XiaoMi-AI文件搜索系统
World File Search System双头
双信头 - 北方司令部
任务。J2 – 情报局 使命:为北美防空司令部和美国北方司令部的任务提供及时、有针对性和准确的情报。愿景:一个敏捷的情报机构,推动北美防空司令部和美国北方司令部的规划、行动和决策。NJ3 - 北美防空司令部行动 一个有选择性的联合和合成参谋部,作为北美防空司令部的顾问,负责警告和评估针对北美的战略海上、导弹、太空和空中袭击。确保和平时期的空中主权以及美国和加拿大对对称和不对称航空航天威胁的有效防御。负责北美防空司令部的所有当前、未来和信息行动,包括 NOBLE EAGLE (ONE) 行动。 NCJ3 – 美国北方司令部作战任务:美国北方司令部 J3 指挥作战,同步各组成部分的作战效果,与其他作战司令部、跨机构合作伙伴和伙伴国进行协调,同时监控、评估并向北美防空司令部指挥官和美国北方司令部提供态势感知,了解所有可能或已经影响美国北方司令部责任区的事件。J4 – 后勤和工程局任务:协调、同步和
双信头 - 北方司令部
任务。J2 – 情报局 使命:为北美防空司令部和美国北方司令部的任务提供及时、有针对性和准确的情报。愿景:一个敏捷的情报机构,推动北美防空司令部和美国北方司令部的规划、行动和决策。NJ3 - 北美防空司令部行动 一个有选择性的联合和合成参谋部,作为北美防空司令部的顾问,负责警告和评估针对北美的战略海上、导弹、太空和空中袭击。确保和平时期的空中主权以及美国和加拿大对对称和不对称航空航天威胁的有效防御。负责北美防空司令部的所有当前、未来和信息行动,包括 NOBLE EAGLE (ONE) 行动。 NCJ3 – 美国北方司令部作战任务:美国北方司令部 J3 指挥作战,同步各组成部分的作战效果,与其他作战司令部、跨机构合作伙伴和伙伴国进行协调,同时监控、评估并向北美防空司令部指挥官和美国北方司令部提供态势感知,了解所有可能或已经影响美国北方司令部责任区的事件。J4 – 后勤和工程局任务:协调、同步和
双信头 - 北方司令部
任务。J2 – 情报局 使命:为北美防空司令部和美国北方司令部的任务提供及时、有针对性和准确的情报。愿景:一个敏捷的情报机构,推动北美防空司令部和美国北方司令部的规划、行动和决策。NJ3 - 北美防空司令部行动 一个有选择性的联合和合成参谋部,作为北美防空司令部的顾问,负责警告和评估针对北美的战略海上、导弹、太空和空中袭击。确保和平时期的空中主权以及美国和加拿大对对称和不对称航空航天威胁的有效防御。负责北美防空司令部的所有当前、未来和信息行动,包括 NOBLE EAGLE (ONE) 行动。 NCJ3 – 美国北方司令部作战任务:美国北方司令部 J3 指挥作战,同步各组成部分的作战效果,与其他作战司令部、跨机构合作伙伴和伙伴国进行协调,同时监控、评估并向北美防空司令部指挥官和美国北方司令部提供态势感知,了解所有可能或已经影响美国北方司令部责任区的事件。J4 – 后勤和工程局任务:协调、同步和
双信头 - 北方司令部
任务。J2 – 情报局 使命:为北美防空司令部和美国北方司令部的任务提供及时、有针对性和准确的情报。愿景:一个敏捷的情报机构,推动北美防空司令部和美国北方司令部的规划、行动和决策。NJ3 - 北美防空司令部行动 一个有选择性的联合和合成参谋部,作为北美防空司令部的顾问,负责警告和评估针对北美的战略海上、导弹、太空和空中袭击。确保和平时期的空中主权以及美国和加拿大对对称和不对称航空航天威胁的有效防御。负责北美防空司令部的所有当前、未来和信息行动,包括 NOBLE EAGLE (ONE) 行动。 NCJ3 – 美国北方司令部作战任务:美国北方司令部 J3 指挥作战,同步各组成部分的作战效果,与其他作战司令部、跨机构合作伙伴和伙伴国进行协调,同时监控、评估并向北美防空司令部指挥官和美国北方司令部提供态势感知,了解所有可能或已经影响美国北方司令部责任区的事件。J4 – 后勤和工程局任务:协调、同步和

DNA双链断裂修复途径的选择与调控
图 1 DSB 修复途径总览 .DSB 发生后 , Ku70-80 会最先结合上来 , 如果不发生末端切除 , 会继而招募 DNA-PKcs, ligase IV, XRCC4 等 cNHEJ 核心因子介导 cHNEJ 修复途径 .如果末端发生 MRN-CtIP 介导的末端切除 , 则会产生 ssDNA 抑制 cNHEJ 修复途 径 .短程切除和长程切除产生的 ssDNA 可以通过链内退火进行修复 , 分别被称为 alt-EJ 和 SSA.长距离切除产生的 ssDNA 也可以 在 BRCA2-PALB2-BRCA1 复合体的帮助下和 RAD51 形成核蛋白纤维 , 进行同源找寻和连入侵过程 , 从而进入 HR 修复途径 .HR 途径又可以分为 BIR, SDSA 和 DSBR Figure 1 Overview of DSB repair pathways.The broken ends are first recognized and bound by Ku70-80.Without end resection, other cNHEJ core factors, such as DNA-PKcs, ligase IV, XRCC4, would be recruited to DSBs to mediate cNHEJ pathway.When MRN-CtIP-mediated resection occurs, the generated ssDNA will inhibit cNHEJ pathway.ssDNA from short-range and long-range resection can anneal in-strand to resolve the damages, termed Alt-EJ and SSA, respectively.ssDNA from long-range resection can also be bound by RAD51 to form nucleoprotein filament under the help of BRCA2-PALB2-BRCA1 complex.Nucleoprotein filament carry out homologous searching and strand invasion, promoting HR pathway.The HR pathway could be divided into BIR, SDSA and DSBR
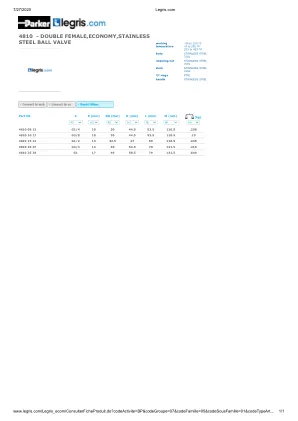
4810 - 双母头,经济型,不锈钢...
www.legris.com/Legris_ecom/ConsulterFicheProduit.do?codeActivite=BP&codeGroupe=07&codeFamille=05&codeSousFamille=01&codeTypeArt… 1/1

基于ROS的双机械臂协同感知抓取系统设计与实现
机器人手臂任务中的感知技术。通过分析机器人臂的运动学并设计双臂合作系统,将视觉点云技术结合起来,实现双臂合作握把,并通过使用ROS平台来验证合作社CON-TROL策略的有效性,从而构建双臂臂系统的实验平台。主要研究内容包括分析机器人ARM运动学的正和反向运动学模型,视觉点云识别在双臂合作任务中的应用,双臂合作控制策略的实现以及合作掌握的实验结果和分析。通过这项研究,成功设计和实现了基于ROS的双机器人臂合作感,并实现了双臂合作控制策略的有效性。

2024 Xiamen Darius Catalog-双页印刷版(无嵌入)修改尺寸 ...
达里乌斯(Div> Darius)一直专注于全球智能保健产品的制造已有10多年的历史,并积累了超过1000万单位的保健产品。目前,该公司有16个§ĉĉáì¶çĭ。 Öîtouminstrecoustout。

信头
ALSEA 宣布首席执行官继任计划 墨西哥城,2025 年 1 月 13 日 — Alsea, SAB de CV (BMV: ALSEA*)“Alsea”是拉丁美洲和欧洲领先的快餐店 (QSR)、咖啡店和全方位服务餐厅运营商,该公司通知,Alsea 董事会已任命 Christian Gurría Dubernard 为公司下一任首席执行官。这一决定符合长期继任战略,该战略是经过全面有效的内部和外部选拔流程制定的。 Christian 将从 2025 年 7 月 1 日起接替 Armando Torrado Martínez 担任该职位,后者将在过渡期内协助他,之后再承担新的职责。管理机构将在整个过渡过程中为 Armando 和 Christian 提供支持。 Alsea 真诚感谢 Armando 在担任首席执行官近三年期间的奉献和辛勤工作,他以热情和承诺领导着公司。在他任职期间,公司在其运营区域实现了盈利性有机增长,并发展成为一个更加敏捷和充满活力的组织,推动了长期发展。 Christian Gurría Dubernard 为 Alsea 带来了超过 25 年的丰富而成功的专业经验。 1991 年,他在 Domino's Pizza 担任店内运营商,从此开始在公司工作,后来晋升为区域总监。 此后,他担任过公司各个部门的各种领导职务,包括墨西哥休闲餐饮总监、墨西哥星巴克总监,以及最近六年来法国和比荷卢三国地区的星巴克总监。 他的主要成就包括星巴克在墨西哥的发展,从 Av. Paseo de la Reforma 的第一家店开始,并在法国实施 Alsea 为星巴克的成功运营模式,重振该品牌在法国的增长。 Christian 将提供领导力、国际经验、管理跨学科团队的专业知识以及跨多个部门、品牌和市场的运营知识。他将带领 Alsea 进入盈利、增长、创新和共享价值创造的新阶段,专注于公司的核心业务支柱。在新的领导团队和市场领导战略愿景的支持下,Alsea 致力于保持盈利和效率。这种方法使公司能够成功应对未来挑战,并持续为股东、客户和员工创造价值。责任限制本新闻稿包含某些预测或预计,这些预测或预计反映了 Alsea 及其管理层对其业绩、业务和未来事件的当前看法或期望。Alsea 使用了诸如“相信”、“预期”、“计划”、“期望”、“打算”、“目标”、“估计”等词语,
