XiaoMi-AI文件搜索系统
World File Search System分类

命名和分类,
c lassification在英语中有两个含义:通过共享字符和这些类的排列将事物分为类的过程。识别是观察字符并从而对事物进行分类的过程。生物学分类是生物的布置。分类的能力对于所有动物来说都是共同的,为了生存动物,必须将其他生物分为至少三个类别:被避免食用的生物以及与之交往的人,尤其是自己班级的成员。对于科学家来说,分类被正式化为嵌套或分层的假设集:字符,群体(分类单元)和群体之间的关系的假设。观察到了器官的单个标本,并注意到了特征。因此,例如,我们可能会观察到有些人是黑色的,有些是黄色或白色的,并且像Linnaeus一样得出结论,有不同的人类(Homo Sapiens)。这是一个假设,即肤色是有用的特征。对该特征假设的进一步测试表明,人类的肤色不会界定天然群体。因此,我们拒绝肤色作为人类的角色以及该角色定义的那些群体。颜色对于对许多其他组进行分类是一个非常有用的字符。然后是一组的假设。组


分类技术
•电力网络战略:为了促进电力网络的进一步发展,2017年12月,议会通过了《联邦电力法》和《联邦电力供应法》的修正案。•气候政策:在《巴黎气候变化协议》中,瑞士承诺将其温室气体排放减半,到2030年的1990年水平。要实现这一目标,必须在2020年以后的期间进行修订。2019年,联邦委员会决心,截至2050年,瑞士将其净温室气体排放量减少到零(零净排放目标)。这意味着它的目标是实现国际商定的目标,即将全球气候变暖限制至最高1.5°C,而工业前时期。在2021年6月,修订后的CO2法案被瑞士选民拒绝(另见下文)。•能量视角2050+(EP 2050+)在零零排放方案(零)中分析了如何开发与2050年净零温室气体排放的长期气候目标相吻合的能源系统,并同时确保了安全的能源供应。考虑了这种情况的几种变体。它们的技术组合和电力部门可再生能源转变的速度有所不同。•修订《联邦电力供应法》:《联邦电力供应法》正在进行的修订背后的目的是使电力市场充分自由化。同时,《联邦能源法》也应进行调整。在这里,目的是通过为投资国内可再生能源的投资提供更多有吸引力的激励措施来实施支持市场自由化的措施,从而加强瑞士的供应安全。



实时系统的分类 实时系统的分类 ...
• Brown 和 Campbell (1950):(仅限论文) • 使用实时操作的计算机作为控制系统的一部分。(模拟计算元素) • 第一台专为 R.T.S. 开发的数字计算机用于机载操作。1954 年,数字计算机成功用于自动飞行和武器控制系统。 • 第一个工业计算机安装于 1958 年 9 月,用于路易斯安那州斯特林发电站的工厂监控。 • 第一个工业计算机控制装置由德士古公司制造,该公司于 1959 年 3 月 15 日在德克萨斯州的亚瑟港炼油厂安装了 RW-300 系统 • 第一个 DDC 计算机系统是 Ferranti Argus 200 系统,于 1962 年 11 月在英国兰开夏郡的 ICI 安装。它有 120 个控制回路和 256 个测量值。 • 1974 年微处理器的问世使得经济地使用 DDC 和分布式计算机控制系统成为可能。
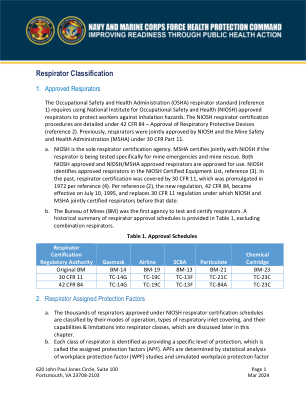
呼吸器分类
(SWPF)研究评估了密封面处呼吸道入口覆盖物(例如面罩)的泄漏量、阀门周围的泄漏量以及通过或围绕滤毒罐或滤毒罐的泄漏量。通过在 WPF 研究和 SWPF 研究期间考虑和测量这些变量的影响,可以估计防护程度并将其与安全系数相结合以分配防护系数。(1)WPF 通过将测得的呼吸器外部工作场所污染物浓度(C out )除以呼吸器内部浓度(C in )来测量呼吸器在工作场所提供的预期防护水平。SWPF 研究与 WPF 类似,但在模拟实验室环境中而不是在工作场所进行测量。(2)APF 表示 C out 与 C in 的最小比率,仅适用于在综合呼吸器计划中使用呼吸器的情况。OSHA 将 APF 定义为“当雇主实施持续有效的呼吸保护计划时,呼吸器或呼吸器类别预计为员工提供的工作场所呼吸保护水平。”附录 A 包含指定保护因素的表。


供应分类
供电分类 — 供电通常根据合同负荷按以下电压进行: 使用低于上述分类电压的供电的消费者需要支付委员会不时规定的低压供电附加费。同样,使用高于上述分类电压的供电的消费者将获得委员会不时规定的高压供电回扣。 供电费用 供电费用应按照委员会不时批准的关税表执行。费用可能包括: (1) 委员会在最新的许可证持有人关税令中为许可证持有人确定的能源供应费用(固定、需求、能源费用等); (2) 法定征税,例如电费、税费或消费者根据法律应缴纳的任何其他税费/关税; (3) 委员会确定的过境费和/或交叉补贴附加费和额外附加费(如有); (4) 经委员会批准的许可证持有人的电表和其他电力装置及设备的租金(如有); (5) 杂费,如超出合同需求的罚款费、逾期付款附加费以及委员会不时批准的任何其他适用费用。 持牌人的供电义务 持牌人应在其供电区域内任何处所的业主或占用人提出申请后,在本法规定的时间内向该处所供电,但前提是 (1) 供电在技术上可行;