XiaoMi-AI文件搜索系统
World File Search System工作部门

CRISPR-CAS9如何逐步工作
CRISPR-CAS9是编辑基因和基因组的强大工具。它使用引导的RNA在特定位置切割DNA,从而使研究人员可以操纵各种生物的基因组,包括动物,植物和微生物。基因编辑曾经被认为是科幻小说,但现在是现实。CRISPR-CAS9具有多种应用,包括创建遗传学的生物,治疗遗传疾病以及发展经济上重要的植物物种。有不同的方法来编辑基因,包括从生物体的基因组中插入,去除或删除序列。CRISPR-CAS9是为此目的最受欢迎的工具之一。它易于使用,高度准确且精确。该系统由核酸序列(CRISPR)和酶(CAS9)组成。需要一个引导的RNA(SGRNA)来促进目标特异性操作。CRISPR-CAS9系统于1987年首次由Ishino及其同事在1987年解释。在本文中,我们将使用简单的语言逐步解释该过程,以便初学者可以彻底理解它。我们不会从事科学写作,而要专注于外行术语的每个步骤。使用CRISPR-CAS9进行基因编辑的步骤是:1。选择实验2。选择目标基因位置3。选择并设计CRISPR-CAS9系统4。合成并克隆sgrna 5。交付sgrna和cas9 6。验证实验7。培养和分析替代细胞8。但是,其应用程序已扩展到各个字段。研究基因表达CRISPR系统首先用于研究基因敲除,其中从模型生物体中除去基因或DNA序列。通过遵循这些步骤,研究人员可以在实验室中执行基因编辑和基因工程。CRISPR-CAS9基因编辑:逐步指南我们将通过计算分析给定的基因,收集有关其序列,GC含量,表型和其他突变的数据。此信息将帮助我们设计带有指导的RNA来通过定位PAM序列来编辑基因。要选择一个用于沉默或去除的区域,我们必须选择适合我们实验要求的CRISPR-CAS9系统。提供不同的CAS蛋白,例如基因基因敲除,序列DCAS9的变化:激活和抑制以及其他诸如CAS13,Cas12,CSM,CMR和RNase III之类的其他。我们需要根据我们的需求选择正确的CAS9和CRISPR序列。CAS蛋白是一种可裂解单链和双链DNA的核酸酶。一个短的RNA序列(称为SGRNA或GRNA)可以通过靶向特定位置来编辑基因。sgrna有两个部分:具有互补的20个核苷酸的crRNA和识别Cas9的tracrocrrna环。一旦Tracrrna识别Cas,它就会将细胞核引导到裂口位置。,我们必须考虑到PAM序列的位置来计算设计SGRNA。一旦设计了GRNA,我们就需要将其合成并克隆质粒。我们的最先进的设施使我们能够在体外合成GRNA或SGRNA的寡聚。体外转录也有助于合成SGRNA。然后,我们选择一个特定的质粒,将GRNA基因插入其中,开发克隆,并分离从质粒表达的GRNA。现在我们的GRNA已合成,我们可以使用电穿孔方法将CAS9和SGRNA插入目标细胞中。我们还可以使用特定于CAS或病毒载体的mRNA,例如腺病毒,腺相关病毒,慢病毒和逆转录病毒。总体而言,CRISPR-CAS9基因编辑需要仔细的计划和执行。通过遵循这些步骤,我们可以使用这种强大的技术成功操纵基因。现在我们的CAS和SGRNA就在目标单元内,是时候验证敲除是否准确地发生了。用于验证的三种常见技术是聚合酶链反应(PCR),体外转录或DNA测序。DNA测序是在实验之前和之后进行的,使我们能够比较结果并确定是否已成功去除基因。PCR通过扩增从修饰细胞的目标序列来验证实验。此外,我们可以执行限制消化实验来验证结果。我们现在有了转基因细胞系,需要使用适当的培养基在无菌条件下培养它。一旦获得了足够量的细胞系,我们就可以将它们插入目标生物。注意:这是对CRISPR-CAS9机制的简化解释。Cas9核酸酶活性产生的差距不能保持未填充;取而代之的是,诸如非同源末端连接或直接DNA修复之类的DNA修复机制填补了空白。但是,我们的故事并没有结束。我们必须执行多个实验以检查改变的细胞的状态。基因表达研究是一种选择,我们在其中使用RT-PCR或定量PCR检查了所有细胞系改变基因的表达。可以在计算和物理上分析结果。计算工具有助于分析基因序列,表达谱等。体格检查有助于了解是否诱导了新的表型,是否仍然存在原始表型,或者结果不正确。此简短概述概述了在遗传实验室中进行CRISPR-CAS9实验的标准过程。但是,结果的特异性取决于我们选择的系统。如果我们选择了错误的CAS9,我们将无法实现所需的结果。SGRNA的设计也至关重要,因为如果不仔细设计,它可能会裂开未靶向区域。如果您有兴趣了解有关CRISPR-CAS9系统的更多信息,请从Addgene:CRISPR中阅读本文。与我们的新闻通讯一起呆在循环中,并包含最新的博客文章,发人深省的文章和重要的更新。另外,要第一个了解新产品和SNAG独家优惠!

工作机会
非洲联盟是一个独特的泛非洲大陆机构,被指控率领非洲的快速融合和可持续发展,通过促进非洲和非洲国家人民之间的统一,团结,凝聚力和合作以及在全球范围内建立新的合作伙伴关系。其总部位于埃塞俄比亚首都亚的斯亚贝巴。非洲疾病控制与预防中心(非洲CDC)于2017年1月31日在埃塞俄比亚的亚的斯亚贝巴正式启动。非洲疾病预防控制中心是非洲第一个范围内的公共卫生机构,并设想一个更安全,更健康,融合和更强大的非洲,成员国能够有效地应对传染病和其他公共卫生威胁的爆发。该机构的使命是通过通过整个大陆范围的准备和反应,监视,实验室和研究计划的综合网络来加强非洲公共卫生机构的检测和有效地对疾病暴发和其他健康负担的能力。

工作机会
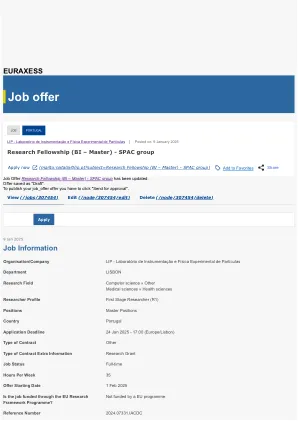
您的环境:该职位是Aquathermie项目的一部分,由塞纳河谷地区间区域计划合同资助,并得到法国生态过渡机构(ADEME),塞纳尼亚诺曼底水局,诺曼底和诺曼底和Qunele-de-de-France地区的支持,以及Normandy和Normandy and Normandy and of Normandy and of Normandy and for。Aquathermie是一个在水和能源利益相关者之间接口的项目,旨在使他们能够维持和开发自己的活动而无需争夺资源。Mines Paris-PSL,BRGM和Sorbonne University将其活动集中在人为和气候限制下的能源,水资源,环境和地球观察的十字架上,开发统计方法,机器学习和数学工具。您的挑战和责任:Aquathermie的目的是提高我们对高于200 m深度的地下水温度的过去和当前时空演化的理解,以为参与水生产,地热能利用和环境保护的利益相关者提供决策支持,考虑全球变化。它旨在在专用数据库中统一所有相关数据。基于此数据库,对该领土的定量评估(由地图和指标说明)将定义关键指标,以支持水和能源利益相关者的当前活动。此外,它将表征气候变化对中等和长期活动演变的影响。

在 Plural 工作
我在 Plural 以初级分析师的身份开始工作,最近晋升为助理。作为一名新加入者,我负责做基础工作(例如定量分析、访谈计划)并综合这些发现来推动团队的思考。随着项目一步步推进,我开始承担起责任,为团队的思考做出更多贡献。现在,我在大型项目中担任项目经理和分析师之间的关键纽带,或在小型项目中管理团队。

在 Plural 工作
1. 你所遇到的市场、行业、战略问题和疑问的多样性令人兴奋。我特别喜欢项目的开始和结束。一开始,你会了解项目的内容,每次都是不同的行业和公司。最后,看到一切都联系在一起,看到客户真正参与到你的辛勤工作中,真的很令人满意。2. 你的影响取决于项目。在商业尽职调查项目中,这可能是确保一家公司以合适的价格收购另一家公司。在战略项目中,可能是客户设法阻止了利润下滑。3. 员工是公司的粘合剂。这是一个令人难以置信的支持和友好的环境。如果你遇到困难,总会有人帮助你——无论他们有多忙。文化非常浓厚:有趣、社交和活跃,但不会排外或不适应环境。我们都热爱美食和音乐。我非常乐意和团队中的任何一个人共度时光——无论是在工作中还是在工作之外。

什么是机器学习以及如何工作
机器学习是人工智能的一部分,可以分析数据以对未来事件进行预测。此过程涉及诸如收集和准备数据,构建模型,培训它们,测试其准确性,可视化结果并将最终产品部署在金融,医疗保健,市场营销,教育等各个行业等步骤等。机器学习使用不同的算法和模型来了解复杂的数据,识别模式并做出明智的决定。由于神经网络和深度学习的进步以及大型数据集和复杂技术(例如自然语言处理,计算机视觉和增强学习)的可用性,近年来它变得越来越流行。该领域在各个领域都有许多应用程序,包括医疗保健,可以通过分析患者数据,在优化库存水平,减少欺诈和风险评估的地方进行融资,以及在其启用有针对性的广告的地方进行融资,在其中优化库存水平,融资,在此方面有助于诊断疾病。机器学习建立稳定业务的潜力是广泛的,这对于希望改善其运营的行业来说是必不可少的工具。机器学习可以分为四种主要类型:监督,半监督,无监督和强化学习。这些类型在使用数据的方式和为模型提供的指导级别上有所不同。例如,监督的学习使用标记的数据来训练模型,而无监督的学习依赖于未标记的数据来识别模式。关键概念,例如算法,模型,培训,测试等,在机器学习中起着至关重要的作用。通过实际示例理解这些概念,例如根据历史数据预测房价,可以为机器学习及其潜在应用的运作提供宝贵的见解。某些输入变量,例如房间平方英尺的数量等在确定住房价格算法中起关键作用错误代码实施遵循系统步骤,包括数据收集预处理模型培训评估部署数据收集质量收集质量可以确定准确性数据可以来自API网站社交媒体社交媒体社交媒体或构建的语言的道德注意事项,例如公平隐私等公平隐私应在脑海中保留数据中应在数据中置于数据预处理的范围,以提高较高的差异级别的差异级别的差异级别的质量质量质量质量质量质量质量质量的质量质量质量质量质量质量,使得质量质量质量质量质量,使得质量质量质量质量差异,远程质量的质量质量差异树木超参数调整改进准确性模型评估使用诸如精确度召回F1得分AUC交叉验证技术等指标来评估绩效,这有助于确定效率模型模型部署将训练有素的部署集成到解决其他步骤中,这些步骤涉及其他步骤,涉及可视化预测的准确性,以了解预测性能预测性模型在功能上促进了功能界定模型,并在功能上促进了多个计算模型。负责任的模型开发方法对于有效使用数据集至关重要。在部署过程中出现挑战:必须尊重数据隐私,算法必须是公正的,并且透明度对于代码解释性至关重要。必须通过抽样对人群进行公平表示,以防止数据和算法的偏见。模型解释性能够理解预测,而应考虑社会影响,因为机器学习可能会对社会产生正面或负面影响。数据匿名,加密和差异隐私等技术可以最大程度地减少偏见并保护用户隐私。总而言之,尽管机器学习提供了许多好处,但它需要仔细处理和考虑各种数据以防止偏见的结果。本文讨论了在各个领域负责使用机器学习模型的重要性,包括在部署期间面临的挑战和应观察到的道德实践。三种主要的学习类型包括受监督,无监督和强化学习,每个学习都解决了不同的问题。监督学习利用标记的数据,使模型可以学习模式并对新数据进行预测。监督学习的例子包括语音识别,医学诊断,欺诈检测和产品推荐系统。无监督的学习确定未标记数据中的模式,并根据相似性或差异组织。电子邮件中的异常检测是无监督学习的一个典型示例,该系统分析了大量数据以了解构成典型电子邮件的内容。在机器学习中,有多种方法,包括受监督和无监督的方法,每个方法都解决了独特的挑战和应用。通过承认这些差异并意识到潜在的偏见,开发人员可以创建有效和负责任的模型,从而使社会受益,同时最大程度地减少伤害。机器学习模型使用各种技术来检测欺诈,细分客户,提出内容建议并优化物流。无监督的学习有助于识别数据中的模式,而半监督的学习结合了标记和未标记的数据集,以提高准确性。强化学习涉及反复试验,系统通过与环境的互动进行学习并接收反馈以完善其策略。机器学习工作流程从数据收集,预处理,模型选择,培训,测试和评估开始。不同的算法专门从事不同的任务,并使用各种指标评估性能。高质量的数据和精心制作的功能对于提供有用的结果至关重要。机器学习算法提供了一系列解释选项,而其他人则需要其他计算资源。选择取决于所需的问题,数据类型和准确性。通常使用的算法包括线性回归,决策树,支持向量机,K-Nearest邻居,随机森林和神经网络。线性回归通过找到描述输入变量与输出变量之间关系的最佳拟合线来预测数值。决策树是基于是/否问题的直观模型,导致决定。支持向量计算机在数据集中找到最佳的边界。k-nearest邻居根据最接近的邻居的多数类对新数据点进行分类。随机森林结合了多个决策树的输出,或选择大多数投票进行分类和回归。幼稚的贝叶斯假定所有特征都是独立的,并应用了贝叶斯定理以基于概率的分类。神经网络处理像人脑一样的数据,分析大型数据集中的模式。机器学习算法提供可扩展性,自动化,通过数据驱动的见解增强的决策以及解决复杂问题的潜力。数据质量问题,例如培训数据中的不准确和偏见,可能会严重影响模型性能和可靠性。此外,过度拟合和不足的问题是常见问题,在这些问题中,模型变得过于专业或过于简单,导致预测不良。此外,机器学习引起了道德和隐私问题,尤其是在使用敏感的个人数据时。这包括偏见,公平,透明度和潜在的滥用。机器学习的现实应用在各个行业中都广泛。在医疗保健中,通过模式分析和个性化治疗计划,机器学习有助于早期疾病检测。财务将其用于实时安全系统和信用评分来确定借款人的信誉。电子商务平台利用机器学习用于推荐系统,库存管理和客户服务聊天机器人。自动驾驶汽车依靠深度学习模型进行传感器数据处理,而预测维护则在车辆性能数据分析中用于检测机械故障。机器学习在各个行业中都普遍存在,扩大了其影响力并引起人们对那些能够利用其潜力的人们的兴趣。为了从事这一领域的职业,锡拉丘兹大学的iSchool通过其应用数据分析计划(包括学士学位和未成年人)提供了理想的基础。另外,学生可以探索高级选项,例如人工智能或应用数据科学的硕士学位。这些计划提供了必要的知识,工具和动手经验,以做出有意义的贡献。尽管机器学习算法可以适应,但人类专业知识对于指导其发展是必不可少的。



COVID-19如何工作
在注射现场获得疫苗后,您可能会经历副作用,包括发烧,发冷,疲倦,头痛或酸痛/肿胀。这种疫苗可以打起一拳 - 但这意味着它正在努力使您的身体准备防御Covid-19。