XiaoMi-AI文件搜索系统
World File Search System多代
博士论文药代动力学-药效学建模...
联合药物疗法是成功治疗多种疾病的关键,在这些疾病中单一疗法效果不够好或出现了耐药性。因此,开发新的药物组合是主要关注点。固定剂量组合也是如此,近年来批准的固定剂量组合有所增加。开发固定剂量组合通常需要进行大规模析因设计研究以验证组合的疗效。随着对药物个性化的更多关注,需要为患者提供几种剂量水平的固定剂量组合。对于析因设计研究,这将导致非常昂贵的临床试验。为了降低开发成本并指导药物开发,必须验证现有工具并开发新工具。然而,用于分析固定剂量组合的此类基于模型的工具还处于起步阶段。

C 代数值 Sb 度量空间及其应用...
1922 年,Stefan Banach 建立了一个重要的不动点定理,即巴拿赫收缩原理 (Banach 收缩原理),它是分析学的基本结果之一,也是不动点理论的基本公理。BCP 吸引了众多数学家的注意,并由此产生了各种应用和扩展。1993 年,Czerwik 引入了半度量空间的新起源 [3]。此后,许多作者研究了此类空间中的不动点理论 [1,2,5,14]。此外,Xia [19] 将这些空间称为 b 度量空间。有关该空间的更多信息,请参见 [6]。最近,在 [8] 中,作者引入了 C ∗ -代数值度量空间的概念。事实上,实数集的研究已经过渡到单元 C ∗ -代数的所有正元素的框架。在 [ 7 ] 中,作为 b -度量空间和算子值度量空间 [ 9 ] 的推广,作者引入了一类新的度量空间,即 C ∗ -代数值 b -度量空间,并给出了此类空间中满足压缩条件的自映射的一些不动点结果。


阿米代尔地方住房战略 2024
在这方面,为了支持协调一致、具有成本效益地释放土地和基础设施,在寻求对位于增长区内第 0-2 阶段以外的土地进行任何重新分区之前,应更新战略以确定需求和需求,以及土地的特定地点开发限制,并将更新后的战略提交给该部门批准。与该部门以及初级产业和区域发展部、新南威尔士州交通部和新南威尔士州生物多样性、保护和科学小组等主要机构的持续合作对于成功实施该战略至关重要。我鼓励理事会积极参与并与这些机构合作,讨论潜在的高环境土地、重要农田、易受洪水侵袭的土地、交通管理和无障碍计划等问题。如果您希望进一步讨论此事,欢迎致电 6643 6410 联系该部门的规划官 Sam Tarrant 先生。此致
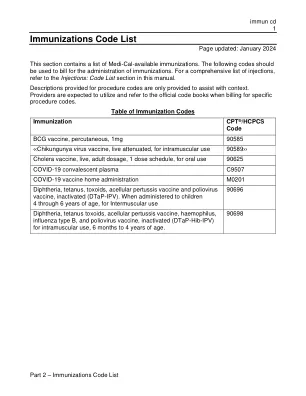
免疫接种代码表 (immun cd)
日本脑炎病毒灭活疫苗,肌肉注射用 90738 麻疹/腮腺炎/风疹病毒活疫苗 (MMR) 90707 麻疹、腮腺炎、风疹和水痘活疫苗 (MMRV) 90710 脑膜炎球菌结合疫苗,血清群 A、C、Y 和 W-135,四价(MCV4 或 MenACWY)

第 2 承包中队 - 巴克斯代尔空军基地 - AF.mil
该中队充当客户在任务要求方面的业务顾问。它为作战指挥官和远征作战部队提供全球应急合同支持。执行合规合同,培养飞行员并照顾家人,不断寻求提高合同及时性/绩效并降低成本,为 COCOM 提供训练有素/准备就绪的 CCO。截至 2019 年 9 月 30 日的财政年度,授予的总金额超过 4700 万美元,其中授予了 3900 万美元的小型企业主合同。

人口药代动力学研究和模拟
在GOF图上以图形方式评估了最终的PK模型,包括观察到的值与个人预测或人口预测,有条件加权残差(CWRE)与时间,绝对个体的加权残差(| iWRES |)与个人预测以及CWRE的正常性测试。进行hootstrap以内部验证最终模型。原始数据集用于模拟1,000个附加数据集,每个数据集用于使用最终模型重新估算参数。中值和95%的置信区间(CI),并将其与最终模型参数估计值进行比较,以评估最终模型的鲁棒性。视觉预测检查(VPC)用于评估最终模型的预测能力。进行了1000个模拟,并比较了观察到的数据与模拟数据的第2.5,第50和97.5个百分位数。

通过交互式3D代创建想要的东西
最近进步[20,29,30]中的2D图像结构,以方法为例,例如在广泛的文本图像配对数据集中受过训练的扩散模型(例如,Laion-series [31]),在与文本提示符的一致性图像中取得了显着的前进。尽管取得了成功,但实现对图像产生的精确控制以满足复杂的用户期望仍然是严重的挑战。ControlNET [38]通过在特定条件数据集上进行微调修改Foun-odation-2D扩散模型来解决此问题,从而提供由用户特异性输入引导的微妙控制机制。另一方面,尽管有希望的进展[27,35],但与2D图像生成中遇到的那些相比,3D对象的生成更为复杂。al-尽管从透视感中观察到了进步,包括直接3D数据集[10,25]上的3D扩散模型,以及将2D扩散率提升到3D复位(例如NERF [21])通过SDS损失的技术优化[27],没有完全对生成Ob-Ob-ob-ob-ob-jects的控制。对初始文本提示或2D参考图像的依赖严重限制了发电的可控性,并且通常会导致质量较低。文本提示缺乏准确传达复杂3D设计的特异性;尽管2D参考图像可以告知3D重建,但它们并没有捕获3D结构的完整深度,可能导致各种意外的人类。此外,基于2D图像的个性化缺乏直接3D操纵可以提供的灵活性。这些障碍表明需要采取不同的策略。实现可控制的3D发电的直接想法是将控制网络调整为3D生成。但是,该策略遇到了重大障碍:(i)3D的控制信号本质上更为复杂,这使得与2D范式相比,有条件的3D数据集对构成的3D数据集进行了挑战; (ii)3D域中没有强大的基础模型,例如2D [20]的稳定扩散,阻碍了此时开发微调技术的可能性。结果,我们倾向于

超声和二硫代醇的协同作用
抽象目的:与植入物相关的感染代表了导致发病率和死亡率增加的重要并发症。确定引起感染的微生物剂对于成功治疗至关重要。尽管周围关节感染(PJIS)随着时间的推移而发生的发生率,但尚无100%灵敏度的诊断测试来准确识别这些感染。本研究的目的是确定将超声处理与Dithiothreitol(DTT)相结合是否提高了诊断植入物相关感染的准确性和敏感性。方法:具体来说,本研究包括30名因怀疑感染而因植入物去除的患者。植入物分为两个段:使用超声处理方法处理一个段,另一种是通过组合DTT和超声处理来处理的。结果:对于合并组而言,平均值为81.17 +/- 67.53 cfu/ml,对于组合组,平均值为109.7 +/- 62.78 cfu/ml。结论:我们的研究结果表明,DTT和超声处理的组合增加了菌落数量约为28.53 CFU/ML,这增强了检测到骨科植入物相关感染的可能性。

《生成式人工智能时代的认知建模》专题介绍
*1 在此专题中,该术语广泛指用于理解人类内部过程的计算模型。 这种用法与国际会议ICCM(https://iccm-conference.github.io/)的定义一致。