XiaoMi-AI文件搜索系统
World File Search System并行
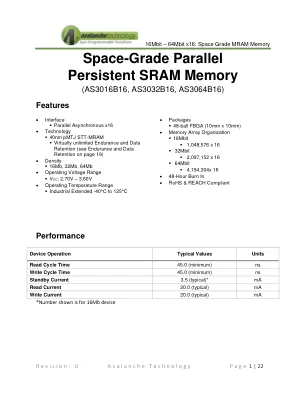
太空级并行持久性 SRAM 存储器
非易失性 − √ √ √ 写入性能 √ − − √ 读取性能 √ − − √ 耐久性 √ − − √ 功率 − − − √ MRAM 是一种真正的随机存取存储器;允许在内存中随机进行读取和写入。MRAM 非常适合必须存储和检索数据而不会产生较大延迟的应用程序。它提供低延迟、低功耗、无限耐久性、高性能和可扩展的内存技术。AS30xxB16 采用小尺寸 48 球 FBGA(10 毫米 x 10 毫米)封装,支持 16Mb、32Mb 和 32Mb 密度。此封装与类似的低功耗易失性和非易失性产品兼容。AS30xxB16 提供工业扩展(-40°C 至 125°C)工作温度范围。每个单元在发送给客户之前都要经过 48 小时的老化。

哈密顿模拟的并行量子算法
我们研究并行性如何加速量子模拟。提出了一种并行量子算法来模拟一大类具有良好稀疏结构的汉密尔顿量的动力学,这些汉密尔顿量称为均匀结构汉密尔顿量,其中包括局部汉密尔顿量和泡利和等各种具有实际意义的汉密尔顿量。给定对目标稀疏汉密尔顿量的 oracle 访问,在查询和门复杂度方面,以量子电路深度衡量的并行量子模拟算法的运行时间对模拟精度 ϵ 具有双(多)对数依赖性 polylog log(1 /ϵ )。这比以前没有并行性的最优稀疏汉密尔顿模拟算法的依赖性 polylog(1 /ϵ ) 有了指数级的改进。为了获得这个结果,我们基于 Childs 的量子行走引入了一种新的并行量子行走概念。目标演化幺正用截断泰勒级数近似,该级数是通过并行组合这些量子行走获得的。建立了一个下限Ω(log log(1 /ϵ )),表明本文实现的门深度对ϵ 的依赖性不能得到显著改善。我们的算法被用来模拟三个物理模型:海森堡模型、Sachdev-Ye-Kitaev 模型和二次量子化的量子化学模型。通过明确计算实现预言机的门复杂度,我们证明了在所有这些模型上,我们的算法的总门深度在并行设置下都具有 polylog log(1 /ϵ ) 依赖性。

航天级并行持久性 SRAM 存储器
非易失性 − √ √ √ 写入性能 √ − − √ 读取性能 √ − − √ 耐久性 √ − − √ 功率 − − − √ MRAM 是一种真正的随机存取存储器;允许在内存中随机进行读取和写入。MRAM 非常适合必须存储和检索数据而不会产生较大延迟的应用程序。它提供低延迟、低功耗、高耐久性、高性能和可扩展的内存技术。AS3xxx332 采用小尺寸(15mm x 17mm)142 球 BGA 封装。在 1、2、4Gb 密度下,该设备使用一个芯片选择 E#。在此配置中,形成一个 1、2、4Gb 的连续地址空间。在 8Gb 配置中,该封装有两个 4 个芯片组,每个芯片组可单独选择,但不能同时选择。每个芯片组可使用 E1# 和 E2# 选择。在 8Gb 配置中,不得同时选择 E1# 和 E2#,因为两个组共享相同的 I/O 引脚。AS3xxx332 提供工业扩展(-40°C 至 125°C)工作温度范围:这是以结温测量的。

基于并行局部最小值的相位展开方法……
摘要:考虑数据可靠性,用于相位不连续性重构的对偶残差优化连接提供了更可靠的方案并产生了更稳健的解缠结果。然而,它们的实际实现通常涉及耗时的迭代全局操作,不适合应用于大块干涉合成孔径雷达(InSAR)相位数据的相位解缠(PU)。提出了一种基于局部最小可靠性对偶扩展的并行PU方法。在给定质量权重图的情况下,基于残差定义对偶可靠性,并引入最小可靠性残差对来表示可能的不连续边界。我们提供了一种具有局部最小可靠性搜索和对偶合并的对偶动态扩展方法。最终获得的最小平衡树用于在可靠性图的帮助下对PU进行路径集成。可靠性图的计算、残差对搜索和动态扩展被设计为并行进行。我们采用基于艾科纳方程和洪水填充的界面传播方案进行并行实现。采用所提方法处理了两大块机载 InSAR 数据,实验结果和分析验证了该方法对大规模 PU 问题的鲁棒性和有效性。© 作者。由 SPIE 根据 Creative Commons Attribution 4.0 Unported 许可证发布。分发或复制
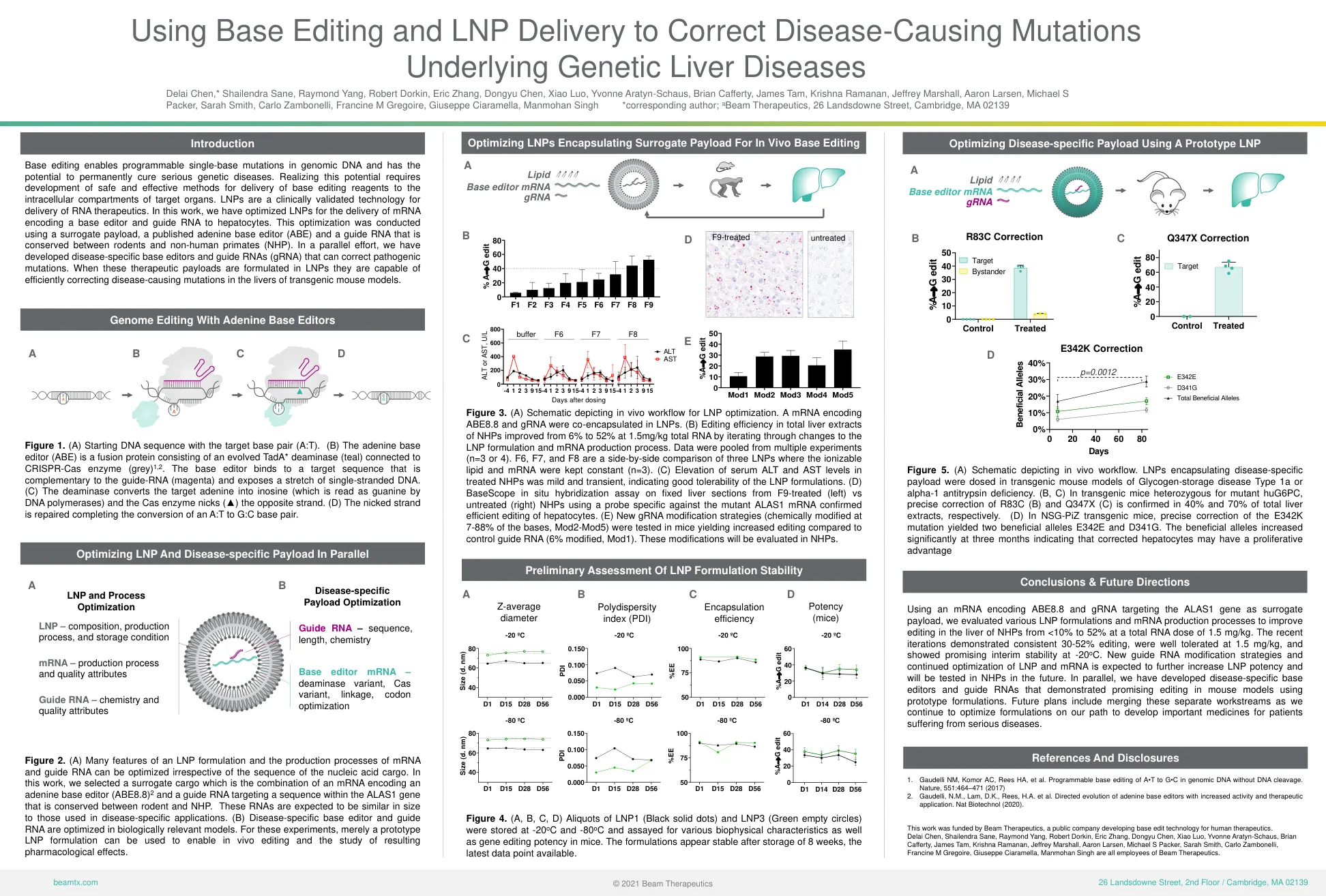
并行优化LNP和特定疾病的有效载荷...
基础编辑可以使基因组DNA中可编程的单基碱基突变,并有可能永久治愈严重的遗传疾病。意识到这一潜力需要开发安全有效的方法,以将基础编辑试剂传递到目标器官的细胞内隔室。LNP是一种经过临床验证的RNA疗法的技术。在这项工作中,我们优化了LNP,用于传递编码基本编辑器的mRNA,并将RNA引导至肝细胞。使用替代有效载荷,已发表的腺嘌呤基本编辑器(ABE)和在啮齿动物和非人类灵长类动物(NHP)之间保守的指导RNA进行了优化。在平行的努力中,我们开发了疾病特异性的基础编辑器和指导RNA(GRNA),可以纠正致病性突变。当这些治疗有效载荷是在LNP中提出的,它们能够在转基因小鼠模型的肝脏中有效纠正引起疾病的突变。

通过相干动力学的大规模并行经典逻辑......
B. 激发导致零级激子态,每个点由两个空穴态(h1 和 h2,蓝色条)和一个电子态(e,红色条)组成。可以构建 8 个激子态,4 个局部激子,即 h1eA(顶行),其中空穴-电子对位于同一点上(激发用直线表示)和 4 个电荷转移,即 h1A-eB,(CT 态,底行),其中空穴和电子位于不同的点上(激发用曲线表示)。C. 异质结的本征激子态

有效的量子并行重复定理和应用程序
我们证明了3台计算量子量子交互协议与有效的挑战者和有效对手之间的紧密平行重复定理。我们还证明,在合理的假设下,在并行重复下,4台式计算协议的安全性通常不会降低。这些反映了Bellare,Impagliazzo和Naor的经典结果[BIN97]。最后,我们证明所有量子参数系统都可以一致地编译到等效的3-序列参数系统,从而反映了量子证明系统的转换[KW00,KKMV07]。As immediate applications, we show how to derive hardness amplification theorems for quantum bit commitment schemes (answering a question of Yan [ Yan22 ]), EFI pairs (answering a question of Brakerski, Canetti, and Qian [ BCQ23 ]), public-key quantum money schemes (answering a question of Aaronson and Christiano [ AC13 ]), and quantum零知识参数系统。我们还为量子谓词推导了XOR引理[YAO82]作为推论。

LU-2023 TEC-SYE - 系统工程与并行空间任务设计
任务概述:技术、工程和质量局系统工程处负责以下主要活动:• 为 ESA 项目提供成本工程支持、工具和估算;• 为处于各个开发阶段的项目提供系统工程支持;• 开展与系统工程方法和工具有关的研发活动;• 管理和为小型航天器项目提供技术演示的技术支持,包括准备活动(可行性研究、预开发等);• 管理和为小型在轨技术演示项目提供技术支持(仪器、有效载荷等);• 管理并行设计设施(CDF)并执行 ESA 项目的第 0 阶段和支持活动。

空间:Vlasov-Maxwell 和 Vlasov-Poisson 的 3D 并行求解器
本报告是由美国政府某个机构资助的工作报告。美国政府或其任何机构、其雇员、承包商、分包商或其雇员均不对所披露信息、设备、产品或流程的准确性、完整性或任何第三方的使用或此类使用结果做任何明示或暗示的保证,或承担任何法律责任或义务,或表示其使用不会侵犯私有权利。本文以商品名、商标、制造商或其他方式提及任何特定商业产品、流程或服务,并不一定构成或暗示美国政府或其任何机构、其承包商或分包商对其的认可、推荐或支持。本文表达的作者的观点和意见不一定代表或反映美国政府或其任何机构的观点和意见。

采用并行前缀加法器的高速乘法器设计
1. 引言 VLSI 技术在速度和尺寸方面的进步使得实现并行乘法器硬件成为可能。技术发展进一步确保了更好的性能特征和在 DSP 系统中的广泛使用。它执行诸如累加多个乘积之和之类的操作的速度比普通微处理器快得多。DSP 架构旨在执行并行操作,从而降低计算复杂性并提高此类应用中重复信号处理所需的速度[1]。这些功能旨在提高可编程 DSP 的速度和吞吐量。对于给定的应用,有大量可编程 DSP 可供选择,具体取决于速度、吞吐量、算术能力、精度、规模、成本和功耗等因素[2]。单芯片乘法器的引入及其与微处理器架构的结合是能够实现 DSP 功能的商用 VLSI 芯片面市的最重要原因[3]。并行前缀加法器被认为是最有效的二进制加法电路。它们的规则结构和快速性能使得它们特别适合实现 VLSI[4]。数字的乘积生成需要一个处理器周期。无论是基于软件的移位和加法算法,还是一个