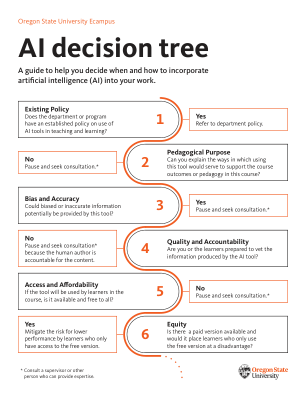
XiaoMi-AI文件搜索系统
World File Search System决策树

基于核函数的一类分类决策树...
a 科学研究基金会 - FNRS (FRS-FNRS),比利时布鲁塞尔 b 比利时蒙斯大学工程学院,数学与运筹学系,比利时蒙斯 c 比利时蒙斯大学工程学院,工程创新管理系,比利时蒙斯

甜度感知的探索性研究:决策树
摘要:使用隐性反应来确定消费者对不同刺激的反应正成为一种流行的方法,但仍需要进行研究以了解用于收集数据的不同技术的输出。在目前的研究中,收集了不同刺激(气味、味道、风味样本)的脑电图 (EEG) 反应和自我报告的喜好和情绪,以更好地了解甜度感知。人工智能分析用于对隐性反应进行分类,识别决策树以通过激活的感觉系统(气味/味道/风味)和刺激的性质(“甜”与“非甜”气味;“甜味”、“甜味”和“非甜味”;以及“甜刺激”与“非甜刺激”)。在自我报告的对刺激的喜好和刺激引起的情绪之间存在显著差异,但未发现显性数据和隐性数据之间的明确关系。本研究总结了与 EEG 相关研究以及 EEG 数据分析的有趣数据,尽管关于如何正确利用隐性测量技术及其数据仍有许多未知之处。

嘉宾专栏:决策树与通信之间的计算模型 1
通信复杂性研究计算一个函数所需的通信量,该函数的值取决于分布在多个实体之间的信息。姚期智 [Yao79] 于 40 多年前发起了通信复杂性研究,如今它已成为理论计算机科学的核心领域,在数据结构、流算法、属性测试、近似算法、编码理论和机器学习等不同领域都有广泛应用。教科书 [KN06,RY20] 对该理论及其应用进行了出色的概述。在通信复杂性的基本版本中,两个玩家,分别称为 Alice 和 Bob,希望计算一个函数 F : X × Y →{ 0 , 1 },其中 X 和 Y 是一些有限集。Alice 持有一个输入 x ∈ X,Bob 持有一个输入 y ∈ Y,他们希望通过按照某种协议来回发送消息来计算 F(x, y)。重要的是,Alice 和 Bob 具有任意的计算能力,因为我们只关心计算该函数需要交换多少信息。目标是设计低成本协议,以 Alice 和 Bob 交换的位数来衡量(在最坏情况下),理想情况下,我们会显示感兴趣的通信问题的通信复杂度的严格上限和下限。让 D cc ( F ) 表示确定性协议在所有输入上正确计算 F 的最低可实现成本。

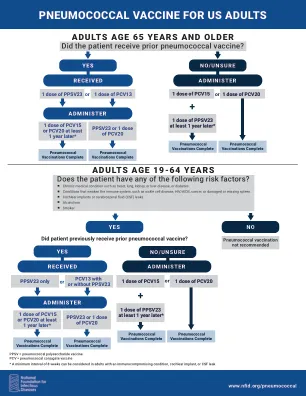
5 岁及以上儿童的 COVID-19 疫苗接种决策树
有关针对中度或重度免疫功能低下者的 COVID-19 疫苗接种的更多信息,请访问 CDC 的针对中度至重度免疫功能低下者的 COVID-19 疫苗临床注意事项网站。

决策树算法与k-最近邻算法的比较...
糖尿病是一种慢性代谢性疾病,其特征是血糖升高,可导致眼睛和重要器官受损。2 型糖尿病是糖尿病的一种变体,最常影响 18 岁以上的成年人,这种变体引起的症状并不明显,识别它需要很长的测试过程。使用分类算法预测糖尿病,有助于在疾病早期阶段将风险降至最低,并帮助健康从业者控制糖尿病的影响。在本研究中,作者在 Pima Indian Diabetes 数据集上比较了决策树和 K-Nearest Neighbor 算法在预测糖尿病方面的表现。两种算法模型均使用 3 个数据集共享比率进行训练,分别为 80:20、70:30 和 65:35。此外,作者还实施了 GridSearchCV 超参数调整,以找到两种模型的最佳参数。两种模型的准确率、精确度、召回率和 F-1 分数用于确定哪种模型具有最佳性能。结果表明,未进行超参数调优的决策树算法在 70:40 的比例下效果最佳,准确率为 83.33%;KNN 算法中 K=7 为最优 K 值,准确率为 77.65%;进行超参数调优的 GridSearchCV 在 80:20 和 65:35 的比例下效果最佳,能够找到决策算法中的最佳参数。但决策树算法仍然存在过拟合的问题。

轴承故障检测与分类的决策树模型比较研究
轴承故障诊断对于减少故障、提高旋转机械的功能性和可靠性至关重要。由于振动信号是非线性和非平稳的,提取特征以进行降维和有效的故障检测具有挑战性。本研究旨在评估基于决策树的机器学习模型在轴承故障数据检测和分类中的性能。提出了一种将基于树的分类器与派生的统计特征相结合的机器学习方法,用于局部故障分类。通过时域分析从正常和故障振动信号中提取统计特征,以开发基于树的 AdaBoost (AD)、分类和回归树 (CART)、LogitBoost 树 (LBT) 和随机森林树 (RF) 模型。

决策树,支持向量机和人工神经...
在这项研究中,应用了三种不同的分类算法,包括决策树,SVM和ANN,以检测MR图像上的FCD病变。然后,他们的表演彼此比较。结果表明,与其他两种方法相比,ANN算法具有更高的灵敏度,特异性和准确性。因此,建议将ANN方法用作计算机辅助FCD病变诊断系统中的最佳分类方法。

使用梯度提升决策树的心脏病预测
摘要:心脏病是全球主要健康挑战之一,其预防和治疗对于确保人们的健康至关重要。这项研究基于2020年堆叠的集合调查数据集用于心脏病分类。通过分析各种因素与心脏病之间的关系,我们探讨了机器学习模型在心脏病预测中的应用。研究发现,诸如空腹血糖,胆固醇和运动引起的心绞痛等因素与心脏病密切相关,而静息心电图和静止血压的影响相对较小。在比较的各种机器学习模型中,梯度提升决策树(GBDT)表现最好,具有高度的预测准确性和精确度。然而,该研究还指出了数据集的局限性以及模型的问题未完全释放其潜力。值得注意的是,这项研究还探讨了在心脏病预测中使用其他机器学习模型的可能性,并进行了比较分析,并提供了更多的预防心脏病预防和治疗参考。