XiaoMi-AI文件搜索系统
World File Search System化生


通过星际多烯的固态氢化生产线性烷烃
上下文。高度不饱和的碳链,包括波利尼斯。随着金牛座分子云-1(TMC-1)的Quijote调查的成功,该社区在检测到的碳链数量中看到了“繁荣”。另一方面,罗塞塔(Rosetta)任务揭示了完全饱和的碳氢化合物,C 3 H 8,C 4 H 10,C 5 H 12,(在特定条件下)C 6 H 14与C 7 H 16的C 6 H 14,从Comet 67p/Churyumov-Gerasimenko中。后两者的检测归因于尘埃泛滥的事件。同样,Hayabusa2 Mission从小行星Ryugu返回的样品的分析表明,Ryugu有机物中存在长期饱和脂肪族链。目标。在类似于分子云的条件下,不饱和碳链的表面化学性质可以在这些独立观察结果之间提供可观的联系。但是,仍缺乏基于实验室的研究来验证这种化学反应。在本研究中,我们的目标是通过在10 K.方法下超高真空条件下的C 2 N H 2(N> 1)Polyynes的表面氢化来验证完全饱和的烃的形成。我们进行了两步实验技术。首先,紫外线(≥121nm)辐照C 2 H 2冰的薄层,以将C 2 H 2的部分转化为较大的Polyynes:C 4 H 2和C 6 H 2。之后,将获得的光处理冰暴露于H原子中,以验证各种饱和烃的形成。结果。除了先前研究的C 2 H 6外,我们的研究证实了较大的烷烃的形成,包括C 4 H 10和(暂时)C 6 H 14。对获得的动力学数据的定性分析表明,鉴于表面温度为10 K,HCCH和HCCCCH三键的氢化以可比的速率进行。这可能发生在乌云阶段的典型时间表上。还提出了通过N-和O-O-bearenty Polyynes的表面氢化形成其他各种脂肪族有机化合物的一般途径。我们还讨论了天文学的含义以及与JWST鉴定烷烃的可能性。

乳腺化生梭形细胞癌的分子分析揭示了潜在的可靶向生物标志物
梭形细胞癌是一种罕见的化生性乳腺癌亚型,具有三阴性表型。使用免疫组织化学和 DNA/RNA 测序对 23 例梭形细胞癌进行了全面探索,以寻找免疫肿瘤学和靶向治疗的生物标志物。梭形细胞癌在大多数情况下以可靶向的分子改变为特征,但由于缺乏统一的结果,需要对个体患者进行分析。简介:梭形细胞癌是一种罕见的化生性乳腺癌亚型,具有三阴性(TNBC:雌激素受体阴性/孕激素受体阴性/人表皮生长因子受体 2 阴性)表型。它与对常规化疗的明显耐药性有关,总体预后较差。材料与方法:利用免疫组织化学和 DNA/RNA 测序技术对 23 例乳腺纯梭形细胞癌(18 例原发性癌和 5 例复发/转移性癌)进行全面探索,以寻找免疫肿瘤学和靶向治疗的生物标志物。结果:大多数(21/23)梭形细胞癌为 TNBC。在 2 例中检测到雌激素和雄激素受体表达超过治疗阈值。在 23 例中,21 例确诊为致病基因突变,包括 PIK3CA 、 TP53 、 HRAS 、 NF1 和 PTEN 。1 例化疗前后样本匹配的病例在两个样本中显示出一致的突变谱( PIK3CA 和 HRAS 突变)。5 例出现基因扩增,其中 1 例未检测到突变。梭形细胞癌队列的总突变负荷始终较低(整个 TNBC 队列的总突变负荷均低于 80 百分位数)。所有肿瘤均为微卫星稳定。程序性死亡配体 1 表达在肿瘤细胞(7/21 例)和肿瘤内滤过免疫细胞(2/21 例)中均有观察到。结论:梭形细胞癌在大多数情况下以可靶向的分子改变为特征,但由于缺乏统一的结果,需要对个体患者进行分析。检测个体生物标志物组合应能改善这种罕见但侵袭性疾病的治疗方案。

细胞学的未来:基于人工智能的全新工作方式
HSIL:高度鳞状上皮内病变细胞 LSIL:低度鳞状上皮内病变细胞 ASC-US:意义不明确的非典型鳞状细胞 EC:宫颈管细胞 MSC:化生鳞状细胞
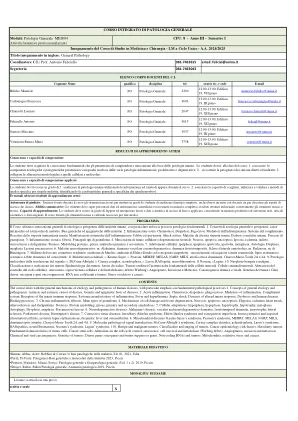
一般病理的综合过程CFU
该课程涉及人类疾病的病因和发病机理的一般机制,特别着重于基本病理过程。1。一般病因和发病机理的概念:疾病的内在和外在原因。疾病的遗传和表观遗传基础。2。<分为急性炎症。趋化性,尿布,吞噬作用。<毁灭调解人。先天免疫反应受体。发烧和热疗。 改变了先天反应疾病。 3。 慢性炎症:纤维化。 <分为主要类型的肉芽瘤。 4。 Celle损伤和组织变性的机制。 缺氧,缺血,心脏病发作,动脉粥样硬化和血脂异常。 蛋白质不形成,prion,原发性和继发性淀粉样变性。 5。 细胞适应:增生,发育不全,肥大,萎缩,化生。 6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。发烧和热疗。改变了先天反应疾病。 3。 慢性炎症:纤维化。 <分为主要类型的肉芽瘤。 4。 Celle损伤和组织变性的机制。 缺氧,缺血,心脏病发作,动脉粥样硬化和血脂异常。 蛋白质不形成,prion,原发性和继发性淀粉样变性。 5。 细胞适应:增生,发育不全,肥大,萎缩,化生。 6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。改变了先天反应疾病。3。 慢性炎症:纤维化。 <分为主要类型的肉芽瘤。 4。 Celle损伤和组织变性的机制。 缺氧,缺血,心脏病发作,动脉粥样硬化和血脂异常。 蛋白质不形成,prion,原发性和继发性淀粉样变性。 5。 细胞适应:增生,发育不全,肥大,萎缩,化生。 6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。3。 慢性炎症:纤维化。 <分为主要类型的肉芽瘤。 4。 Celle损伤和组织变性的机制。 缺氧,缺血,心脏病发作,动脉粥样硬化和血脂异常。 蛋白质不形成,prion,原发性和继发性淀粉样变性。 5。 细胞适应:增生,发育不全,肥大,萎缩,化生。 6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。3。慢性炎症:纤维化。<分为主要类型的肉芽瘤。4。Celle损伤和组织变性的机制。缺氧,缺血,心脏病发作,动脉粥样硬化和血脂异常。 蛋白质不形成,prion,原发性和继发性淀粉样变性。 5。 细胞适应:增生,发育不全,肥大,萎缩,化生。 6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。缺氧,缺血,心脏病发作,动脉粥样硬化和血脂异常。蛋白质不形成,prion,原发性和继发性淀粉样变性。 5。 细胞适应:增生,发育不全,肥大,萎缩,化生。 6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。蛋白质不形成,prion,原发性和继发性淀粉样变性。5。细胞适应:增生,发育不全,肥大,萎缩,化生。6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。6。 神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。 7。 8。 9。 10。 <肿瘤的DIV分类和分期。6。神经退行性疾病:m。阿尔茨海默氏症,血管和神经退行性痴呆,前 - 时间痴呆,肌萎缩性侧索硬化症,米。帕金森氏症,米。亨廷顿。7。8。9。10。<肿瘤的DIV分类和分期。<肿瘤的DIV分类和分期。遗传结缔组织疾病(Marfan综合征,Ehlers-Danlos和不完美的成骨综合征,omocystinuria)并获得(类风湿关节炎,全身性红斑狼疮,红斑红斑红斑,喂养,富含风湿性和OsteoRarthritis)。线粒体疾病:s。 Kearns-Sayre,s。皮尔森,Merrf,Melas,Narp,Mils,主要的光学萎缩,charcot-Marie-tooth 2a和4th。信号转导的分子病理学:s。 McCune-Albright,s。 Carley Complex,可刺激性浮肿,s。 Laron,Rasopathie,神经纤维瘤病,S.Noonan,S.Legius。癌症流行病学:危险因素。<癌细胞的分裂遗传肿瘤的基本特征。肿瘤干细胞。控制细胞周期,衰老,细胞存活和代谢的改变(Warburg效应)。血管生成,侵袭和转移。cheep-化学和病毒基因。肿瘤的遗传学。驱动基因:Oncogeni和Oncerspressor Geners。非编码和肿瘤。氧化应激和癌症。

快速电视转播(印度)2024年3月19日
使用小鼠模型,研究人员发现,链球菌的定植引发了急性炎症反应,然后是慢性阶段,具有密集和持续的胃炎。慢性炎症已知会引发癌症的生长和发育。在小鼠中,感染引起了从慢性胃炎到萎缩,化生和发育不良的发展,这是人类在胃癌之前所遵循的途径。此外,与单独的病原体相比,与Anginosus和H. Pyloi的共同感染产生的胃炎更大,这表明两者可能会共同作用以促进胃炎。

Andrew Phillips博士
领导端到端数据管理和分析策略以及能力的发展,这些策略将显着影响新型生物制剂的未来药物的传递。这包括在数据管理,实验室自动化,计算建模和机器学习的交集上建立一个跨学科团队。为生物制剂工程开发活跃的学习系统,在该系统中,模型预测指导实验室实验,实验室自动化生成了用于模型培训的高通量数据,并且随着新数据的生成,更新了预测模型。生物制剂工程负责发现和优化阿斯利康所有关键疗法领域的下一代生物药物候选物,以及开发内部生物学发现平台和新颖的药物形态,以满足未满足的医疗需求。

食管癌的靶向治疗
导致Barrett的食道(BE),这是由下食管的柱状柱化生组成的公认的前体病变。仍然是EAC发展(11-13)的最强烈的已知危险因素。据信,巴雷特的化生症在发展为腺癌之前经过低至高级发育不良的发展(14-16)。ESCC的主要危险因素是吸烟,饮酒,热饮料饮酒和营养不良。不幸的是,食管癌所有阶段的总体5年生存率仍低于20%。尽管多模式治疗方案取得了重大进展,但由于对化学疗法的耐药性高,总体预后仍然很差(17,18)。此外,大多数食管癌在诊断时已经无法切除(19)。尽管食管癌最初对全身疗法的反应很好,但大多数患者最终死于疾病(20)。因此,需要新的治疗选择。随着食管癌的新生物标志物的鉴定(21),有针对性的疗法正在获得兴趣(22)。 在食管癌中,已经鉴定出了几种潜在的靶向途径(23)。 这些靶标包括人类表皮生长因子受体2(HER2,NEU,ERBB2)(23),表皮生长因子受体(EGFR,HER1,ERBB1)(24)(24),血管随着食管癌的新生物标志物的鉴定(21),有针对性的疗法正在获得兴趣(22)。在食管癌中,已经鉴定出了几种潜在的靶向途径(23)。 这些靶标包括人类表皮生长因子受体2(HER2,NEU,ERBB2)(23),表皮生长因子受体(EGFR,HER1,ERBB1)(24)(24),血管在食管癌中,已经鉴定出了几种潜在的靶向途径(23)。这些靶标包括人类表皮生长因子受体2(HER2,NEU,ERBB2)(23),表皮生长因子受体(EGFR,HER1,ERBB1)(24)(24),血管

Downsview Lands 公共艺术战略
名为“ideate” Downsview(称为“id8 Downsview”)。参与人员强调了对土著、黑人和其他应享有公平待遇的社区实现公平结果的重要性,包括获得娱乐和低于市场租金的空间,以及承诺提供资源、空间和机会以继续建设繁荣、充满活力和可持续的当地艺术和文化生态系统的重要性。强调了作为未来规划的一部分,需要有各种专门的社区运营的艺术计划(例如空间和项目),以及获得资金和发展机会,以培养当地艺术家和组织为增长和可持续发展做出贡献的能力。还强调了为所有年龄段的社区成员提供参与当地艺术和文化活动的机会的重要性。

《癌症生物学年度评论》研究从慢性损伤到食管腺癌的进展
癌症研究旨在了解恶性转化的生物学原理。最近,食管腺癌 (EAC) 的发病率急剧上升,如果我们了解其原因和方式,我们将能够更好地进行诊断、预后、检测、预防和干预。大多数恶性肿瘤进展的最初阶段是最难研究的。人们认为癌症的发生是一种相对罕见和偶然的事件,其发生的位置和时间通常不为人知。在我们体内数以万亿的体细胞中,只有少数细胞会走上恶性肿瘤的道路。然而,慢性炎症会产生一种化生病变,这种病变与 EAC 发病率增加直接相关,从而提醒我们进展开始的时间和地点,并使我们能够研究其生物学原理。我们描述了最近的研究,这些研究确定了进展为 EAC 的基质细胞和上皮细胞之间的协调作用。