XiaoMi-AI文件搜索系统
World File Search System多变

菌血症的危险因素及其对复杂社区获得的尿路感染的临床影响
摘要:菌血症在某些感染中与严重程度有关;但是,它对尿路感染预后(UTI)的影响仍然存在争议。我们的目标是确定细菌血症的危险因素及其对复杂社区获得性尿路感染的住院患者的临床影响。,我们对被复杂社区获得的UTI的医院录取的患者进行了前瞻性观察性研究。比较了有或没有菌血症患者的临床变量和结果,并进行了多变量分析以鉴定菌血症和死亡率的危险因素。在279例社区获得性尿道的患者中,有37.6%的人具有阳性的血液培养。通过多变量分析的菌血症的危险因素是温度≥38℃(p = 0.006,或1.3(95%CI 1.1-1.7))和procalcitonin≥0.5ng/ml(P = 0.005,或8.5(95%CI 2.2-39.4))。院内和30天死亡率分别为9%和13.6%。快速沙发(P = 0.030,或5.4(95%CI 1.2-24.9))和Barthel指数<40%(P = 0.020,或4.8(95%CI 1.3-18.2))与30天的死亡率通过多变量分析有关。然而,菌血症与30天死亡率无关(P = 0.154,或2.7(95%CI 0.7-10.3))。我们的研究发现,高热社区获得的UTI和降低的降钙素是菌血症的危险因素。菌血症患者的结局稍差一些,但死亡率没有显着差异。

国家电池:塔斯马尼亚水电公司的……
• 随着供应变得更加多变,存储预计将发挥越来越重要的作用,并且所有类型的存储都有其作用 • 深度存储对于为客户找到长期“最低成本”解决方案至关重要 • 更长时间的存储:

B Tech&M仪器工程技术课程
模块1:控制器性能索引,基于模型和模型的调整及其比较研究,高级调整技术和直接合成;模块2:基于模型的控制,模型不确定性和干扰,IMC结构和设计,基于IMC的PI-PID控制器设计;模块3:多变量控制系统的简介,交互分析和多个单回路设计,多变量控制器的设计,相对增益阵列,MIMO系统的调整,De-Coupler Design的概念;模块4:模糊控制技术及其结构,模糊控制 - 实时专家系统设计,基于知识的控制器设计,非线性模糊控制,推论方案,规则基础生成和规则最小化技术;模块5:自适应模糊控制,性能监测和评估,适应机制;模块6:神经控制器设计,具有混合结构的神经模糊控制器,神经模糊的自适应学习控制网络,神经模糊控制器的结构学习;模块6:模糊和神经模糊控制器的优化技术。

心脏肿瘤和LOWAST的临床决策
未衡量或残留的混杂和健康的用户偏见多变量回归,标准化或倾向得分方法对混杂因素或混杂因素的代理进行完整调整,包括希思行为的测量,通过定量偏差分析,负面控制或通过试验结果进行基准测试

为什么在生物信息学中的概率和统计数据?
•序列比对:检测DNA或蛋白质序列之间的相似性。•系统发育树重建(“生命之树”)•基因预测(隐藏的马尔可夫模型)•分析微阵列数据(多个测试,多变量分析)•爆炸搜索(随机步行,极值)•分析计算机模拟,网络等。•更多!

生物统计学要求的选项
o因果推理o总结数据:探索性数据分析,表和图形o概率概念和分布o假设测试和置信区间o p值和统计显着性o样本量和功率o线性和逻辑多变量回归分析o生存分析和Cox回归分析

这就是可靠性。Weishaupt WGL40-A
由于容量范围从 125 kW 大幅增加至 550 kW,新款 WGL40-C 现在更加灵活多变,经济实惠且绝对精确。双燃料燃烧器在油操作中采用滑动两级运行,在气操作中采用滑动两级或调节运行 - 具体取决于所使用的负载控制类型。

原始调查 | 肿瘤学 免疫疗法与使用 Defini 治疗的脑转移癌患者的生存期之间的关联
a 由于各组相互排斥,因此开发了三种不同的多变量分析模型。所有三种模型均根据诊断年龄、种族、医院类型、合并症评分和肿瘤类型进行了调整。化疗加免疫治疗模型还包括收入,而放化疗加免疫治疗模型则包括收入和诊断年份以及其他因素。

先进的航空电子设备和军用飞机人机...
必须强调整个系统中人与机器的能力之间的差异——人与机器都可以被视为具有巨大但非无限智能的复杂系统;机器的控制性能快速且可重复,而人的控制性能缓慢且多变;两者在压力下都容易发生故障;人的决策能力缓慢但灵活,机器的反应迅速但受到其可容纳程序范围的限制。发展的
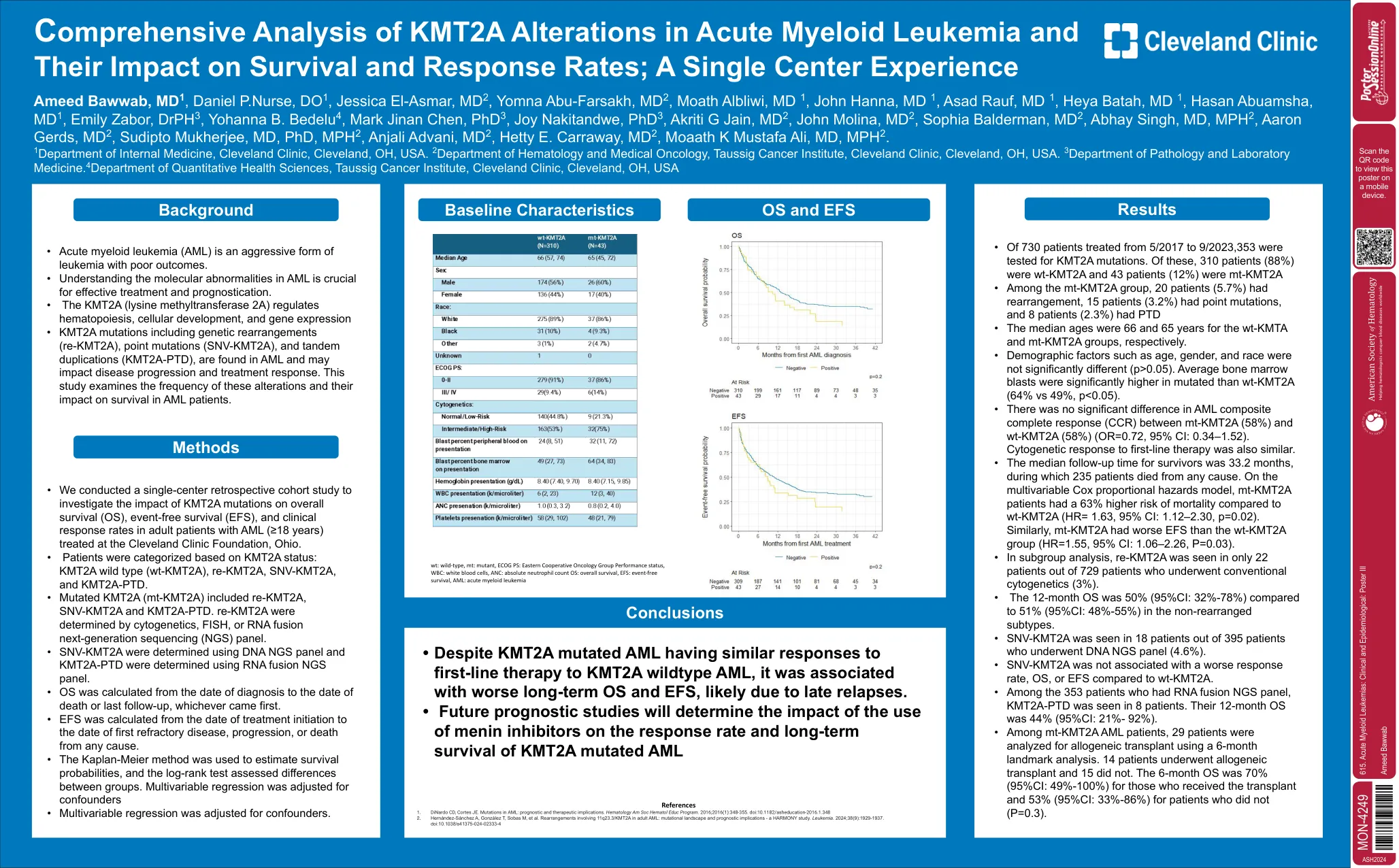
615. 急性髓系白血病:临床和流行病学
• 我们进行了一项单中心回顾性队列研究,以调查 KMT2A 突变对在俄亥俄州克利夫兰诊所基金会接受治疗的 AML 成年患者(≥18 岁)总体生存率 (OS)、无事件生存率 (EFS) 和临床反应率的影响。 • 根据 KMT2A 状态对患者进行分类:KMT2A 野生型 (wt-KMT2A)、re-KMT2A、SNV-KMT2A 和 KMT2A-PTD。 • 突变的 KMT2A (mt-KMT2A) 包括 re-KMT2A、SNV-KMT2A 和 KMT2A-PTD。re-KMT2A 由细胞遗传学、FISH 或 RNA 融合下一代测序 (NGS) 面板确定。 • 使用 DNA NGS 面板确定 SNV-KMT2A,使用 RNA 融合 NGS 面板确定 KMT2A-PTD。 • OS 计算时间为诊断日期至死亡日期或最后一次随访日期(以较早者为准)。 • EFS 计算时间为治疗开始日期至首次出现难治性疾病、疾病进展或因任何原因死亡的日期。 • 使用 Kaplan-Meier 方法估计生存概率,使用对数秩检验评估组间差异。多变量回归已针对混杂因素进行调整 • 多变量回归已针对混杂因素进行调整。