XiaoMi-AI文件搜索系统
World File Search System归一化

频谱归一化对比对比的 -
现有的图像到图像(I2i)翻译方法通过将斑块的对比度学习置于生成性对抗网络中,从而实现最先进的性能。然而,斑块的对比度学习仅关注局部内容的相似性,但忽略了全球结构的结合,这会影响生成的图像的质量。在本文中,我们提出了一个基于双重对比的正则化和光谱归一化的新的未配对I2I翻译框架,即SN-DCR。为了维持全局结构和纹理的一致性,我们分别使用不同的深度特征空间设计了双重对比正则化。为了改善生成图像的全局结构信息,我们制定了语义上对比的损失,以使生成的图像的全局语义结构类似于语义特征空间中目标域中的真实图像。我们使用革兰氏矩阵从图像中提取纹理样式。同样,我们设计样式的对比损失,以改善生成图像的全局纹理信息。此外,为了增强模型的稳定性,我们在发电机的设计中采用了光谱归一化卷积网络。我们进行了全面的实验来评估SN-DCR的有效性,结果证明了我们的方法在多个任务中实现了SOTA。

非归一化谐波的物理解释......
不可归一化状态很难用正统的量子形式来解释,但通常作为量子引力中物理约束的解出现。我们认为,导航波理论对不可归一化量子态给出了直接的物理解释,因为该理论只需要配置的归一化密度即可生成统计预测。为了更好地理解这种状态,我们从导航波的角度对谐振子的不可归一化解进行了首次研究。我们表明,与正统量子力学的直觉相反,不可归一化本征态及其叠加态是束缚态,因为速度场 v y → 0 大于 ± y 。我们认为,为这种状态定义一个物理上有意义的平衡密度需要一个新的平衡概念,称为导航波平衡,它是量子平衡概念的概括。我们定义了一个新的 H 函数 H pw ,并证明导航波平衡中的密度使 H pw 最小化,是等变的,并且随时间保持平衡。在与放松到量子平衡的假设类似的假设下,我们证明了粗粒度 H pw 的 H 定理。我们从由于扰动和环境相互作用导致的不可归一化状态的不稳定性的角度解释了导航波理论中量化的出现。最后,我们讨论了在量子场论和量子引力中的应用,以及对导航波理论和量子基础的一般影响。


关于相变和重新归一化组的讲座
多体问题:1961年的讲座注释和重印卷,《摩斯鲍尔效应:综述》,带有重印集合,1962年,量子统计力学:格林在平衡和非平衡问题中的函数方法,1962年的磁性复位:入门图:1962年的入门图书,1962年[CR。(42)-2nd Edition] g。 E. Pake Concepts in Solids: Lectures on the Theory of Solids, 1963 Regge Poles and S-Matrix Theory, 1963 Electron Scattering and Nuclear and Nucleon Structure: A Collection of Reprints with an Introduction, 1963 Nuclear Theory: Pairing Force Correlations to Collective Motion, 1964 Mandelstam Theory and Regge Poles: An Introduction M. Froissart for Experimentalists, 1963 Complex Angular Momenta and Particle Physics: A Lecture Note and Reprint卷,1963年,经典流体的均衡理论:讲座注释和重印卷,1964年,《八倍的方式》(评论 - 带有转载的集合),1964年,强度相互作用物理学:讲座音符卷,1964年,

归一化的关联,非差异表达
交叉数据测试对于检查机器学习(ML)模型的性能至关重要。但是,大多数关于转录组和临床数据建模的研究仅进行了数据内测试。还不清楚归一化和非差异表达基因(NDEG)是否可以改善ML的跨数据库建模性能。因此,我们旨在了解归一化,NDEG和数据源是否与ML在跨数据库测试中的性能有关。使用了TCGA和ONCOSG中肺腺癌病例共享的转录组和临床数据。仅使用转录组数据就达到了最佳的跨数据库ML性能,并且在统计学上比使用转录组和临床数据更好。最佳平衡精度(BA),曲线下的面积(AUC)和在TCGA上的ML算法培训中的精度明显高于ONCOSG的测试,而在ONCOSG上进行了测试并在TCGA上进行了测试(所有人的P <0.05)。归一化和NDEG在两个数据集中大大改善了数据集中的ML性能,但在跨数据库测试中却没有。引人注目的是,单独对ONCOSG的转录组数据进行建模优于建模转录组和临床数据,而TCGA中包括临床数据的转录组和临床数据并没有显着影响ML性能,这表明TCGA中转录量数据的临床数据值有限或转录量的倒数影响。在数据内测试中的性能提高更为明显。在比较的六个ML模型中,支持矢量机是在数据集和跨数据库测试中最常见的表现最常见的。因此,我们的数据显示了数据源,归一化和NDEG在建模转录组和临床数据中与数据集和跨数据库ML性能相关。

自动归一化法语及其对生产力的影响
摘要本文介绍了一项关于以中间法语编写的16世纪文档自动归一化的研究。这些文档提出了各种各样的单词形式,这些单词形式需要拼写归一化以促进下游语言和历史研究。我们将归一化过程作为机器翻译任务开始,从强大的基线开始利用预训练的编码器– DECODER模型。我们建议通过结合合成数据生成方法和生成人工培训数据来改善这一基线,从而解决与我们任务相关的平行语料库。对我们的方法的评估是双重的,除了依靠黄金参考的自动指标外,我们还通过其产出后评估我们的模型。这种评估方法直接测量了我们的模型给手动进行标准化任务的专家带来的生产力增长。结果表明,与从头开始使用自动归一化相比,使用自动归一化时,生产率每分钟增加了20多个令牌。由我们的研究产生的手动编辑的数据集是将公开发布的第一个正常化的16世纪中部法国人的平行语料库,以及合成数据以及在介绍的工作中使用和培训的自动归一化模型。

归一化能源使用强度(NEUI)方法
Realpac,其董事,高级职员,员工或任何其他负责人负责的人都不对本出版物中包含的语言,措辞或标准的使用,效果或适当性承担责任,或任何印刷或印刷错误或印刷错误或遗漏。REALPAC不保证使用本出版物中包含的信息的数据,公式,模板,方法,标准和过程的准确性。REALPAC及其董事,高级管理人员,员工或任何其他负责人负责的其他人对使用此处包含的信息造成的损害或损失概不负责。REALPAC不提供投资,环境,法律或税收建议。读者会自担风险,并敦促咨询自己的专业顾问以进行进一步确认和更多信息。

差异实现了各种精确的重新归一化组示例
在范德华(Van der Waals)中观察到的非常规的平坦带(FB)超导性,可以为高-T C材料打开有希望的途径。在FBS,配对和超级流体重量量表与交互参数线性线性线性,这种不寻常的理由证明并鼓励促进FB工程的策略。二分晶格(BLS)自然托管FBS可能是特别有趣的候选者。在Bogoliubov de Gennes理论和BLS中有吸引力的哈伯德模型的框架内,揭示了准粒子本征的隐藏对称性。因此,我们展示了与跳跃术语的特征无关的配对和超流量的普遍关系。值得注意的是,只要受到两部分特征的保护,这些一般特性对疾病不敏感。

反射率校准,具有高光谱成像的归一化校正
摘要 - 末期,高光谱(HS)成像已成为通过联合获取空间和光谱信息来远程识别兴趣区域的强大工具。但是,就像在大多数成像技术中一样,数据采集期间可能会发生不良影响,例如噪声,光强度的变化,温度差异或光学变化。在HS成像中,可以使用反射校准阶段和光学过滤来减弱这些问题。然而,光学填充可能会引起某种失真,这可能会使后图像处理阶段复杂化。在这项工作中,我们提出了一项重新反映校准的新建议,该建议可以补偿在获得HS图像期间的光学变化。对具有特定光谱响应的各种材料的合成正方形的HS图像进行了评估。我们的提案结果使用K-均值算法的两次分类测试显示出高性能,其精度为97%和88%;与获得77%和64%精度的文献相比,与标准反射校准相比。这些结果说明了所提出的配方的性能增益,除了维持HS图像中的特征性特征外,还可以使结果反射到固定的下层和上限,从而避免了后校准后的归一步步骤。索引术语 - 光谱成像,光学滤波器,反射校准
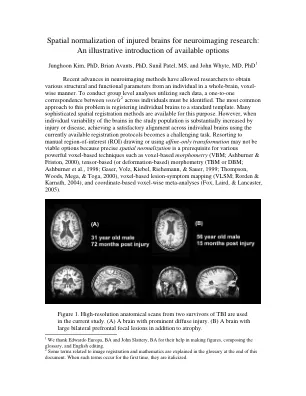
神经影像学研究受伤大脑的空间归一化:
神经影像学方法的最新进展使研究人员能够以整个脑,体素的方式从个体那里获得各种结构和功能参数。要通过使用此类数据进行小组级别分析,必须确定个人之间体素2之间的一对一对应关系。解决此问题的最常见方法是将单个大脑注册为标准模板。许多复杂的空间注册方法可用于此目的。但是,当研究人群中大脑的个体变异性通过伤害或疾病大大增加时,使用当前可用的注册方案实现了各个大脑的令人满意的一致性,就成为一项艰巨的任务。诉诸于手动区域(ROI)绘图或使用仅兴趣的转换可能不是可行的选择,因为精确的空间归一化是基于体素基于体素的多种技术(例如基于Voxel的形态计数器)的先决条件(VBM; Ashburner&Friston,2000),基于Tensor的基于基于tensor的基于基于voxer的技术。 1998; GASER,VOLZ,Kiebel,Riehemann和Sauer,1999年;汤普森,伍兹,巨型和托加,2000年),基于体素的病变 - 症状映射(VLSM; Rorden&Karnath,2004),以及基于辅助的Voxel-Wise Meta-analys(Fox&Fox,Fox,Fox&liaird&fox&liaird&fox&liaird,