XiaoMi-AI文件搜索系统
World File Search System按类型

场地规划 – 类型 1
1) 目的说明 2) 分区条例 1-19-5.300 中定义的现有和拟议用途 3) 物业地址、地籍图册和页码、地契、分区、综合规划土地用途指定、规划区域 4) 现有和拟议建筑面积的总平方英尺数以及每个现有和拟议土地用途的建筑占地面积 5) 总面积和地块尺寸、建筑限制线 - 必需和拟议 6) 高度和层数 - 必需和拟议 7) 所有装卸、停车和自行车停车位的尺寸和计算 - 现有、必需和拟议 8) FRO 地役权和说明 - 拟议和现有 9) 农业保护地役权和说明 - 拟议和现有 10) 历史资源 11) APFO 说明、出行生成表和交通影响研究计数(如适用) 12) 生命安全办公室说明、ADA 说明(如适用) 13) DUSWM 说明 - 下水道和水分类、公用设施需求 14) 卫生部门备注(如适用)

类型的临床结果-1 and-type-2-Dabicet-Patients- ...
1。爱尔兰戈尔韦Ballinasloe的Portiuncula大学医院内科。 2。 医学院,纽卡斯尔路大学,爱尔兰戈尔韦公司。 抽象的糖尿病性酮症酸中毒(DKA)是糖尿病生命的并发症之一。 通常与1型糖尿病有关;但是,在2型糖尿病中越来越多地认识到它。 旨在分析DKA在1型和2型糖尿病患者中的临床结果的差异。 方法在2017年至2022年之间进行了一项回顾性研究,审查了Portiuncula大学医院(PUH)诊断为DKA的患者图表。 分析了患者人口统计学,入院和临床结果的生化预科。 结果总共有118名糖尿病患者发展为DKA,89例(75.4%)是1型糖尿病患者。 2型DKA患者比1型糖尿病患者大(62.3±15.9 vs 39.1±15.9岁,P值<0.030),糖尿病持续时间更长(15.4±4.9 vs 11.3±3.3,p值<0.031)。 在1型与2型糖尿病的患者之间的生化蛋白质中没有显着差异,但是,患有2型糖尿病的患者的乳酸水平明显更高(2.98±1.4 vs 2.43±1.43±1.1 mmol/l,p值<0.026)。 总体而言,与1型糖尿病患者相比,DKA的临床结果在2型中更为严重。 讨论大多数DKA病例是在1型糖尿病患者中观察到的,但是在2型糖尿病患者的DKA患者中,主要结果较差。 简介爱尔兰戈尔韦Ballinasloe的Portiuncula大学医院内科。2。医学院,纽卡斯尔路大学,爱尔兰戈尔韦公司。 抽象的糖尿病性酮症酸中毒(DKA)是糖尿病生命的并发症之一。 通常与1型糖尿病有关;但是,在2型糖尿病中越来越多地认识到它。 旨在分析DKA在1型和2型糖尿病患者中的临床结果的差异。 方法在2017年至2022年之间进行了一项回顾性研究,审查了Portiuncula大学医院(PUH)诊断为DKA的患者图表。 分析了患者人口统计学,入院和临床结果的生化预科。 结果总共有118名糖尿病患者发展为DKA,89例(75.4%)是1型糖尿病患者。 2型DKA患者比1型糖尿病患者大(62.3±15.9 vs 39.1±15.9岁,P值<0.030),糖尿病持续时间更长(15.4±4.9 vs 11.3±3.3,p值<0.031)。 在1型与2型糖尿病的患者之间的生化蛋白质中没有显着差异,但是,患有2型糖尿病的患者的乳酸水平明显更高(2.98±1.4 vs 2.43±1.43±1.1 mmol/l,p值<0.026)。 总体而言,与1型糖尿病患者相比,DKA的临床结果在2型中更为严重。 讨论大多数DKA病例是在1型糖尿病患者中观察到的,但是在2型糖尿病患者的DKA患者中,主要结果较差。 简介医学院,纽卡斯尔路大学,爱尔兰戈尔韦公司。抽象的糖尿病性酮症酸中毒(DKA)是糖尿病生命的并发症之一。通常与1型糖尿病有关;但是,在2型糖尿病中越来越多地认识到它。旨在分析DKA在1型和2型糖尿病患者中的临床结果的差异。方法在2017年至2022年之间进行了一项回顾性研究,审查了Portiuncula大学医院(PUH)诊断为DKA的患者图表。患者人口统计学,入院和临床结果的生化预科。结果总共有118名糖尿病患者发展为DKA,89例(75.4%)是1型糖尿病患者。2型DKA患者比1型糖尿病患者大(62.3±15.9 vs 39.1±15.9岁,P值<0.030),糖尿病持续时间更长(15.4±4.9 vs 11.3±3.3,p值<0.031)。在1型与2型糖尿病的患者之间的生化蛋白质中没有显着差异,但是,患有2型糖尿病的患者的乳酸水平明显更高(2.98±1.4 vs 2.43±1.43±1.1 mmol/l,p值<0.026)。总体而言,与1型糖尿病患者相比,DKA的临床结果在2型中更为严重。讨论大多数DKA病例是在1型糖尿病患者中观察到的,但是在2型糖尿病患者的DKA患者中,主要结果较差。简介应强调治疗这组患者的创新方法。

机器学习模型的类型
机器学习模型是自动化任务的强大工具,使其更加准确和高效。这些模型可以按需求处理新的数据并扩展新的数据,从而提供有价值的见解,以提高随着时间的推移绩效。该技术具有许多好处,包括更快的处理,增强的决策和专业服务。机器学习模型是在看不见的数据集中识别模式以做出决定的软件程序。自然语言处理(NLP)使用机器学习模型来分析非结构化文本并提取可用的数据和见解。图像识别是机器学习的另一种应用,它可以识别人,动物或车辆等物体。机器学习模型需要一个数据集来培训和在优化过程中使用算法,以查找数据的模式或输出。基于数据和学习目标有四种主要类型的机器学习模型:1。**监督模型**:这些模型使用标记的数据来发现输入特征和目标结果之间的关系。2。**分类**:这种类型的模型将类标签分配给看不见的数据点,例如对电子邮件进行分类或预测贷款申请人的信誉。常见分类算法包括: *逻辑回归 *支持向量机(SVM) *决策树 *随机森林 * K-Nearest邻居(KNN)预测使用输入功能作为基础的连续输出变量预测连续输出变量在现实世界中至关重要,例如预测房地产价格,股票市场趋势,股票市场趋势,客户销售速率,销售速度和销售费用和销售。常见回归算法包括:1。回归模型利用这些功能来了解连续变量和输出值之间的关系。他们应用了学习的模式来预测新的数据点。**线性回归**:使用直线建模关系。2。**多项式回归**:使用更复杂的函数(例如二次或立方)用于非线性数据。3。**决策树回归**:一种基于决策树的算法,可预测分支决策的连续输出。4。**随机森林回归**:结合了多个决策树,以确保准确稳健的回归预测。5。**支持向量回归(SVR)**:调整支持向量机概念的回归任务,找到一个密切反映连续输出数据的单个超平面。无标记数据的无监督学习交易。它涉及使用聚类算法进行分组类似的数据点,例如:1。** K-均值聚类**:基于相似性将数据分组为预定群体。2。**分层聚类**:构建群集的层次结构,以轻松研究组系统。3。** DBSCAN(基于密度的空间群集使用噪声)**:即使在缺少数据或异常值的区域,也可以检测高密度数据点。降低维度在处理大型数据集时也至关重要。它降低了维度以维护关键功能,从而更容易可视化和分析数据。技术包括:1。2。** PCA(主要组件分析)**:通过将数据集中在更少的维度中来识别最重要的维度。** LDA(线性判别分析)**:类似于PCA,但专为分类任务而设计。最后,也可以应用无监督的学习来检测异常 - 数据与大多数的点大不相同。在数据分析中对异常值,半监督学习和强化学习的建模得到了奖励,并受到所需的行动的奖励,并对不希望的行为进行惩罚有助于玩家获得最高的回报。这种方法还涉及基于价值的学习,其中像机器人一样的代理商学会了通过获得达到末端并在撞墙时损失时间来浏览迷宫的过程。算法Q学习可以预测每个州行动组合的未来奖励,从而通过重复评估和奖励更新其知识。基于策略的学习采用了不同的途径,重点是直接学习映射到行动的政策。Actor-Critic将策略更新与价值功能再培训结合在一起,而近端策略优化解决了早期基于政策的方法中的高变化问题。深度学习利用人工神经网络识别复杂的模式。诸如人工神经网络(ANN),卷积神经网络(CNN)和经常性神经网络(RNN)之类的模型用于图像识别,自然语言处理和顺序数据分析等任务。机器学习模型利用各种功能来输入数据并产生预测,包括线性方程,决策树或复杂的神经网络。学习算法是负责在训练过程中适应模型参数以最小化预测错误的核心部分。培训数据包括输入功能和相应的输出标签(监督学习)或无标记的数据(无监督学习)。目标函数衡量预测和实际结果之间的差异,目的是最大程度地减少此功能。优化过程,例如梯度下降,迭代调整参数以减少错误。一旦受过培训,就会在单独的验证集上评估模型,以评估概括性能。最终输出涉及将训练有素的模型应用于新的输入数据以进行预测或决策。高级机器学习模型包括神经网络,这些神经网络成功地解决了复杂问题,例如图像识别和自然语言处理。卷积神经网络(CNNS)处理符号数据,例如图像,而复发性神经网络(RNN)处理顺序数据(如文本)。长期短期内存网络(LSTMS)识别长期相关性,而生成对抗网络(GAN)通过从现有数据集中学习模式生成新数据。机器学习模型随着时间的流逝而发展,产生了两个网络:一个产生网络数据,另一个区分真实样本和假样品。变压器模型通过随着时间的推移处理输入数据并捕获长期依赖性,从而在自然语言处理中获得了知名度。*医疗保健:机器学习预测疾病,建议治疗并提供预后。机器学习的现实应用程序包括: *金融服务:银行使用智能算法来了解客户的投资偏好,加快贷款批准并检测异常交易。例如,医生可以为患者预测正确的冷药。*制造业:机器学习通过提高效率和确保质量来优化生产过程。*商业领域:ML模型分析大型数据集,以预测趋势,了解营销系统并为目标客户定制产品。机器学习中的挑战包括: *有限的资源和工具,用于上下文化大数据集 *需要更新和重新启动模型以了解新的数据模式 *收集和汇总不同技术版本之间的数据以应对这些挑战,战略规划,适当的资源分配以及技术进步至关重要。

机器学习方法的类型
机器学习在研究和行业中正在迅速发展,新方法不断出现。这种速度甚至使专家要对新移民保持艰巨和艰巨。为了使机器学习神秘,本文将探讨十种关键方法,包括解释,可视化和示例,以提供对核心概念的基本理解。我曾经依靠多变量的线性回归来预测特定建筑物中的能源使用(以kWh),通过结合建筑年龄,故事数量,平方英尺和插入电器等因素。由于我有多个输入,因此我采用了多变量方法,而不是简单的一对一线性回归。该概念保持不变,但根据变量数量将其应用于多维空间。下图说明了该模型与建筑物中实际能耗匹配的程度。想象一下可以访问建筑物的特征(年龄,平方英尺等),但缺乏有关其能源使用的信息。在这种情况下,我可以利用拟合线来估计该特定建筑物的能源消耗。另外,线性回归使您能够衡量每个促成最终能量预测因素的重要性。例如,一旦建立了一个公式,就可以确定哪些因素(年龄,大小或身高)对能耗的影响最大。分类是一个基本的概念,然后再继续采用更复杂的技术,例如决策树,随机森林,支持向量机和神经网。1。2。随着机器学习的进展(ML),您将遇到非线性分类器,从而实现更复杂的模式识别。聚类方法属于无监督的ML类别,重点是将具有相似特征的观测值分组而无需使用输出信息进行培训。而不是预定义的输出,聚集算法根据数据相似性定义了自己的输出。一种流行的聚类方法是K-均值,其中“ K”代表用户为群集创建的数字。该过程工作如下:数据中的随机选择“ K”中心;将每个点分配到其最接近的中心;重新计算新的集群中心;并迭代直至达到收敛或最大迭代限制。例如,在建筑物的数据集中,应用K = 2的K均值,可以根据空调效率等因素将建筑物分为高效(绿色)和低效率(红色)组。聚类具有自己的一系列有用算法,例如DBSCAN和平均移位群集。降低性降低是另一种基本技术,用于管理具有许多与分析不相关的列或功能的数据集。主组件分析(PCA)是一种广泛使用的维度缩减方法,它通过找到最大化数据线性变化的新向量来降低特征空间,从而使其成为将大型数据集减少到可管理大小的有效工具。在具有较强线性相关性的数据集上应用维度降低技术时,可以通过选择适当的方法来最大程度地减少信息丢失。例如,T-Stochastic邻居嵌入(T-SNE)是一种流行的非线性方法,可用于数据可视化以及在机器学习任务中的特征空间降低和聚类。手写数字的MNIST数据库是分析高维数据的主要示例。此数据集包含数千个图像,每个图像都标记为0到9。使用T-SNE将这些复杂数据点投影到两个维度上,研究人员可以在原始784维空间中可视化复杂的模式。类似于通过选择最佳组件并将它们组装在一起以获得最佳性能,类似于构建自定义自行车,Ensemble方法结合了多个预测模型,以实现比单个模型本身所能实现的更高质量预测。诸如随机森林算法之类的技术(汇总在不同数据子集训练的决策树上)就是组合模型如何平衡差异和偏见的示例。在Kaggle比赛中表现最好的人经常利用集合方法,其中包括随机森林,Xgboost和LightGBM在内的流行算法。与线性模型(例如回归和逻辑回归)相比,神经网络旨在通过添加参数层来捕获非线性模式。这种灵活性允许在更复杂的神经网络体系结构中构建更简单的模型,例如线性和逻辑回归。深度学习,其特征是具有多个隐藏层的神经网络,包括广泛的架构,使得与其连续演变保持同步是一项挑战。深度学习在研究和行业社区中变得越来越普遍,每天引起新的方法论。为了实现最佳性能,深度学习技术需要大量数据和计算能力,因为它们的自我调整性质和大型体系结构。使用GPU对于从业者来说是必不可少的,因为它使该方法的许多参数能够在巨大的体系结构中进行优化。深度学习已在视觉,文本,音频和视频等各个领域中取得了非凡的成功。TensorFlow和Pytorch是该领域最常见的软件包之一。考虑一位从事零售工作的数据科学家,其任务是将衣服的图像分类为牛仔裤,货物,休闲或衣服裤。可以使用转移学习对训练衬衫进行分类的初始模型。这涉及重复一部分预训练的神经网络,并为新任务进行微调。转移学习的主要好处是,训练神经网络所需的数据较少,鉴于所需的大量计算资源以及获取足够标记的数据的困难,这一点尤为重要。在行动中的强化学习:最大化奖励和推动AI边界RL可以在设定的环境中最大化累积奖励,从而使其非常适合具有有限数据的复杂问题。在我们的示例中,一只鼠标会导航迷宫,从反复试验中学习并获得奶酪奖励。rl在游戏中具有完美的信息,例如国际象棋和GO,反馈快速有效。但是,必须确认RL的局限性。像Dota 2这样的游戏对传统的机器学习方法具有挑战性,但RL表现出了成功。OpenAI五支球队在2019年击败了世界冠军E-Sport球队,同时还开发了可以重新定位的机器人手。世界上绝大多数数据都是人类语言,计算机很难完全理解。NLP技术通过过滤错误并创建数值表示来准备用于机器学习的文本。一种常用方法是术语频率矩阵(TFM),其中每个单词频率均可在文档中计算和比较。此方法已被广泛使用,NLTK是用于处理文本的流行软件包。尽管取得了这些进步,但在将RL与自然语言理解相结合,确保AI可以真正理解人类文本并解锁其巨大潜力时仍将取得重大进展。TF-IDF通常优于机器学习任务的其他技术。TFM和TFIDF是仅考虑单词频率和权重的数值文本文档表示。单词嵌入,通过捕获文档中的单词上下文,将此步骤进一步。这可以用单词进行算术操作,从而使我们可以表示单词相似性。Word2Vec是一种基于神经网络的方法,它将大型语料库中的单词映射到数值向量。这些向量可用于各种任务,例如查找同义词或表示文本文档。单词嵌入还通过计算其向量表示之间的余弦相似性来启用单词之间的相似性计算。例如,如果我们有“国王”的向量,我们可以通过使用其他单词向量进行算术操作来计算“女人”的向量:vector('queen'')= vector('king'') + vector('king') + vector('woman'') - vector('男人')。我们使用机器学习方法来计算这些嵌入,这些方法通常是应用更复杂的机器学习算法的预步骤。要预测Twitter用户是否会根据其推文和其他用户的购买历史来购买房屋,我们可以将Word2Vec与Logistic回归相结合。可以通过FastText获得157种语言的预训练词向量,使我们可以跳过自己的培训。本文涵盖了十种基本的机器学习方法,为进一步研究更高级算法提供了一个可靠的起点。但是,还有很多值得覆盖的地方,包括质量指标,交叉验证和避免模型过度拟合。此博客中的所有可视化均使用Watson Studio Desktop创建。机器学习是一个AI分支,算法在其中识别数据中的模式,在没有明确编程的情况下进行预测。这些算法是通过试验,错误和反馈进行了优化的,类似于人类的学习过程。机器学习及其算法可以分为四种主要类型:监督学习,无监督学习,半监督学习和增强学习。这是每种类型及其应用程序的细分。**监督学习**:此方法涉及使用人类指导的标记数据集的培训机器。无监督学习的两种主要类型是群集和降低性。它需要大量的人类干预才能在分类,回归或预测等任务中实现准确的预测。标记的数据分为特征(输入)和标签(输出),教机教学机构要识别哪些元素以及如何从原始数据中识别它们。监督学习的示例包括:***分类**:用于分类数据,算法,诸如K-Neartem邻居,天真的贝叶斯分类器,支持向量机,决策树,随机森林模型排序和隐藏数据。***回归**:经常用于预测趋势,线性回归,逻辑回归,山脊回归和LASSO回归等算法,以确定结果与自变量之间的关系,以做出准确的预测。**无监督的学习**:在这种方法中,机器在没有人类指导的情况下处理原始的,未标记的数据,减少工作量。无监督的学习算法在大型数据集中发现隐藏的模式或异常,这些模式可能未被人类发现,使其适用于聚类和降低任务。通过分析数据并分组相似的信息,无监督的学习可以在数据点之间建立关系。无监督学习的示例包括自动化客户细分,计算机视觉和违规检测。基于相似性的聚类算法组原始数据,为数据提供结构。这通常用于营销以获取见解或检测欺诈。一些流行的聚类算法包括层次结构和K-均值聚类。此迭代过程随着时间的推移增强了模型的准确性。维度降低在保留重要属性的同时减少数据集中的功能数量,使其可用于减少处理时间,存储空间,复杂性和过度拟合。特征选择和特征提取是使用两种主要方法,其中包括PCA,NMF,LDA和GDA在内的流行算法。半监督学习通过将少量标记的数据与较大的原始数据结合在一起,在受监督和无监督学习之间取得了平衡。与无监督学习相比,这种方法在识别模式和做出预测方面具有优势。半监督学习通常依赖于针对两种数据类型培训的修改后的无监督和监督算法。半监督学习的示例包括欺诈检测,语音识别和文本文档分类。半监督学习:通过伪标记和传播自训练算法增强模型的准确性:这种方法利用了称为伪标记的现有的,有监督的分类器模型来微调数据集中的较小的标记数据集。伪标记器然后在未标记的部分上生成预测,然后将其添加回数据集中,并具有准确的标签。标签传播算法:在标签传播中,未标记的观测值通过图神经网络中的动态分配机制接收其分配的标签。数据集通常以一个已经包含标签的子集开始,并标识数据点之间的连接以传播这些标签。概率:IB(增加爆发)-30%此方法可以快速识别社区,发现异常行为或加速营销活动。强化学习:强化学习使嵌入在AI驱动软件计划中的智能代理能力独立响应其环境,并做出旨在实现预期结果的决策。这些药物是通过反复试验的自我训练,获得了理想的行为和对不良行为的惩罚,最终通过积极的加强来达到最佳水平。强化学习算法的示例包括Q学习和深度强化学习,这些学习通常依赖大量的数据和高级计算功能。基于神经网络和深度学习模型领域内的基于变压器的体系结构,Chatgpt利用机器学习能力来掌握和制作模仿人类之间的对话互动。
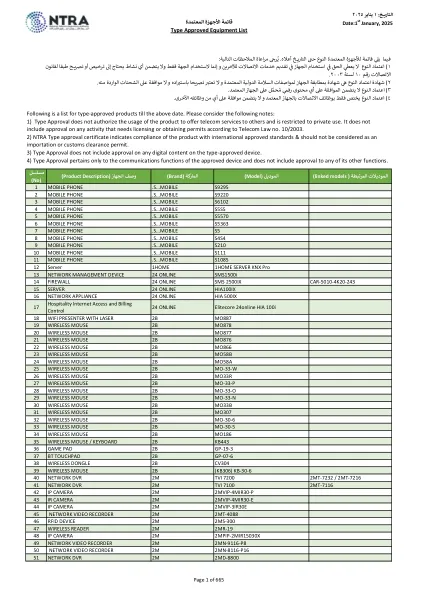
类型批准的设备清单
18带有激光2B MO887的WiFi主持人19无线鼠标2B MO878 20无线鼠标2B MO877 21无线鼠标2B MO876 22无线鼠标2B MO866 23无线鼠标2B MO58B 24无线无线鼠标2B MO58A 25无线鼠标2B MO-33-33-3 26-exeless鼠标2B 28无线鼠标2B 27无线鼠标2B 27无线鼠标2B 27无线鼠标2B 27无线243.33-pr 27 b.27 hove nevelse house house house鼠标2B 27无线电话 MO-33-O 29 WIRELESS MOUSE 2B MO-33-N 30 WIRELESS MOUSE 2B MO33B 31 WIRELESS MOUSE 2B MO307 32 WIRELESS MOUSE 2B MO-30-6 33 WIRELESS MOUSE 2B MO-30-5 34 WIRELESS MOUSE 2B MO186 35 WIRELESS MOUSE / KEYBOARD 2B KB443 36 GAME PAD 2B GP-19-3 37 BT TOUCHPAD 2B GP-07-6 38 WIRELESS DONGLE 2B CV304 39 WIRELESS MOUSE 2B (KB306) KB-30-6 40 NETWORK DVR 2M TVI 7200 2MT-7232 / 2MT-7216 41 NETWORK DVR 2M TVI 7100 2MT-7116 42 IP CAMERA 2M 2MVIP-4MIR30-P 43 IR CAMERA 2M 2MVIP-4MIR30-E 44 IP CAMERA 2M 2MVIP-3IR30E 45 NETWORK VIDEO RECORDER 2M 2MT-4088 46 RFID DEVICE 2M 2MS-300 47 WIRELESS READER 2M 2MR-19 48 IP CAMERA 2M 2MPIP-2MIR15030X 49 NETWORK VIDEO RECORDER 2M 2MN-9116-P8 50 NETWORK VIDEO RECORDER 2M 2MN-8116-P16 51 NETWORK DVR 2M 2MD-8800

音调演示的类型:
第二次向投资者提供资金。这是一个更深入的演示,共享有关项目的详细信息,并回答问题。资金宣传的目标是说服听众合作,无论是提供资金,专业知识,联系或资源。持续时间:7至10分钟。电梯音高是资金最常见的音高之一。如果您做得很好,以激发投资者的兴趣,则可能会要求您展示一个长格式的音调。这个更长的演示文稿将使您更详细地解释您的业务想法。准备好的音高!旨在增强您在传递电梯和想法俯仰方面的技能。这些简洁的演讲对于给人留下深刻的第一印象并吸引潜在投资者或合作伙伴的兴趣至关重要。该程序主要关注这些较短的音高格式,但重要的是要注意,您所学的基本原理和技术同样适用于更长形式的演示。为音高甲板做准备:如何创建电梯音高电梯俯仰是一种解释创业公司价值,项目的看法以及将带来什么好处的方式。有三个基本组成部分:

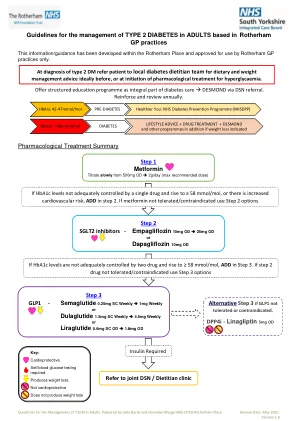
类型2糖尿病指南
对于此类中的所有药物: - 一旦确认二甲双胍可耐受性(通常是一个月后) - 如果不耐受或指示二甲双胍,则可以用作单一疗法 - 有关糖尿病性酮症酸中毒(DKA)风险增加的律师(DKA)和急性疾病的病假规则。dka可能发生正常糖血症,碳水化合物非常低或生酮饮食,当低内源性胰岛素产生/增加胰岛素需求(限制食物摄入量,酒精滥用)时 - 考虑量耗尽的风险(尤其是 div>> div>)在75岁以上的患者中) - 如果有液体流失/脱水暂时停止SGLT2I-就可能的和严重的副作用提供建议,例如Fournier的坏疽,尿路感染Empagliflozin-起始剂量empagliflozin-起始剂量10mg OD -10mg OD-较紧的Glycemic Control,EGFR≥60的更易GRY,dive to 25mg od od od od od 25mg od oc od od od od od od od od od od 25mg。

类型1糖尿病和covid-19
上下文:严重的急性呼吸综合征冠状病毒2(SARS-COV-2)感染通常会损害呼吸系统,但同样可能会损害内分泌器官的功能。甲状腺功能障碍和高血糖是SARS-COV-2感染的常见内分泌并发症。1型糖尿病(T1D)和相关并发症的发作,包括糖尿病性酮症酸中毒(DKA),住院和死亡,被认为在2019年冠状病毒病(COVID-19)大流行期间有所增加。本研究的目的是回顾有关T1D的发病率以及自19岁大流行以来的可用数据。证据获取:使用电子数据库PubMed和Google Scholar进行了文献综述。使用关键字“ T1D,T1DM,类型1 DM或类型1糖尿病”,“冠状病毒,SARS-COV-2或COVID-19”用于搜索这些数据库。标题和摘要进行了选择,然后在全文中审查了相关的研究。结果:Atotalof 25手稿304 identifiedStudiesWeresneleclectected。WEWERE15(60%)多中心WideStudies。有关T1D,住院和死亡的发病率的数据在各国之间并不一致;然而,在19日大流行期间,DKA的发病率和严重程度似乎更高。本研究的数据收集表明,Covid-19可能会或不会增加T1D的发生率。尽管如此,它与T1D患者的DKA发病率和严重程度较高有关。这一发现可能表明抗病毒药并不能完全保护SARS-COV-2感染的内分泌并发症,从而促进了替代方法的应用。结论:结合减少SARS-COV-2进入细胞并调节感染免疫反应的药物是治疗COVID-19的另一种实用方法。
