XiaoMi-AI文件搜索系统
World File Search System实体关系

我们与人工智能实体关系中的伦理问题
本章讨论我们与人工实体(机器人、机器人和其他计算系统)关系的伦理问题,这些实体被创建来与我们互动,就好像它们是有知觉和自主的个体一样。它们可能体现为机器人或仅存在于软件中;有些显然是人造的,而另一些则至少在某些条件下与人类没有区别。此类互动何时有益或有害?我们与计算实体的关系如何改变我们与其他人类的关系?我们与机器或人类互动在什么时候很重要,为什么?感知能力(具有情感、感受到痛苦并想要避免痛苦的能力)是这里的核心概念。我们对有知觉的生物负有道德责任,而对无知觉的物体则没有:踢狗是残忍的,但踢石头则不是。虽然有感知能力的人工实体将来可能会出现,但目前还只是理论上的可能性。目前所有存在的人工实体都是无感知的,但与岩石不同,它们的相互作用和设计让人觉得它们是有个性和情感的有意识实体。模拟感知能力是本章的主要焦点,强调了我们与看似有感知能力但实际上没有感知能力的实体之间的关系。有些相当简单;我们对拟人化的倾向可以使即使是原始程序的输出在我们看来也像是一个有认知能力的思维行为。其他则复杂得令人费解,对有意识和智能行为的复杂模仿几乎无法与真正有意识的生物的行为区分开来。我们将研究的一些伦理问题涉及我们与人工实体的个人关系。人们寻求人工智能助手的陪伴,为损坏的机器狗举行葬礼,并向模拟治疗师倾诉。

药物的实体关系图非线性数据融合……
动机:预测可靠的药物-靶标相互作用 (DTI) 是计算机辅助药物设计和再利用中的一项关键任务。在这里,我们提出了一种基于数据融合的 DTI 预测新方法,该方法建立在 NXTfusion 库之上,通过将矩阵分解范式扩展到实体关系图上的非线性推理来推广它。结果:我们在五个数据集上对我们的方法进行了基准测试,并将我们的模型与最先进的方法进行了比较。我们的模型优于大多数现有方法,同时保留了预测 DTI 作为二元分类和实值药物-靶标亲和力回归的灵活性,可与为每个任务明确构建的模型相媲美。此外,我们的研究结果表明,DTI 方法的验证应该比之前一些研究中提出的更严格,更多地侧重于模拟真实的 DTI 设置,其中需要预测以前未见过的药物、蛋白质和药物-蛋白质对。这些设置正是将异构信息与我们的实体-关系数据融合方法集成的好处最明显的环境。
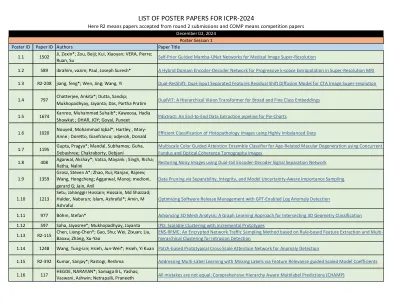
ICPR-2024的海报论文列表
1.132 179张,bin; zou,chaofan*;歌曲,Wenwen FTC:联合实体和关系提取的新颖三胞胎分类模型1.133 363张,梁; Zheng,Nan* H2O2NET:一个新型实体关系连接网络,用于联合关系三重提取1.134 R2-629 BHESRA,KIRTILEKHA; Agarwal,Akshay*一个多模式的框架来对抗仇恨演讲
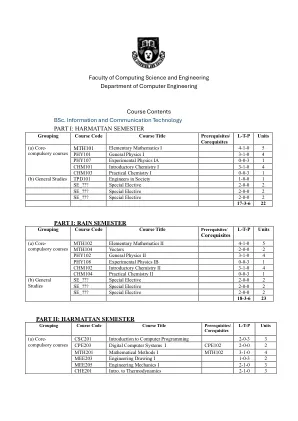
ICT-课程.pdf
数据库系统概述:模型、模式、实例。数据库系统与文件系统。数据抽象级别、数据库语言、系统架构。DBMS 分类。数据建模:实体关系 (ER) 模型、实体和实体类型、关系和关系类型、约束、弱实体类型 ER、图表。示意对象模型。数据库设计过程:需求分析、概念数据库设计、数据库模式设计。使用实体关系和语义对象模型进行数据库设计、数据库应用程序设计。关系数据模型中的术语、完整性约束、关系上的原始操作、关系代数 (RA)、关系代数运算、关系完整性、关系上的附加操作。关系实现的基础。结构化查询语言 (SQL):SQL 中的 DML 功能、SQL 中的 DDL、SQL 中的更新、SQL 中的视图、嵌入式 SQL、按示例查询 (QBE)。并发、恢复和安全问题。阿姆斯特朗的推理规则和最小覆盖、范式。数据库系统的当前趋势:客户端-服务器数据库系统、开放数据库连接 (ODBC) 标准、知识库系统、数据仓库和数据挖掘概念、Web 数据库。

用方向性增强生物医学关系提取
摘要生物关系网络包含丰富的信息,以了解基因,蛋白质,疾病和化学物质等实体关系背后的生物学机制。生物医学文献的广泛增长提出了更新网络知识的重大挑战。最近的生物医学关系提取数据集(Biored)提供了有价值的手动注释,从而促进了机器学习和预训练的语言模型方法的发展,以自动识别新颖的文档级别(阶段上下文)关系。尽管如此,其注释缺乏实体角色的方向性(主题/对象),这对于研究复杂的生物网络至关重要。在这里,我们注释了关系中关系的实体角色,随后提出了一种具有软提交学习的新型多任务语言模型,以共同识别关系,新发现和实体角色。我们的结果包括具有10,864个方向性注释的富集生物库。此外,我们提出的方法超过了现有的大型语言模型,例如最先进的GPT-4和Llama-3在两个基准测试任务上。我们的源代码和数据集可在https://github.com/ncbi-nlp/bioredirect上找到。联系人:zhiyong.lu@nih.gov

视频文本提示弱监督时空 -
弱监督时空的视频接地(STVG)旨在给定文本查询,而无需注释的训练数据,旨在将目标对象定位。现有方法通过从视频框架功能中裁剪对象,丢弃所有上下文信息,例如位置变化和实体关系,从而独立于每个候选管。在本文中,我们提出了视频文本提示(VTP)来构建候选功能。从特征图中裁剪管区域,我们绘制视觉标记(例如红色圆圈)作为视频提示上的对象管;相应的文本提示(例如在红色圆圈中)也被插入询问文本的主题单词后,以突出显示其存在。然而,如果没有作物,每个罐头特征都可能看起来相似。为了解决这个问题,我们通过引入负面的对比样本而不是删除候选对象而不是被强调的对比对比样本,进一步提出了Concon-Con-Concon-Conconvive VTP(CVTP);通过合并VTP候选人与对比样本之间的差异,正确候选者和其余部分之间的匹配分数差距被扩大。在几个STVG数据集上进行了广泛的实验和消融,我们的结果通过很大的边距超过了现有的弱监督方法,这证明了我们提出的方法的有效性。

使用化学和基因描述基于基于化学和基因描述的生物医学文献的采矿药物 - 目标相互作用
药物目标相互作用(DTI)在药物发现中起着关键作用,因为它旨在识别潜在的药物靶标并阐明其作用机理。近年来,自然语言处理(NLP)的应用,尤其是与预训练的语言模型相结合时,已经在生物医学领域中获得了相当大的势头,并有可能开采大量文本以促进DTIS从文献中有效提取。在本文中,我们将DTI的任务作为实体关系提取问题,利用不同的预训练的变压器语言模型(例如BERT)提取DTI。我们的结果表明,通过将来自Entrez基因数据库的基因描述与比较毒理基因组学数据库(CTD)的化学描述相结合,对于实现最佳性能至关重要。所提出的模型在隐藏的药品测试集中达到了80.6的F1得分,这是官方评估中所有提交模型中排名最高的性能。此外,我们进行了比较分析,以评估来自Entrez基因和Uniprot数据库的各种基因文本描述的有效性,以了解其对性能的影响。我们的发现突出了使用基因和化学描述来改善药物目标提取任务的基于NLP的文本挖掘的潜力。

教授加里玛·加伊
Aperia 不断发展,成为各行各业 ETL、BI 和托管解决方案的卓越提供商。Aperia 平台随行业发展而扩展,可按时处理大量数据。软件即服务 (SaaS) 平台支持数百万最终用户每天创建数十亿笔交易,且速度和可靠性均符合业务要求。 确保所有工件均符合公司 SDLC 政策和指南。 使用需求管理工具 Requisite Pro 准备 BRD 并将其转换为功能规范。 使用 MS Visio 创建 UML 图,例如用例图、活动图和序列图。 使用建模工具设计数据流图 (DFD)、实体关系图 (ERD) 和网页模型。 使用 MS Project 制定和维护项目计划。确保所有交付成果都能在截止日期前交付。 促进与个人、客户组和技术部门的 JAD 会议。 使用 MS Visio 执行面向对象分析 (OOA) 设计并开发工作流程图。 创建风险分析文档和风险管理计划。 进行功能演练并监督客户用户手册的开发。 为员工提供产品和应用程序培训。 维护变更请求文档并实施测试变更的程序。确保变更符合最终结果。 为用户验收测试 (UAT) 提供技术和程序支持。 北德克萨斯大学,德克萨斯州,美国 2009 年 1 月 - 2010 年 12 月 职位:研究分析师 1155 Union Circle Denton, TX 76203,美国

提出信息对象生命周期模型和符号
Johannes Damarowsky ( Johannes.damarowsky@wiwi.uni-halle.de ) 在信息系统研究中,对组织内的信息及其流动进行建模已经很成熟。然而,信息的一个视角尚未用标准化的模型符号来表示:组织内的信息对象生命周期。将客户主数据(如姓名、地址、电话号码、电子邮件地址、出生日期)等信息理解为信息对象 (IO) 是一种视角和工具,它与可以表示它的著名静态建模符号非常吻合,例如实体关系模型 (ERM) 或 UML 类图。UML 部署图或 The Open Groups ArchiMate 等符号可以指示客户主数据 IO 的数字表示位于组织 IT 基础架构中的何处,例如哪些数据库在哪些物理服务器上包含它。但是,IO 在其生命周期内的行为没有可用的专用建模符号。重要的 IO 生命周期行为至少包括:1) 初始创建(即创建新客户)、2) 读取(例如,店员读取客户数据)、3) 向其添加新数据字段(例如,第二个地址)、4) 修改现有数据(例如,更新电话号码)、5) 实例化(例如,在纸质表格上打印客户数据或在另一个系统中创建数字副本)、6) 移动、7) 读取或 8) 修改实例(例如,将包含客户数据的纸质表格交给阅读并签名的主管或将客户主数据发送给供应商)、9) 销毁物理或数字实例或初始创建的对象。在最先进的技术中,可以使用行为图(如 UML 活动、用例或序列图)和业务流程符号(如事件驱动流程链 (EPC) 或业务流程模型和符号 (BPMN))来建模 IO 操作,但 IO 生命周期本身并不是一个流程。因此,与 IO 生命周期相关的任务可以包含在多个流程模型中,并且可能仅间接或隐含地引用 IO,从而妨碍快速轻松地概览组织内 IO 的交互。这意味着机会成本,因为 IO 行为与组织信息、业务流程、合规性和信息安全管理相关。一种新颖的信息对象生命周期模型和符号 (IOLMN) 可以简化识别哪些部门记录或更新客户数据的过程,从而更容易识别错误信息的原因。还可以更容易地发现数据是否在多个部门独立记录和存储,这增加了数据存储不一致的风险。从合规性和信息安全的角度来看,可以更容易地识别哪些人对数据具有读取或写入权限,以及数据的实例在哪里创建以及它们可能最终在哪里。在发生安全漏洞的情况下,这样可以更轻松地识别哪些组织单位、流程和 IT 系统使用(读取、写入、修改等)IO 并可能受到影响。为了使 IOLMN 有用并轻松地实现对组织内 IO 的有用视角,它应至少包括 IO 属性、其(及其实例)生命周期行为、这些操作的时间和逻辑顺序和条件,以及涉及的人员、角色、部门、流程或 IT 系统及其对 IO 执行生命周期操作的授权。