱对偶所必需的概念。我将以 M 可定向且承认有限好覆盖的情况下的庞加莱对偶的证明作为结束,并举例说明。

面向量子计算专家的机器学习
摘要 量子机器学习 (QML) 是量子计算一个很有前途的早期用例。在过去的五年里,从理论研究和数值模拟到概念验证,QML 取得了进展。在现代量子设备上演示的用例包括对医学图像 [ 1 ] 和 Iris 数据集中的项目进行分类 [ 2 ]、对手写图像进行分类 [ 3 ] 和生成 [ 4 ]、毒性筛查 [ 5 ] 以及学习概率分布 [ 6 ]。QML 的潜在优势包括更快的训练 [ 2 ] 和识别经典算法中找不到的特征图 [ 7 ]。尽管这些示例缺乏商业开发的规模,并且 QML 算法可能还需要几年时间才能取代经典解决方案,但 QML 是一个令人兴奋的领域。本文面向那些已经具备量子计算知识,现在希望获得经典机器学习术语和一些应用的基本概述,准备学习量子机器学习的人士。读者已经了解相关的线性代数,包括希尔伯特空间、具有内积的向量空间。

面向量子计算专家的机器学习
摘要 量子机器学习 (QML) 是量子计算一个很有前途的早期用例。在过去的五年里,从理论研究和数值模拟到概念验证,QML 取得了进展。在现代量子设备上演示的用例包括对医学图像 [ 1 ] 和 Iris 数据集中的项目进行分类 [ 2 ]、对手写图像进行分类 [ 3 ] 和生成 [ 4 ]、毒性筛查 [ 5 ] 以及学习概率分布 [ 6 ]。QML 的潜在优势包括更快的训练 [ 2 ] 和识别经典算法中找不到的特征图 [ 7 ]。尽管这些示例缺乏商业开发的规模,并且 QML 算法可能还需要几年时间才能取代经典解决方案,但 QML 是一个令人兴奋的领域。本文面向那些已经具备量子计算知识,现在希望获得经典机器学习术语和一些应用的基本概述,准备学习量子机器学习的人士。读者已经了解相关的线性代数,包括希尔伯特空间、具有内积的向量空间。

超越整体:婴儿宇宙、时空虫洞以及黑洞信息的有序与无序
摘要:20 世纪 80 年代,Coleman 以及 Giddings 和 Strominger 的研究将时空虫洞的物理学与“婴儿宇宙”和一系列理论联系起来。我们重新审视这些想法,使用与负宇宙常数和渐近 AdS 边界相关的特征来强化结果,引入视角的变化,并与最近关于 Page 曲线的复制虫洞讨论联系起来。一个关键的新功能是强调零状态的作用。我们在简单的体拓扑模型中详细探索了这种结构,这些模型使我们能够计算相关边界理论的全部范围。渐近 AdS 希尔伯特空间的维度变成了一个随机变量 Z ,其值可以小于理论中独立状态的简单数量 k 。对于 k > Z ,一致性源于引力路径积分定义的内积的精确退化,因此许多先验独立状态仅相差一个零状态。我们认为,任何一致的引力路径积分都必须具有类似的特性。我们还评论了外推到更复杂模型的其他方面,以及对上述集合中各个成员的黑洞信息问题的可能影响。

量子到经典神经网络迁移学习应用于药物毒性预测
摘要:毒性是阻碍大量药物用于可能挽救生命的应用的障碍。深度学习为寻找理想的候选药物提供了一种有希望的解决方案;然而,化学空间的广阔性加上底层的 n ( ) 3 矩阵乘法意味着这些努力很快就会变得计算量巨大。为了解决这个问题,我们提出了一种混合量子经典神经网络来预测药物毒性,该网络利用量子电路设计来模仿经典神经行为,通过明确计算复杂度为 n ( ) 2 的矩阵积。利用 Hadamard 测试进行有效的内积估计,而不是传统使用的交换测试,我们将量子比特数减少了一半,并且消除了对量子相位估计的需要。直接以量子力学方式计算矩阵积允许将可学习的权重从量子转移到经典设备以进行进一步训练。我们将我们的框架应用于 Tox21 数据集,并表明它实现了与模型的完全经典相当的预测准确度

重新思考具有改进内存覆盖范围的时空网络以实现高效的视频对象分割
本文介绍了一种在视频对象分割背景下对时空对应关系进行建模的简单而有效的方法。与大多数现有方法不同,我们直接在帧之间建立对应关系,而无需为每个对象重新编码掩码特征,从而形成一个高效而强大的框架。利用对应关系,可以通过以联想方式聚合过去的特征来推断当前查询帧中的每个节点。我们将聚合过程视为投票问题,发现现有的内积亲和力导致内存使用率低下,一小部分(固定)内存节点占据投票主导地位,无论查询如何。鉴于这种现象,我们建议使用负平方欧几里得距离来计算亲和力。我们验证了每个内存节点现在都有机会做出贡献,并通过实验表明这种多样化投票有利于提高内存效率和推理准确性。对应网络和多样化投票的协同作用非常出色,在 DAVIS 和 YouTubeVOS 数据集上都取得了新的最先进的结果,同时对于多个对象以 20+ FPS 的速度显着提高运行速度,并且没有任何花哨的功能。