XiaoMi-AI文件搜索系统
World File Search System字符串

语言模型的视觉检查
学习建模字符串之间的关系的学习是什么教授大型语言模型(LLMS)关于Vi-Sual世界的?我们系统地评估了LLMS生成和识别出增加复杂性的各种视觉概念的能力,然后演示如何使用文本模型来培训预先的视觉表示学习系统。由于语言模型缺乏将视觉信息作为像素消耗或输出视觉信息的能力,因此我们使用代码来表示研究中的图像。尽管LLM生成的图像看起来不像自然图像,但图像产生的结果以及模型校正这些固定图像的能力表明,字符串的精确建模可以教授有关Vi-Sual World的许多方面的语言模型。此外,使用文本模型生成的图像进行了自我监督的视觉表示学习的实验,突出了能够训练能够使用LLMS对自然IM的语义评估进行训练视觉模型的潜力。

sq9910/sq9910a
产品描述SQ9910是PWM高效LED驱动器控制IC。它允许从85V AC到265V AC的电压来源的高亮度(HB)LED有效运行。SQ9910以高达300kHz的固定开关频率控制外部MOSFET。可以使用单个电阻对频率进行编程。LED字符串以恒定电流而不是恒定电压驱动,从而提供恒定的光输出和增强的可靠性。输出电流可以在几毫安之间进行编程,最高超过1.0a。SQ9910使用坚固的高压连接隔离过程,该过程可以承受最高500V的输入电压振荡。可以通过在SQ9910的线性调光控制输入下应用外部控制电压来编程到LED字符串到零和最大值之间的任何值。SQ9910提供了低频PWM DIMMing输入,该输入可以接受占空比为0-100%的外部控制信号,频率高达几千期应用程序电路

量子记忆辅助可观察的估计
对多数观测的估计是量子插入处理的必不可少的任务。通常,通常可以将Obsavables分解为多倍的Pauli字符串的加权总和,即单价Pauli矩阵的张量产物,可以用低深度的Clif-Ford Circits轻松测量。但是,在这种方法中,射击噪声的积累严重限制了有限数量的测量值的可实现差异。我们引入了一种新颖的方法,称为连贯的Pauli总结(CPS),该方法通过利用访问单一量子量子存储器来避免这种限制,在该记忆中可以存储和确保测量信息。cps可减少给定方差所需的测量数量,该测量值与分解可观察到的Pauli字符串数量线性缩放。我们的工作表明了单个长相位量子记忆如何在基本任务中有助于多数Quantum设备的操作。

量子信息与计算
为什么要将量子力学与计算和信息理论结合起来?首先,什么是信息,什么是计算?在经典语境中,信息以布尔变量字符串(“位”)的形式存在,计算是通过规定的步骤序列(“程序”)更新字符串的过程,它通过基本布尔运算(“门”)来实现,如 AND、OR、NOT、SWAP 等,其特性是每一步都需要固定的努力来执行,与字符串的长度无关。但位究竟是什么?除了作为布尔变量的存储单位外,它还具有我们可以通过区分物理状态(电子电荷等)来识别其所代表的变量的特性。正如 R. Landauer 所说,“没有表示就没有信息”。因此,我们得出了一个令人震惊的结论,即计算(和信息处理)必须对应于表示信息的系统的物理演化。因此,信息存储、通信和处理的所有可能性和局限性都必须以物理定律为基础——由于许多原因,这种观点并不十分流行,但有一定依据。但当然,量子物理学与经典物理学截然不同。原则上,量子计算机确实无法计算经典计算机上无法计算的任何东西。原因很简单:我们可以用经典计算机模拟薛定谔方程,因此可以模拟任何量子系统——无论需要多长时间。尽管如此,当我们将量子思想引入计算的“物理系统演化”时,我们仍然可以实现比经典计算更多的目标。首先,量子计算机提供了更强大的计算能力,无论是在计算某些对象所需的空间还是时间上。例如,考虑以下任务:给定一个整数 N(n = O(log N)位),我们希望快速找到它的一个因子,即算法在多项式时间内运行,即计算它所需的时间受“输入大小”n 的多项式的限制。可以使用明显的试除法算法,直到√

量子计算谓词绑定承诺及其在 NP 量子零知识论证中的应用
量子比特承诺方案是通过利用量子通信和量子计算来实现比特(而不是量子位)承诺。在本文中,我们研究了通过并行组成通用量子完美(或统计)隐藏计算绑定比特承诺方案(可基于量子安全单向排列(或函数)实现)获得的量子弦承诺方案的绑定性质。我们表明,与平凡的诚实绑定相比,所得方案满足更强的量子计算绑定性质,我们将其称为谓词绑定。直观且粗略地讲,谓词绑定性质保证,给定一组字符串上的任何不一致谓词对(即,该集合中没有字符串可以满足两个谓词),如果可以打开(声称的)量子承诺,使得所揭示的字符串肯定满足一个谓词,则不能打开相同的承诺,使得所揭示的字符串满足另一个谓词(除了可忽略的概率)。作为一种应用,我们在 Blum 的零知识协议中为 NP 完全语言汉密尔顿循环插入了一个通用的量子完美(或统计)隐藏计算绑定位承诺方案。由此产生的协议的量子计算健全性将直接来自承诺的量子计算谓词绑定属性。结合可以类似地建立为 Watrous [Wat09] 的完美(或统计)零知识属性,这产生了第一个量子完美(或统计)零知识论证系统(健全性误差为 1/2),适用于所有 NP 语言,仅基于量子安全单向置换(或函数)。
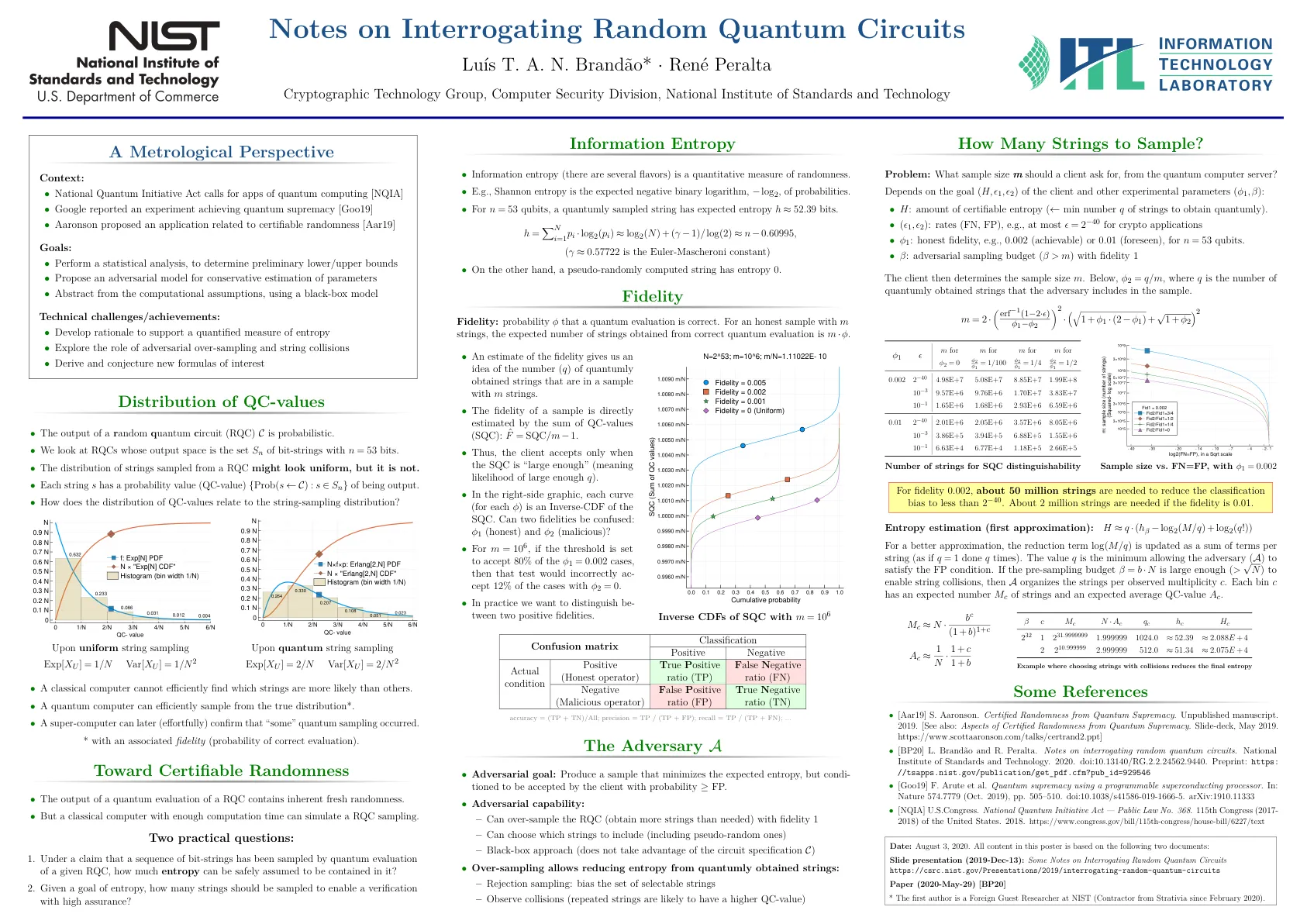
询问随机量子电路的注意事项
为了获得更好的近似值,减少项 log ( M / q ) 被更新为每个字符串的项之和(好像 q = 1 做了 q 次)。值 q 是允许对手 ( A ) 满足 FP 条件的最小值。如果预采样预算 β = b · N 足够大(> √

练习表2:测量和公司
编码经典位。我们知道,描述量子系统需要指数量的经典位。那么,我们可以使用量子状态存储指数量的位吗?或以这种方式可以在D维量子系统中编码多少个经典位并(完美)解码?在本练习中,我们看到我们需要测量以访问量子状态的信息的事实限制了我们可以从量子系统状态中提取的经典信息的数量。让H为D维克斯空间。我们的目的是将N经典位编码为密度矩阵d(h)的量子状态空间。有2个可能的n经典位的不同安排:| {0,1} n | = 2 n。为此,我们选择一组2 n个状态{ρx}x∈{0,1}n⊂d(h),每个状态对应于一点字符串。现在,我们想提出一个测量协议,以便在测量每个ρx时,我们会观察到相应的位字符串x∈{0,1} n

算法信息理论
算法信息概念的原始表述独立于R.,J。Solomonoff [10],A。N. Kolmogorov [11]和G. J. Chaitin [12]。二进制字符串X的信息内容I(x)定义为最小程序的大小(二进制数字),用于计算x的规范通用计算机U。(计算机u是通用的,意味着对于任何其他计算机,都有一个前缀!l,使得iLi使您执行与程序P制作M完全相同的计算。)两个字符串的联合信息i(x,y)被定义为使您计算两者的最小程序的大小。以及给定y的条件或相对信息l(x 1 y)定义为最小程序的大小,供u从y计算x ..标准计算机U的选择最多在这些概念的数值中最多引入0(1)的不确定性。(o(f)读取“顺序o(f”,并表示一个函数,其绝对:ute值由恒定时间f。)

是大型语言模型,您需要预测综合性和
图1。(a)140,120结构的T-SNE可视化以及晶体系统和元素数量的统计数据。(b)合成性LLM的训练过程。使用PU学习模型构建平衡的数据集,将批次转换为材料字符串,然后用Lora进行微调。(c)1,401,562结构的CLSCORE分布和用于滤除非混合结构的CLSCORE范围。(d)前体和方法LLM的培训过程。37,654个化学公式及其前体和合成方法的数据对是从文献中收集的,并用洛拉进行了微调。(e)使用LLM预测合成性和建议前体的总体工作流程。首先将晶体结构转换为材料字符串。然后由合成性LLM预测其合成性。基于化学公式,llms的前体和方法提供了一批潜在的前体及其反应能。

为什么电池组中的单元格失去平衡?调查包装不均匀性在生命不平衡的作用:一项模拟研究
发现,在负载下测量的包装中的瞬时不平衡会随着平行字符串的添加以及较宽的母线电阻分布而增加。这可能会驱动包装细胞不均匀降解。此外,母线中的开路断层似乎会导致永久性失衡和包装容量的严重缺乏。