XiaoMi-AI文件搜索系统
World File Search System并行计算

并行计算
在研究生物神经网络等复杂动态系统时,模拟是继实验和理论之后的第三大支柱。当代脑规模网络对应于几百万个节点的有向随机图,每个节点的入度和出度为几千条边,其中节点和边分别对应于基本生物单位、神经元和突触。神经元网络中的活动也很稀疏。每个神经元偶尔会通过其传出突触向相应的目标神经元发送一个短暂的信号(称为尖峰)。在分布式计算中,这些目标分散在数千个并行进程中。空间和时间稀疏性代表了传统计算机上模拟的固有瓶颈:不规则的内存访问模式导致缓存利用率低。使用已建立的神经元网络模拟代码作为参考实现,我们研究了恢复缓存性能的常用技术(例如软件诱导预取和软件流水线)如何使实际应用程序受益。算法更改可将模拟时间缩短高达 50%。该研究表明,分配了本质上并行计算问题的多核系统可以缓解传统计算机架构的冯诺依曼瓶颈。

CMSC416:并行计算简介...
指标类型是评估各个领域的程序性能的重要工具。 “解决方案的时间”和“每个设置时间(迭代)”指标提供了有关完成程序内特定任务或迭代的效率的见解。这些指标对于了解程序如何迅速提供结果至关重要。诸如“科学进步”之类的指标通过量化在给定时间范围内实现有意义的科学结果的速度来提供更细微的观点。该指标在研究和科学计算环境中特别相关,在研究和科学计算环境中,发现的步伐至关重要。 “每秒浮点操作(flop/s)”和数据点之间的比较(例如加速和效率)提供了对程序的计算效率的见解。通过测量数学操作的速率或比较通过并行化获得的绩效提高,这些指标有助于优化程序执行。尽管它们多样性,但这些指标统称有助于理解计划绩效的速度和有效性,从而为优化和决策提供了宝贵的见解。数据收集完成后,下一步涉及分析关键性能指标(KPI),例如峰值失败/s,峰值存储器带宽和峰网络带宽。这些指标提供了有关系统的最大计算和数据传输功能的见解。但是,由于各种因素,实现峰值性能通常难以捉摸。实际上,实际性能通常范围从广告上的峰值性能的20%到40%不等。峰值性能代表了系统性能的理论上限,通常由硬件制造商宣传。上下文在确定可实现的绩效水平方面起着至关重要的作用;例如,在深度学习应用中,性能接近峰值的60%至80%是可行的。沟通效率,硬件体系结构和工作量特征等因素会影响性能结果。了解绩效限制背后的原因对于有效优化系统性能至关重要。虽然达到峰值性能并不总是可行的,但是识别和解决性能瓶颈可能会导致总体效率和有效性的显着提高。识别和解决绩效问题对于优化程序执行和最大化计算效率至关重要。常见的性能问题包括串行代码性能瓶颈,效率低下的内存访问以及无效的浮点操作。要解决这些问题,可以采用几种策略:


大规模并行计算:算法和应用
现代时代目睹了将构造扩展到大型数据集的能力的革命。可伸缩性的关键突破是引入快速且易于使用的分布式编程模型,例如MapReduce(Dean和Ghemawat,2008年),Hadoop(Hadoop.apache.org)和Spark(Spark.apache.org)。我们将这些编程模型称为大规模并行框架。大规模并行框架最初是针对相对简单的计算类型设计的,例如计算数据集中的单词频率。从那以后,它们被证明对更丰富的应用程序非常有用。最近的工作目的是以释放其真正的潜在力量并扩大其适用性来研究这些框架算法。希望通过算法研究,取得与诸如合规算法等主题相似的成功(Frigo等人。,2012年)和数据流算法(McGregor,2014年)。实际上,大量分布式框架使程序员能够轻松地将算法在数十万台上部署到数千台机器。算法,这些框架对其计算表达能力有限制,以帮助确保程序有效地平行。

实时决策的并行计算框架 -
可扩展和自适应深度学习算法已成为处理巨大数据集并克服慢速计算模型的局限性的变革性。的技术,例如分布式梯度下降和模型并行性授权学习系统有效地扩展而不会降低性能。这些方法优化了分布式系统中的资源分布,从而有效地处理了复杂的数据模式。自适应算法根据输入数据动态修改其体系结构,提供稳健性和灵活性 - 在天气预测和财务建模应用程序中实时决策的临界属性。此外,增强学习和联合学习通过减少对集中数据存储和处理的依赖来增强可伸缩性和概括性[1]。

并行计算模式下的传感器生物医学信号采集
摘要:有几种病症会攻击中枢神经系统,每种病症都有不同的治疗方法。这些治疗方法尽可能地减少或抵消这些类型的病症和疾病对患者造成的后果。因此,神经康复疗法提供了全面的神经护理,以提高患者的生活质量并促进他们在社会中的表现。了解神经康复疗法如何帮助患者的一种方法是通过脑电图 (EEG) 测量他们的大脑活动变化。EEG 数据处理应用程序已在神经科学研究中使用,具有高度计算和数据密集型。我们的提案是一个集成的脑电图、心电图、生物声学和数字图像采集分析系统,为神经科学专家提供工具来评估各种疗法的效率。该提案的三个主要轴是:并行或分布式捕获、生物医学信号的过滤和调整以及实际采样时期的同步。因此,本提案奠定了一个通用系统的基础,该系统的主要目标是成为该领域的无线基准。通过这种方式,该提案可以获得并提供一些生物医学信号的分析工具,用于测量大脑在治疗期间受到外部系统刺激时的相互作用。因此,该系统在必要时支持极端环境条件,从而扩大了其应用范围。此外,根据研究需要,可以根据本提案添加或删除传感器,从而产生受 CPU 内核数量限制的广泛配置,即生物传感器越多,所需的 CPU 内核就越多。为了验证所提出的集成系统,它被用于海豚辅助治疗,用于治疗婴儿脑瘫和强迫症患者以及神经典型患者。样本周期的事件同步有助于隔离相同的治疗刺激,并允许通过功率谱或分形几何等工具对其进行分析。


05 EES 141 电力系统仪表 05 EES ...
并行算法用于负载流分析、故障分析、意外事件评估和暂态稳定性研究。20 小时。参考书目:1. Vipin Kumar、Ananth Grama、Anshul Gupta 和 George Karypis - 并行计算简介 - 算法设计和分析,Benjamin/Cummings 出版公司,1994 年。2. MJQuinn - 并行计算 - 理论与实践,McGraw-Hill 出版公司,1994 年。3. Kai Hwang - 高级计算机体系结构 - 并行性、可扩展性、可编程性、

PCSE-2023
E&IG,BARC和董事长(PCSE ’23)主任S. Mukhopadhyay博士发表了讲习班的欢迎地址。 在他的就职演讲中,BARC主管A. K. Mohanty博士提倡高性能计算的需求,其中主要包括基于CPU-GPU的并行计算和量子计算,以解决复杂的域问题。 他进一步强调了在开发内部“ Exascale”计算设施的努力中,用户社区与高性能计算机的开发人员之间进行了强有力的合作。 研讨会的会议记录由Barc董事发布。 SK博士表示感谢的投票。 Musharaf Ali,头,AMCAS,CHED和召集人(PCSE ’23)。 大约有135名来自DAE和非DAE机构的代表参加了研讨会。 在研讨会上的9个邀请讲座涵盖了并行计算和量子计算的各个方面,包括在Petaflop上应用计算能力和Exaflop量表在物理,化学,生物学和工程中使用。E&IG,BARC和董事长(PCSE ’23)主任S. Mukhopadhyay博士发表了讲习班的欢迎地址。在他的就职演讲中,BARC主管A. K. Mohanty博士提倡高性能计算的需求,其中主要包括基于CPU-GPU的并行计算和量子计算,以解决复杂的域问题。他进一步强调了在开发内部“ Exascale”计算设施的努力中,用户社区与高性能计算机的开发人员之间进行了强有力的合作。研讨会的会议记录由Barc董事发布。SK博士表示感谢的投票。Musharaf Ali,头,AMCAS,CHED和召集人(PCSE ’23)。大约有135名来自DAE和非DAE机构的代表参加了研讨会。在研讨会上的9个邀请讲座涵盖了并行计算和量子计算的各个方面,包括在Petaflop上应用计算能力和Exaflop量表在物理,化学,生物学和工程中使用。
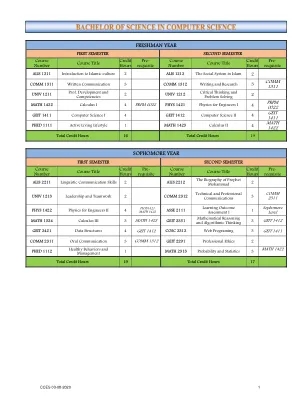
计算机科学学位计划.pdf
数据科学:………… COSC4381 数据科学简介、COSC4382 机器学习、COSC4383 数据可视化、COSC4384 商业智能与分析、COSC4311 并行计算。游戏开发:COSC4377 计算机图形脚本与编程、COSC3359 计算机动画、COSC4378 3D 计算机建模、COSC4379 游戏架构与设计、COSC4371 计算机图形。通用计算机科学:COSC3354 密码学概论、COSC4371 计算机图形学、ITAP3313 用户界面开发、COSC3359 计算机动画、COSC3357 逻辑与形式验证、COSC4373 计算机视觉、COSC4352 软件工程中的形式化方法、COSC4372 分布式系统与算法、COSC4376 生物信息学、COSC4380 量子信息与计算、COSC4393 特殊主题、COSC4311 并行计算、COSC4364 编译器、ITAP4371 电子商务、ITAP3371 数据库 II