XiaoMi-AI文件搜索系统
World File Search System决策树

使用机器检测脑电图中的癫痫发作
摘要 本研究使用健康受试者和癫痫患者的脑电信号记录公共数据集构建了三个时间复杂度较低的简单分类器,分别是决策树、随机森林和 AdaBoost 算法。首先对数据进行预处理,提取代表大脑活动的短波电信号。然后将这些信号用于选定的模型。实验结果表明,随机森林在检测脑电信号中是否存在癫痫发作方面准确率最高,为 97.23%,其次是决策树,准确率为 96.93%。表现最差的算法是 AdaBoost 评分准确率,为 87.23%。此外,决策树的 AUC 得分为 99%,随机森林为 99.9%,AdaBoost 为 95.6%。这些结果与时间复杂度更高的最先进的分类器相当。

二进制分类的随机森林模型的量子版本Kamil Khadiev A,Liliya Safina A
构建决策树随机森林使用诸如ID3,C4.5 [24],C5.0 [1],CART [10]等著名算法。我们建议使用构造决策树算法的量子版本创建一个随机的森林模型[19]。它允许我们为(√)构建树,是训练数据集的大小,是每个元素的许多属性,是树高(给定参数)。在经典情况下,运行时间等于二进制分类问题。变量,每棵树都不同,并通过包装方法选择。此外,在这项工作[5]中,作者考虑了他们注意到伪随机数和量子随机数发生器对量子随机森林的影响的问题。我们还可以使用其他量子决策树构造算法[22]或使用随机森林的经典版本[14]。

人工智能与银行业:初步考虑
此外,银行业中还有不同的技术或方法可以有效开发人工智能,从神经网络到决策树和自然语言处理工具。每种技术都有独特的特点,使其或多或少适合不同的用途。根据 EBA 提供的数据,欧洲银行在使用决策树和随机森林(83.3%)、回归分析(80%)和自然语言处理(66.7%)方面表现突出。一般来说,决策树和随机森林用于信用评分,因为它们特别可靠,可以准确确定客户履行其财务义务的可能性。无论如何,技术的多样性相当高,因为 60% 使用人工智能的欧洲银行采用的方法与 EBA 监测的方法不同。

Salman等人,巴比伦机器学习杂志卷。 ...
随机森林是一种用于分类和预测的机器学习模型。要训练机器学习算法和人工智能模型,对于有效的数据收集,拥有大量的高质量数据至关重要。系统性能数据对于完善算法,提高软件和硬件的效率,评估用户行为,实现模式识别,决策,预测建模和解决问题至关重要,最终导致有效性和准确性提高。各种数据收集和处理方法的集成增强了问题解决中的精度和创新。利用跨学科研究中的多种方法简化了研究过程,促进创新,并使数据分析发现将发现结果应用于模式识别,决策,预测性建模和解决问题。这种方法还鼓励跨学科研究的创新。该技术利用决策树的概念,构建决策树的集合并汇总其结果以产生最终的预测。使用随机的数据子集构建一个随机森林中的每个决策树,并且每个单独的树都经过整个数据集的一部分训练。随后,所有决策树的结果都被合并以得出最终的预测。随机森林的好处之一是它们处理具有缺失值的不平衡数据和变量的能力。此外,它减轻了某些替代模型看到的任意变量选择的问题。此外,随机森林通过对数据的随机子集进行培训几个决策树来减轻过度拟合的问题,从而增强了它们将其推广到新数据的能力。随机森林被高度视为机器学习领域中最有效,最有效的技术之一。他们在各种应用程序中发现了广泛使用,例如自动分类,数据预测和监督学习。

使用机器学习Sreekumari S 1,Rajni Bhalla 1和Geetha Ganesan 2
抽象的心脏是负责整个身体循环血液的主要器官,在社会中引起的心脏病引起了极大的关注。诊断心脏病给医生带来了重大挑战。研究人员已经探索了多种预测方法来解决此问题。这些预测的准确性仍然是关键的考虑因素。在这项研究中,我们专注于五种不同的机器学习算法,包括随机森林,决策树分类器,逻辑回归,k-neartiment邻居分类器以及带有网格搜索的决策树分类器。此外,我们开发了一个合奏模型,其主要目标是准确预测心脏病。我们的分析利用了Kaggle的心脏病数据集,在检查的五种算法中,决策树分类器的精度最高为92%。这一发现突出了其在预测心脏病方面的有效性。

收到的文章历史记录:20.05.2024接受:05.06.2024发布:30.06.2024引用Raj,A。D.,Pawar,A。S.,Pavankumar,B.,Goyal,K。,&Unisa
摘要:在这一前进的技术时代,智能手机成瘾正变得越来越关注,越来越多的人表现出诸如手机过多,生产率降低以及潜在的身体和心理健康问题等症状,大数据分析的作用正在发展,在分析智能手机成瘾方面正在发展。本研究旨在根据智能手机的使用来找到预测智能手机成瘾水平的可能性。这项研究使用了人们的公开可用的智能手机使用数据集,并结合了机器学习算法(例如决策树,逻辑回归和随机森林)来分析智能手机成瘾水平以进行有效的决策。根据模拟结果,随机森林算法以(0.89)的得分达到了最佳准确性,决策树算法的准确度得分为(0.86)。表现最低的是逻辑回归,其精度得分为(0.74)。关键字:逻辑回归,决策树,随机森林

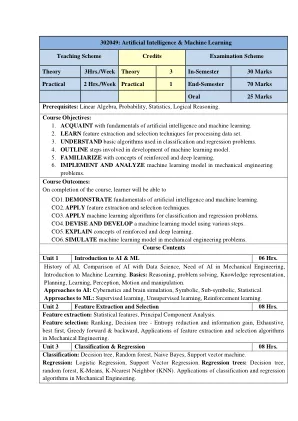
302049:人工智能与机器学习
单元1 AI和ML 06小时的简介。AI的历史,AI与数据科学的比较,机械工程中的AI需要,机器学习简介。 基础:推理,解决问题,知识表示,计划,学习,感知,运动和操纵。 AI的方法:控制论和脑模拟,符号,亚符号,统计。 ML的方法:监督学习,无监督的学习,强化学习。 单元2特征提取和选择08小时。 特征提取:统计特征,主成分分析。 功能选择:排名,决策树 - 熵减少和信息增益,详尽,最佳,贪婪的前向和向后,功能提取的应用和选择算法在机械工程中。 单元3分类和回归08小时。 分类:决策树,随机森林,天真的贝叶斯,支撑向量机。 回归:逻辑回归,支持向量回归。 回归树:决策树,随机森林,K-均值,K-Nearest邻居(KNN)。 机械工程中分类和回归算法的应用。AI的历史,AI与数据科学的比较,机械工程中的AI需要,机器学习简介。基础:推理,解决问题,知识表示,计划,学习,感知,运动和操纵。AI的方法:控制论和脑模拟,符号,亚符号,统计。ML的方法:监督学习,无监督的学习,强化学习。单元2特征提取和选择08小时。特征提取:统计特征,主成分分析。功能选择:排名,决策树 - 熵减少和信息增益,详尽,最佳,贪婪的前向和向后,功能提取的应用和选择算法在机械工程中。单元3分类和回归08小时。分类:决策树,随机森林,天真的贝叶斯,支撑向量机。回归:逻辑回归,支持向量回归。回归树:决策树,随机森林,K-均值,K-Nearest邻居(KNN)。机械工程中分类和回归算法的应用。

研究论文使用决策树、朴素贝叶斯和支持向量对肺癌预测中的分类模型性能的比较分析
本研究旨在利用“肺癌预测”数据集,分析三种分类模型(决策树分类器、支持向量机和朴素贝叶斯分类器)在预测肺癌方面的表现。所采用的性能评估指标包括准确率、精确率加权、召回率加权和 F1 加权。作为初步步骤,进行了探索性数据分析 (EDA) 和数据集预处理,包括特征选择、数据清理和数据转换。测试数据结果显示,决策树分类器和朴素贝叶斯分类器具有相似的性能,准确率、精确率、召回率和 F1 值都很高。同时,支持向量机也表现出了竞争力,尽管其精确率加权值略低。此外,使用箱线图进行了异常值分析,结果显示决策树分类器有 2 个异常值,而支持向量机有 4 个异常值,朴素贝叶斯没有异常值。总而言之,这三种分类模型在肺癌预测中都表现出良好的潜力。然而,选择最佳模型需要考虑应用的相关评估指标,并考虑到每个模型的局限性。需要进一步评估和深入分析,以确保模型在更准确和一致地预测肺癌病例方面的可靠性。

原创文章 基于Python编程的搅拌摩擦焊接头力学性能分析人工智能算法
摘要:在现代计算科学中,机器学习和优化过程之间的相互作用标志着最重要的发展。优化在机械工业中起着重要作用,因为它可以降低材料成本、减少时间消耗并提高生产率。最近的工作重点是对搅拌摩擦焊接工艺进行优化任务,以获得搅拌摩擦焊接接头的最大极限抗拉强度 (UTS)。为此选择了两种机器学习算法,即人工神经网络 (ANN) 和决策树回归模型。输入变量为工具转速 (RPM)、工具移动速度 (mm/min) 和轴向力 (KN),而输出变量为极限抗拉强度 (MPa)。观察到,在人工神经网络的情况下,训练和测试集的均方根误差分别为 0.842 和 0.808,而在决策树回归模型的情况下,训练和测试集的均方根误差分别为 11.72 和 14.61。因此,可以得出结论,ANN 算法比决策树回归算法提供更好、更准确的结果。