XiaoMi-AI文件搜索系统
World File Search System引出

一般金融经济均衡
摘要 在给定价格的情况下,不确定的需求和供给可能无法等同于定义均衡。然后通过将市场建模为吸收清算风险的抽象代理来制定新的均衡概念。新的均衡援引可接受风险理论来定义称为一般金融经济均衡 (GFEE) 的双价格均衡。市场为每种商品设定两个价格,一个是买入价格,另一个是卖出价格。这两个价格是通过将总随机净库存和净收入敞口设定为可接受风险来确定的。对于 n − 商品经济,有 2 n 个价格的均衡方程。然而,由于所有方程不能同时满足一般均衡,因此定义并说明了一种均衡近似,即在确定 2 n 个价格时最小化与均衡的偏差。引入双价劳动力市场自然会引出均衡失业率和均衡失业保险率的概念。结果表明,失业率随着经济生产力的提高而上升,可以通过扩大产品数量来缓解。观察到伴随产品扩张的技术创新对就业是中性的,并且为社会所接受。同样,从收入规模的上端向中端或下端的再分配策略可以通过对总需求的影响来降低均衡失业水平。像 COVID 这样的生产力冲击导致更高的均衡失业支持水平,以失业者与就业者的收入比率来衡量。增加的幅度取决于劳动力市场风险的可接受水平。对技能差异化劳动力市场的分析表明,在 GFEE 中通过失业补偿来支持收入和总需求是合理的。关键词:可接受风险、扭曲预期、均衡失业、均衡失业保险。 JEL 分类:D50、D51、D58
人工智能与人类医生在分诊诊断方面的比较研究
简介与背景。AI 虚拟助手具有巨大潜力,可帮助患者自我评估症状并在适当时寻求进一步治疗,从而减轻医疗系统负担过重的压力。为了使这些系统对全球医疗保健做出有意义的贡献,它们必须得到患者和医疗专业人员的信任,并满足不同地区和不同人群患者的需求。我们基于概率图模型 (PGM) 开发了 AI 虚拟助手,并证明它能够为患者提供分类和诊断信息,其临床准确性和安全性可与人类医生相媲美。重要的是,此次评估评估了 AI 和人类医生的准确性和安全性,并且与之前的研究不同,它还考虑了两种代理的信息收集过程 [ 1 , 2 ]。通过这种方法,我们希望通过直接将人工智能系统的表现与人类医生进行比较,建立对人工智能系统的信任,因为人类医生并不总是同意患者症状的原因或最合适的分诊建议。至关重要的是,该系统基于生成模型,允许相对直接的重新参数化,以反映不同地区和人口群体的当地疾病负担。这是一个很有吸引力的特性,特别是考虑到人工智能虚拟助手有可能在全球范围内改善医疗保健服务时。方法。我们的人工智能系统的核心是 PGM [ 3 ],旨在为用户提供分诊建议并提出可能的病症。图形模型的结构由医学专家定义,并通过流行病学数据和专家引出的组合进行参数化。给定一组用户输入的当前症状和风险因素,该模型推断出最可能的情况并生成后续问题 [ 4 , 5 , 6 , 7 ]。该系统的决策功能是通过使用效用模型扩展底层生成模型来提供的,该效用模型作为疾病后验的函数,旨在提供分类建议,以最大限度地减少对患者的预期伤害,同时也惩罚过度分类。

面部表情线索整合过程中错误监测的神经元 θ 波特征
错误监控是一种元认知过程,通过这一过程,我们能够在做出反应后检测并发出错误信号。监控我们的行为结果何时偏离预期目标对于行为、学习和高阶社交技能的发展至关重要。在这里,我们使用脑电图 (EEG) 探索了面部表情线索整合过程中错误监控的神经基础。我们的目标是研究依赖于面部线索整合的响应执行之前和之后错误监控的特征。我们遵循中额叶 theta 的假设,认为它是错误监控的强大神经元标记,因为它一直被描述为一种发出认知控制需求的信号机制。此外,我们假设 EEG 频域分量可能有利于研究复杂场景中的错误监控,因为它携带来自锁定和非锁相信号的信息。应用了一个具有挑战性的 go/no-go 扫视范式来引出错误:需要整合面部情绪信号和凝视方向来解决这个问题。我们从 20 名健康参与者处获取了脑电图数据,并在反应准备和执行期间以 θ 波段活动水平进行分析。尽管 θ 调制在错误监控过程中一直得到证实,但它开始发生的时间尚不清楚。我们发现正确和错误试验之间中额通道的 θ 功率存在差异。错误反应后 θ 波段立即升高。此外,在反应开始之前,我们观察到了相反的情况:错误之前的 θ 波段较低。这些结果表明 θ 波段活动不仅是错误监控的指标(这是增强认知控制所必需的),也是成功的必要条件。这项研究通过在复杂任务中甚至在执行反应之前就揭示与错误相关的模式并使用需要整合面部表情线索的范例,为 θ 波段在错误监控过程中的作用增加了先前的证据。

DF-SSmVEP:采用双倍典型相关分析的双频聚合稳态运动视觉诱发电位设计
摘要:脑电图 (EEG) 传感器技术和信号处理算法的最新进展为脑机接口 (BCI) 在从康复系统到智能消费技术等多种实际应用中的进一步发展铺平了道路。当谈到 BCI 的信号处理 (SP) 时,人们对稳态运动视觉诱发电位 (SSmVEP) 的兴趣激增,其中运动刺激用于解决与传统光闪烁/闪烁相关的关键问题。然而,这些好处是以准确性较低和信息传输速率 (ITR) 较低的代价为代价的。在这方面,本文重点介绍一种新型 SSmVEP 范式的设计,而不使用试验时间、阶段和/或目标数量等资源来增强 ITR。所提出的设计基于直观的想法,即同时在单个 SSmVEP 目标刺激中集成多个运动。为了引出 SSmVEP,我们设计了一种新颖的双频聚合调制范式,称为双频聚合稳态运动视觉诱发电位 (DF-SSmVEP),通过在单个目标中同时整合“径向缩放”和“旋转”运动而不增加试验长度。与传统的 SSmVEP 相比,所提出的 DF-SSmVEP 框架由两种运动模式组成,这两种运动模式同时集成并显示,每种模式都由特定的目标频率调制。本文还开发了一种特定的无监督分类模型,称为双折典型相关分析 (BCCA),该模型基于每个目标的两个运动频率。相应的协方差系数被用作额外特征来提高分类准确性。基于真实 EEG 数据集对所提出的 DF-SSmVEP 进行了评估,结果证实了其优越性。所提出的 DF-SSmVEP 表现优于其他同类方法,平均 ITR 为 30.7 ± 1.97,平均准确度为 92.5 ± 2.04,而径向缩放和旋转的平均 ITR 分别为 18.35 ± 1 和 20.52 ± 2.5,平均准确度分别为 68.12 ± 3.5 和 77.5 ± 3.5。

通过从人类反馈中进行强化学习来学习飞机操纵行为的可解释模型
高速喷气式飞机的飞行员需要经过多年的高级训练才能获得出色的操控能力。如果能够将飞行员和其他领域专家的技能、知识和偏好提炼成一个能够捕捉真实操控行为的软件模型,那么这种方法将具有重大的实用价值。这种模型的可扩展性将使其可用于战略规划演习、培训以及其他软件系统的开发和测试。这将使人类驾驶专业知识这一稀缺资源获得更大的回报。这一愿景面临着实际挑战,即准确地获取所需知识以将其编入自动化系统。在许多需要直觉决策和快速运动控制的情况下,专家们一看到良好的操控性就知道,但并不总是能用形式或语言术语表达原因 [1]。∗ 显性知识获取策略也可能非常耗时,任何依赖专家演示的方法也是如此。这促使人们采用一种使用稀疏数据源的基于学习的方法。鉴于透明度对于安全至关重要的航空应用的重要性 [2、3],任何此类方法都必须学习一个可解释(即人类可读和可理解)的专家知识模型,以促进信任和验证。本文提出了一种可能的解决方案。我们使用人工智能强化学习 (RL) 代理来生成模拟飞行轨迹数据集,然后咨询专家以获得对这些轨迹的成对偏好,表明哪一个是针对给定感兴趣任务的首选解决方案。众所周知,成对偏好引出具有稳健性和时效性,并为组合来自多个专家的数据提供了基础,而无需就共同的评分系统达成一致。然后,我们使用统计学习算法以基于规则的树结构形式构建收集到的偏好的可解释解释模型。反过来,该树被用作奖励函数来训练代理生成更高质量的轨迹,并迭代该过程直至收敛。最终结果是两个不同的输出,它们可以形成未来规划、培训和开发软件的宝贵组成部分:

一种基于计算机的测量立体潜伏期的方法......
介绍 视觉深度感知(立体视觉)传统上是通过评估受试者可检测到的最小双眼视差来测试的。然而,事实表明,在日常生活中无法区分单眼和双眼视觉的受试者在视差测试中可能会得分较高(“立体视觉障碍”)。研究发现,产生视觉感知(立体延迟)所需的双眼测试刺激的最短持续时间与日常立体视觉障碍的相关性更高。我们描述了一种评估立体延迟的新方法,该方法不需要除个人计算机(PC)和一副 3D 眼镜(带绿色和红色镜片)以外的特殊仪器。材料和方法受试者舒适地坐在 IBM 兼容 PC 的屏幕前,戴着一副带绿色和红色滤光片(镜片)的 3c0 眼镜。计算机屏幕上以以下方式生成随机点立体图:最初只显示绿点,然后突然添加红点。并在屏幕上持续一段随机设定的可变时间(25-500 毫秒)。时间步长通常为 25 毫秒。每次三次持续 4 秒,双眼刺激总是在这个时间结束时出现。受试者在三次之后按下两个键之一以表示深度知觉的缺失或存在。能够引出 70% 或更多正确答案的最小呈现时间(每个时间步长重复 10 次)被记录为立体延迟。结果到目前为止,已有 7 名 24-45 岁的正常受试者接受了测试。一名受试者未通过测试,无法在任何时间步长上表现得比偶然情况更好。对于其余受试者,平均立体延迟为 250 毫秒(SD=25 毫秒)。结论这似乎是一种有效的、易于实施的协议,用于确定随机点立体图的立体延迟。目前正在改进该程序,以便更精确地测定最小立体潜伏期值,并使正常人和患有神经眼科疾病的患者的值标准化。
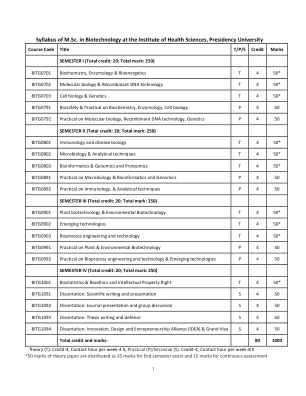
总统大学健康科学研究所生物技术硕士课程大纲
目的和目标:本课程旨在建立本科生对生物化学和生物过程、生物分子功能以及从病毒和细菌到植物和哺乳动物细胞的各种生物的基本知识。将重点介绍正常和患病条件下这些过程的分子细节。本课程将更好地了解各种生物的发病途径、研究这些过程的最新技术进步,并了解如何利用所获得的知识促进生物技术进步,并为各种疾病和病症的生物医学干预制定新策略。课程成果 (PO): PO1:基础知识和批判性思维 - 学生应深入了解生物学和生物技术的各个方面,以及各种生物体中众多生理过程的分子基础。PO2:批判性思维和研究能力——学生应该能够识别科学问题,并能够应用不同的生物技术策略和技术来研究问题并解释结果。PO3:有效沟通——学生应该能够分析和撰写科学文献,能够用英语在现场和通过电子媒体清晰地交流,并能够与人联系以分享他们的想法和技术。如果需要,学生应该能够使用他/她觉得舒适的任何其他语言与他人交流。PO4:道德——学生能够识别与生物技术过程和产品相关的不同知识产权 (IPR) 和道德问题。PO5:社会互动——在小组环境中引出他人的观点、调解分歧并帮助得出结论。PO6:环境与可持续性——学生能够理解与生物安全、环境生物技术和可持续发展相关的问题。项目具体成果 (PSO):PSO-1:了解生物化学、分子和细胞生物学、微生物学、免疫学、生物物理学、生物统计学和生物信息学不同方面的基本概念,以了解各种生命形式的不同生理过程。PSO-2:在理论和实践层面学习与不同生物技术领域相关的不同技术和策略,例如重组 DNA 技术、植物生物技术、环境生物技术、酶技术、纳米技术、发酵、组织工程、基因组学和蛋白质组学以及合成化学。PSO-3:获得了解和执行相关领域短期研究项目的经验。PSO-4:学习各种生物安全和其他安全措施,以便在实验室或现场进行实验。PSO-5:学习学术和生物技术研究中的道德行为,包括学术和行业设置、知识产权和其他与生物技术相关的礼仪,以便全面了解

国家法律的隐私影响评估...
以非技术术语提供信息技术(例如应用程序、工具、自动化流程)的高级概述,描述信息技术、其目的、信息技术如何运作以实现该目的、所涉及的一般信息类型、如何使用和共享信息,以及为什么要进行隐私影响评估。(注意:本节是概述;以下问题将引出更多细节。)2022 年 5 月 25 日,总统发布了第 14074 号行政命令,推进有效、负责任的警务和刑事司法实践,以增强公众信任和公共安全(“行政命令”)。行政命令第 5 节指示司法部长建立国家执法问责数据库(“NLEAD”),用于记录执法人员(“LEO”)不当行为、表彰和奖励的官方记录。行政命令致力于通过改进执法行动官员的招聘和背景调查来进一步提高问责制和透明度。根据行政命令,司法部建立了 NLEAD 系统,以促进加强招聘实践和背景调查的过程,同时保护 NLEAD 中确定的执法行动官员的安全、隐私和正当程序权利。NLEAD 将使用指针系统进行操作,这是一种数据库管理模型,它利用“指针”来指示被搜索个人存在特定类型的记录,并将请求者指向记录的位置(即源机构)。根据行政命令的规定,NLEAD 将包括表明存在与官员不当行为相关的以下类别的记录的数据:刑事定罪;执法行动官员的执法权被暂停,例如取消认证;解雇;民事判决,包括与公务有关的金额(如果公开可用);因严重不当行为接受调查期间辞职或退休;以及持续投诉或根据严重不当行为的调查结果受到纪律处分的记录。仅当 NLEAD 中确定了这些其他类别的信息之一时,才会包括官员表彰和奖励。NLEAD 将根据适用法律,在联邦执法人员的招聘、工作分配和晋升方面使用,方法是将查询 NLEAD 的用户与保存详细说明不当行为、表彰和奖励的基础记录的联邦执法机构联系起来。本 PIA 仅涵盖 NLEAD 系统,而不涵盖源机构持有的基础记录。基础记录由源机构自己的隐私文件(例如,记录系统通知和 PIA)适当地涵盖。第 2 节:信息技术的目的和用途

我摔倒时受伤了:
致谢/谢意 首先,我要向我的论文导师表示最诚挚的谢意:在本项目中发挥了基础作用的 Martin Maiden 教授和 John Charles Smith 先生,以及 2017 年退休后接替 JC 的 Ros Temple 博士,感谢他们过去六年来的重要指导、急需的耐心和不懈的善意。 我要感谢牛津大学克拉伦登基金会、加拿大社会科学和人文研究委员会、玛格丽特夫人霍尔学院、加拿大-英国基金会以及牛津大学语言学、语言文学和语音学学院慷慨的经济支持,使我能够完成博士学业。 我还要感谢我的 DPhil 确认考官 Deborah Cameron 教授对该项目早期版本的反馈;Sam Wolfe 博士对第 2 章发布版本的评论;Wolfgang De Melo 教授的精神和行政支持;中央大学研究伦理委员会团队协助我完成实地考察;以及玛格丽特夫人霍尔的优秀员工,他们在本研究项目的每个阶段以及我在牛津期间都给予了极大的支持。我还要感谢国际语言学家团体:Gillian Sankoff,她代表我使用她的蒙特利尔法语语料库进行统计分析,并友好地与我分享她的研究结果以供本项目使用;Mathieu Avanzi 和 André Thibault,他们慷慨地与我分享了他们的 Français d'ici 辅助数据;Anne-José Villeneuve,她在本研究的初始阶段给予了指导;Raymond Mougeon,她为我提供了如何按主题组织访谈的各种建议,以便最好地引出辅助替换数据;最后,渥太华大学社会语言学实验室的 Shana Poplack、Nathalie Dion 和 Basile Roussel,感谢他们欢迎我并分享他们对辅助替换的真知灼见。在技术方面,我还要感谢约翰·科尔曼 (John Coleman) 和牛津大学语音实验室为我在蒙特利尔的实地考察提供录音设备;感谢我亲爱的朋友泽维尔·巴赫博士 (Dr. Xavier Bach) 向我展示如何使用转录软件 ELAN;感谢丹尼尔·埃兹拉·约翰逊 (Daniel Ezra Johnson) 在该项目的统计分析阶段不断为我提供 (Shiny) Rbrul 的实际帮助。

ACM 参考格式:Yoonjoo Lee、John Joon Young Chung、Tae Soo Kim、Jean Y. Song 和 Juho Kim。2022 年。Promptiverse:通过可扩展的方式生成脚手架提示
虽然在线视频学习已成为各种学习者广泛采用的方法,但大多数在线视频学习环境为所有学习者提供的都是相同的讲座视频。在千篇一律的设计中,由于学习者先前的知识不同,他们可能会对讲座内容的不同部分感到困难。找到另一个能更好地解释学习者困难点的视频可能是一个解决方案,但这需要学习者搜索这样的视频,从而产生额外的努力。此外,由于学习者是新手,他们可能没有足够的知识来辨别哪个视频可以帮助他们克服困难。缓解学习者因千篇一律的视频设计而产生的各种痛点的一种方法是利用不同的支架提示,这些提示提供提示并向学习者询问学习内容。例如,如果视频对某个概念的解释对学习者来说不够详细,那么学习者就会很难理解内容。有了多样化的提示,如果学习者向在线学习系统寻求有关概念的帮助,那么系统可以提供合适的支架提示,让学习者有机会促进他们对该概念的理解。提示可以让学习者检查他们的理解,保持他们的参与度,并让他们将该概念与他们已经知道的其他概念联系起来[11,12]。最终,对概念的理解将拓宽学习者组织和感知新信息的方案,让学习者全面理解讲座。为了成功提供这种支持,必须准备各种各样的支架提示来应对学习者的各种痛点。然而,由于创作成本高昂,手动创建多样化的支架提示可能是不切实际的,如果没有这种多样性,提示往往无法全面解决讲座中涉及的各种概念。在这项工作中,我们介绍了 Promptiverse,这是一种支架提示生成方法,它使用知识图谱以较低的创作成本大规模创建多样化的提示。 Promptiverse 借助讲座内容的知识图谱,遍历知识实体和关系,同时考虑 Ausubel 理论 [ 4, 6 ] 中有意义的学习模式,这为设计有效的教学提示提供了深刻见解。Promptiverse 不仅从遍历的路径中生成大量提示,而且还通过改变哪些知识元素作为提示提供以及哪些知识元素从学习者那里引出,使提示的内容多样化。例如,在图 1 中,Promptiverse 通过改变遍历的路径生成了两个不同的支架提示(绿色框)。这些不同内容的提示可以为那些可能无法理解视频解释的学习者提供不同的解释。尽管 Promptiverse 有望实现提示的可扩展创建,但构建底层知识图谱需要课程设计人员的手动操作。因此,我们设计了 Grannotate,一款人机混合系统,用于协助课程设计人员