XiaoMi-AI文件搜索系统
World File Search System平均线

昏暗:用于机器翻译的迭代非Aut-Autore-ReRoRe-ReReRexression Transformer的多个步骤
随着解码步骤的数量增加,迭代非自回旋变压器的计算益处减小。作为一种补救措施,我们介绍了DI仍然是Untiple S Teps(Dims),这是一种简单而有效的蒸馏技术,以减少达到一定的翻译质量所需步骤的数量。截止的模型享有早期迭代的计算益处,同时从几个迭代步骤中保留了增强性。暗示着两个模型,即学生和老师。在多个解码步骤后,在老师通过缓慢移动的平均值跟随学生的同时,对学生进行了优化,以预测老师的输出。移动平均线使教师的知识更新,并提高了老师提供的标签的质量。在推断期间,学生用于翻译,并且不添加其他构成。我们验证了DIMS对在WMT'14 DE-EN的蒸馏和原始验证上获得7.8和12.9 BLEU点改进的各种模型的有效性。此工作的完整代码可在此处提供:https://github.com/ layer6ai-labs/dims。

将人工智能融入情绪和行为研究中
摘要 大多数关于科学教育中情绪和行为的研究都使用了观察性或陈述性方法。这些方法具有某些优势,但它们对于深化我们对情感领域的理解具有重要的局限性。在这项工作中,我们开发了一种使用识别面部表情的人工智能系统分析探究活动期间情感变量动态的方法。虽然这项研究针对 12 名学生进行,但在这里我们分析了一个人的数据来详细描述该方法。使用输出行为和情绪信号的软件处理视频。为了分析它们,我们应用了不同宽度的中心移动平均线。这使我们能够调整和解释情绪、行为和学习行动的动态。当学生似乎实施了他们的模型并且他们的预测没有得到满足时,我们发现惊讶的峰值。我们的分析表明,探究式活动存在四个阶段,且具有特定的动态特征。这项工作为研究人员和教师开发监测情绪和行为的工具奠定了基础。

哥伦布地区经济概况 (PDF)
来源:JobsEQ® 数据截至 2023 年第三季度,除非另有说明 注:由于四舍五入,数字可能不相加。 1. 除非另有说明,数据基于四个季度的移动平均线。 2. 工资数据代表所有涵盖就业的平均值 3. 数据代表所选地区过去三十天内活跃的在线广告。 由于其他县分配算法,此分析中的广告数量可能与 RTI(或弹出窗口广告列表中)中显示的广告数量不匹配。 基于 ZCTA 的区域的广告数量是估计值。 职业就业数据是通过行业就业数据和估计的行业/职业组合估算的。 行业就业数据来自劳工统计局提供的《就业和工资季度普查》,目前已更新至 2023 年第二季度,并在必要时进行估算,初步估计已更新至 2023 年第三季度。按职业划分的工资截至 2023 年,由劳工统计局提供,并在必要时进行估算。预测就业增长使用了劳工统计局根据区域增长模式做出的国家预测。

不确定电力市场中家用热泵的随机能量优化
可再生能源在世界各地电力系统中的渗透率正在提高。由于可再生能源的间歇性和波动性,需求侧管理是克服这一问题的实用解决方案。本文提出了一种用于热泵的随机模型预测控制,用于为住宅建筑提供空间供暖和生活热水消耗。连续时间随机模型用 R 语言编写,以解决模型识别方法。该方法使用家庭的传感器数据来提取建筑物的热动态。控制器参与可再生能源渗透率高的三层电力市场。建议采用三阶段随机规划,分别在日前、日内和平衡市场中,在长期、中期和短期提前通知下解锁电热灵活性。考虑到可再生能源可用性与电价之间的密切相关性,价格数据通过自回归综合移动平均线建模为概率场景。环境温度以及生活热水消耗被视为具有上限和下限的包络边界。最后,在一座 150 平方米的测试房屋中,在电价、天气变量和占用模式不确定的情况下,检查控制器的运行策略。

伊利诺伊州杜佩奇县 - 经济概述
来源:截至2021q2起的JobSeq®数据,除非另有说明要注意:数字可能不会因舍入而汇总。1。基于四分之三移动平均线的数据,除非另有说明。2。工资数据截至2020数据表示在所选区域的最后三十天内在线广告中发现的广告;数据代表一个抽样而不是完整的帖子宇宙。广告缺乏邮政编码信息,但指定一个地方(城市,城镇等)可以在该分析中的查询中最大的就业机会分配给邮政编码。由于替代性县分配算法,此分析中的AD计数可能与RTI中所示的不匹配(在弹出窗口广告列表中也不匹配)。职业就业数据是通过行业就业数据和估计的行业/职业组合估算的。行业就业数据来自劳工统计局提供的就业和工资的季度人口普查,目前通过2021Q1进行更新,必要时估算到2021q2的初步估计。按职业工资截至2020年,由BLS提供,并在必要时估算。预测就业增长使用了适用于区域增长模式的劳工统计局的国家预测。
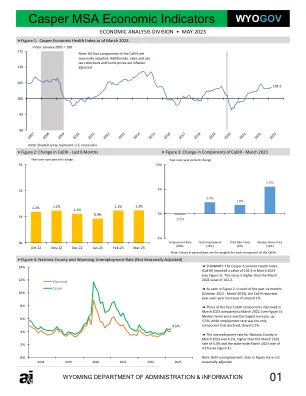
卡斯珀 MSA 经济指标
方法:从 2005 年 1 月开始,上述各组成部分的每个系列都进行了标准化,因此每个组成部分和 CaEHI 的值均为 100。随着每个组成部分每月的变化,CaEHI 值也会发生变化。接下来,计算每个组成部分标准化系列值的标准差,然后计算每个组成部分标准差的倒数。最后,对各个倒数标准差进行标准化,从而得出总和为 1 的权重。这种加权方法的原理是,随着时间的推移,更稳定的组成部分的标准差较小,因此倒数标准差和权重较大。通常稳定的数据系列的大幅变化比通常波动较大的数据系列的大幅变化更能表明经济发生了变化。因此,这种加权方法允许 CaEHI 对更稳定的组成部分赋予更大的权重,这样,如果它们确实经历了大幅变化,CaEHI 的值将受到更大的影响,以代表该县经济状况的变化。最后,使用 3 个月移动平均线来平滑指数。这有助于消除由于某个成分在特定月份记录异常高或低值而可能出现的大“峰值”。

东德克萨斯州经济概述 流感疫苗豁免 烹饪化学教学大纲 - 春季25 亨德森县经济概述2024 Hibbs简介 烹饪化学课程 2024财政年度内部审计年度报告
来源:截至2022q2起的JobSeq®数据,除非另有说明说明:由于四舍五入,数字可能不会汇总。1。基于四分之三移动平均线的数据,除非另有说明。2。工资数据截至2021年,代表了所有涵盖工作的平均值3。数据表示在所选区域的最后三十天内在线广告中发现的广告;数据代表一个抽样而不是完整的帖子宇宙。广告缺乏邮政编码信息,但指定一个地方(城市,城镇等)可以在该分析中的查询中最大的就业机会分配给邮政编码。由于替代性县分配算法,此分析中的AD计数可能与RTI中所示的不匹配(在弹出窗口广告列表中也不匹配)。职业就业数据是通过行业就业数据和估计的行业/职业组合估算的。行业就业数据来自劳工统计局提供的就业和工资的季度人口普查,目前通过2022Q1进行更新,必要时估计,预估计更新为2022q2。按职业的工资截至2021年,BLS提供了,并在必要时估算。预测就业增长使用了适用于区域增长模式的劳工统计局的国家预测。
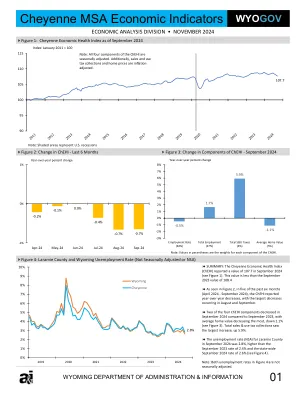
夏延 MSA 经济指标 WYOGOV
方法:从 2005 年 1 月开始,上述各组成部分的每个系列都进行了标准化,因此每个组成部分和 ChEHI 的值均为 100。随着每个组成部分每月的变化,ChEHI 值也会发生变化。接下来,计算每个组成部分标准化系列值的标准差,然后计算每个组成部分标准差的倒数。最后,对各个倒数标准差进行标准化,得出总和为 1 的权重。这种加权方法的原理是,随着时间的推移,更稳定的组成部分的标准差较小,因此倒数标准差和权重较大。通常稳定的数据系列的大幅变化比通常波动较大的数据系列的大幅变化更能表明经济发生了变化。因此,这种加权方法允许 ChEHI 赋予更稳定的组成部分更大的权重,这样,如果它们确实发生了大幅变化,ChEHI 的值将受到更大的影响,以代表该县经济状况的变化。最后,使用 3 个月移动平均线来平滑指数。这有助于消除由于某个成分在特定月份记录异常高或低值而可能出现的大“峰值”。

股票市场中的人工智能
人工智能发展迅速,算法也越来越复杂,准确性也日益提高。即使如此,股票市场的人工智能仍然在使用交易员长期以来使用的相同基本概念。最新技术强调通过神经网络进行多层分析,但底层概念包括平均值、最小值、中位数、众数、正态性、偏度、峰度、平稳性等。除此之外,在编写这些算法时还会吸收技术交易中使用的指标。其中一些是:1. 简单移动平均线 (SMA) - 即使是最简单的概念(如 SMA)也用于人工智能,其中平均选定的价格范围,即在一定时期内(可能是 10 天、一个月或几年)的收盘价。它主要用于确定资产在特定时间范围内是呈现看涨趋势还是看跌趋势。 2. 最高-最高、最低-最低——尽管最高-最高和最低-最低仅仅是股票价格的图形分析,并不能准确预测未来,但人工智能仍会使用它作为分析股票市场的其他复杂指标的基础。它主要由算法使用,为用户提供更准确的进入和退出点。 3. 布林带——这是另一种统计图表,以图表移动平均价格以下和以上的标准偏差包裹股票价格图表。它考虑到

通过人工智能社会创新解决无家可归问题:采用 ARIMA 和 LSTM 等预测分析和机器学习模型,对洛杉矶无家可归人群的犯罪受害情况进行新颖且具有突破性的评估
无家可归是一个世界性的问题,近年来洛杉矶 (LA) 的无家可归者数量急剧增加。尽管已经开展了多项研究来调查无家可归的各个方面及其与犯罪受害的交集,但没有一项研究使用机器学习技术来分析无家可归与无家可归者受害之间的关系。为了更好地了解无家可归者受害的影响,我们整合了从联邦、州和市政府机构获得的三个数据集,创建了一个统一的数据集,得出了重要的发现。特征工程用于引出无家可归不同维度之间的关系。基于提取的特征,机器学习技术用于模拟无家可归者的受害情况。我们的研究结果表明,洛杉矶无家可归者受害与种族、性别、年龄和社区划分密切相关。鉴于本研究的主要目标是帮助社会服务机构实施社会创新,我们应用了两种复杂的机器学习方法来预测无家可归者的未来:自回归综合移动平均线 (ARIMA) 和长短记忆网络 (LSTM)。这两个模型都从不同角度进行了训练,以预测未来两年内犯罪热点地区以及弱势群体的性别、种族和年龄组。最后,向各部门和政府机构提出了一些社会改进建议,以改善针对无家可归犯罪受害者的服务和项目。