XiaoMi-AI文件搜索系统
World File Search System分量

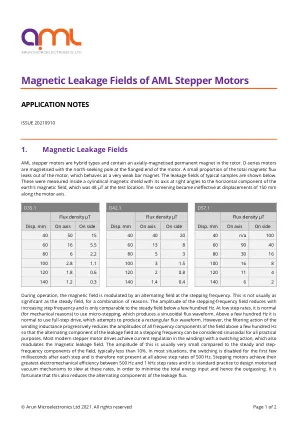
AML 步进电机的漏磁场
在操作过程中,磁场由步进频率的交变场调制。由于多种原因,这通常不如稳定场那么重要。步进频率场的幅度随着步进频率的增加而减小,并且仅在几百赫兹以下与稳定场相当。在低步进速率下,出于机械原因,使用微步进是正常的,微步进会产生正弦磁通波形。在几百赫兹以上,使用全步进驱动是正常的,全步进驱动试图产生矩形磁通波形。然而,绕组电感的滤波作用逐渐降低了几百赫兹以上场的所有频率分量的幅度,因此,步进频率下的漏磁场的交变分量在所有实际用途中都可以被视为正弦波。大多数现代步进电机驱动器通过开关动作实现绕组中的电流调节,这也会调节磁漏场。与场的稳定和步进频率分量相比,漏磁场的幅度通常非常小,通常小于 10%。在大多数情况下,切换在每步之后的前几毫秒内被禁用,因此在步进速率高于 500 Hz 时根本不存在切换。步进电机在 500 Hz 和 1 kHz 步进速率之间实现其最大机电效率,并且设计电动真空机构以在这些速率下旋转是标准做法,以尽量减少总能量输入,从而减少排气。幸运的是,这还可以减少漏磁通的交变分量。

MC1408−8 8位乘法D/A转换器
电路描述 MC1408-8 由一个参考电流放大器、一个 R-2R 梯形放大器和 8 个高速电流开关组成。对于许多应用,只需要添加一个参考电阻和参考电压。开关在操作时为非反相;因此,输入的高状态会打开指定的输出电流分量。开关使用电流转向来实现高速,并使用由有源负载增益级和单位增益反馈组成的终端放大器。终端放大器在切换期间将梯形放大器的寄生电容保持在恒定电压,并为梯形放大器的所有支路提供相等电压的低阻抗终端。R-2R 梯形放大器将参考放大器电流分成二进制相关分量,这些分量被馈送到等于最低有效位的剩余电流。该电流被分流至地,最大输出电流为参考放大器电流的 255/256,如果 NPN 电流源对完全匹配,则 2.0 mA 参考放大器电流的最大输出电流为 1.992 mA。

相位补偿法在近地表地球动力学过程地电控制中的应用
本研究致力于应用利用场相位特性的地电控制补偿法来检测和定位地球动力学过程。与通常用于分析观测结果的电磁场异常分量的振幅参数相比,地电信号的相位配准法具有较高的抗噪性。开发了一种使用场相位特性来解释监测数据和相关地球动力学过程定位问题的形式化方法。在该方法的框架内,提出了通过加权均方解释误差和包含有关地电剖面先验信息的正则函数的最小和来确定剖面参数。为了检查球形溶洞的定位可能性,模拟了沿安装剖面移动球心时场电位的振幅和相位异常分量以及非均匀定位的标准误差。模拟表明,与不均匀位置具有良好的潜在区分度,在不均匀定位问题中,通过结合使用幅度和相位场分量可以获得最高的定位精度。
基于侧窗滤波的脑图像融合方法
脑医学图像融合在构建当代图像以增强相互和重复信息以用于诊断目的方面起着重要作用。提出了一种对脑图像使用基于核的图像滤波的新方法。首先,使用双边滤波器生成源图像的高频分量。其次,估计第一幅图像的强度分量。第三,对几个滤波器采用侧窗滤波,包括引导滤波器、梯度引导滤波器和加权引导滤波器。从而最小化第一幅图像的强度分量与第二幅图像的低通滤波器之间的差异。最后,基于三个评估指标对融合结果进行评估,包括标准差(STD)、特征互信息(FMI)、平均梯度(AG)。基于该算法的融合图像包含更多信息、更多细节和更清晰的边缘,有助于更好地诊断。因此,我们基于融合图像的方法能够很好地找到目标体积的位置和状态,从而远离健康部位并确保患者的健康。


背景文件 - ClassNK
1.3.2.e 航海作业(S+D 条件)的允许剪切应力从总尺寸(UR S11)的 110/k N/mm 2 增加到 120/k N/mm 2,以反映净厚度方法。港口/油舱试验作业的验收标准是航海条件的 87.5%。允许弯曲应力的相应比率为 75%。差异的原因在于两种响应的动态和静态分量之间的比率不同。波浪弯矩通常是静态弯矩的 1.5-2 倍,而剪切的情况则相反,设计静态剪切力约为波浪剪切的 2 倍。港口的 87.5% 是这样设定的,通过添加一半动态分量(即船体梁波浪剪切力)可达到 100%。

使用动态时间规整增强事件相关电位分析的平均值
在 [17] 中,作者考虑了一种扭曲方案,该方案采用基于最小二乘的时间位移和对齐底层模型。Gibbons 和 Stahl [20] 也考虑了 ERP 平均的响应时间校正:作者假设 ERP 分量(尤其是后期分量)的时间会有显著变化,因此他们建议使用多项式表达式来校正响应时间,该表达式基于先前确定的平均响应时间和线性插值。[21] 中介绍了不考虑噪声、抖动或新频率的出现而迭代使用平均 DTW。在 [22] 中,作者提出了一种成本矩阵的修改,该修改可以消除在对非线性对齐的信号周期进行平均时抑制噪声的不利结果。

Cardiogen-82-Rubidium氯化RB-82注射,解决方案BRACCO DIAGNOSTICS INC
剂量和给药给药:1,480 MBQ(40 MCI),每次通过50 mL/min的静脉输注,每次静止或应力分量的范围为1,110 MBQ至2,220 MBQ(30 MCI至60 MCI)。(2.2)使用型号1700输液系统时给药:每次休息或每次休息的实际体重(0.27 mci/kg至0.81 mci/kg),每次休息时间为10 MBQ/kg至30 mbq/kg,每次休息或应力分量通过静脉输液或20 ml/分钟或20 mL/分钟/分钟/分钟/分钟。(2.2)不超过2,220 MBQ(60 MCI)的最大剂量,或每次休息的最大体积100 mL或过程的应力分量。(2.2)其余剂量和应力剂量之间的最小间隔为10分钟,以允许足够的RB 82衰减。(2.2)输液完成后60秒至90秒开始图像采集;如果预计循环时间更长,请等待120秒。图像采集为5分钟。(2.3)用于辐射安全,输液系统,洗脱教学,洗脱测试,剂量输送和到期