XiaoMi-AI文件搜索系统
World File Search System据预测

使用多模态数据预测学习者在自适应评估中的努力行为
除了所需的知识之外,还有许多因素影响学习者在某项活动上的表现。学习者在任务上的努力被认为与他们的教育成果密切相关,反映了他们参与该活动的积极性。然而,努力不是直接可观察到的。多模态数据可以提供对学习过程的额外见解,并可能允许努力估计。本文提出了一种在自适应评估环境中对努力进行分类的方法。具体来说,在自适应自我评估活动期间,使用日志和生理数据(即眼动追踪、脑电图、腕带和面部表情)捕捉了 32 名学生的行为。我们对多模态数据应用 k 均值来聚类学生的行为模式。接下来,我们根据发现的行为模式,使用隐马尔可夫模型 (HMM) 和维特比算法的组合,预测学生完成即将到来的任务的努力。我们还将结果与其他最先进的分类算法(SVM、随机森林)进行了比较。我们的研究结果表明,HMM 可以比其他方法更有效地编码努力与行为之间的关系(由多模态数据捕获)。最重要的是,该方法的实际意义在于,通过建立行为之间的关系,派生出的 HMM 还可以精确定位向学习者实时提供预防/规范反馈的时刻

团结起来建设工人经济
英国顶级公司的利润增长了 47%,但据预测,工人的实际工资可能会遭遇 100 年来的最大降幅。与此同时,食品银行慈善机构特鲁塞尔信托 (The Trussell Trust) 每 13 秒就会发放一次紧急食品包裹,因为在生活成本危机中需求激增。

NCAC 公司计划 2023-2028
财务可行性和投资 救济院是人们的家,我们必须对其进行投资,以满足居民和潜在受益人的满意度,并满足我们自己的体面住房标准,其中包括热舒适度。据预测,NCAC 救济院是 NCHA 投资组合中维护成本最高的。它们还拥有最低的租金收入来支持投资。此外,几乎所有 NCAC 住房在热舒适度方面都存在改造问题。

利用第四次工业革命克服新加坡武装部队面临的挑战...
多年的国民服役经验,现在是时候对其当前状况进行盘点,并展望未来,确定其眼前之外的挑战。首先,作者认为,新加坡武装部队需要通过采用已经变得更加普遍和负担得起的第四次革命技术来提高其作战效能,否则它将失去相对于其地区邻国的技术和质量优势。其次,据预测,新加坡武装部队将面临迫在眉睫的人力短缺,人力减少高达 30%。这可能会阻碍其继续以目前的规模和作战节奏执行全方位作战的能力。后一个挑战意味着新加坡武装部队更有必要继续投资和利用技术作为力量倍增器。


人工智能和机器人 - arXiv
如今,“人工智能”一词涵盖了机器的整个概念,即在操作和社会影响方面都具有智能的机器。预计到 2024 年,人工智能市场将达到 3 万亿美元,行业和政府资助机构都在大力投资人工智能和机器人技术。随着我们周围信息的可用性不断增长,人类将越来越依赖人工智能系统来生活、工作和娱乐。鉴于人工智能系统的准确性和复杂性不断提高,它们将被用于越来越多样化的领域,包括金融、制药、能源、制造、教育、交通和公共服务。据预测,人工智能的下一阶段是增强智能时代。无处不在的传感系统和可穿戴技术正在推动智能嵌入式
人工智能和机器人技术 - arXiv
如今,“人工智能”一词涵盖了机器的整个概念,即在操作和社会影响方面都具有智能的机器。随着人工智能市场规模预计到 2024 年将达到 3 万亿美元,行业和政府资助机构都在大力投资人工智能和机器人技术。随着我们周围信息的可用性不断增长,人类将越来越依赖人工智能系统来生活、工作和娱乐。鉴于人工智能系统的准确性和复杂性不断提高,它们将用于越来越多样化的领域,包括金融、制药、能源、制造、教育、交通和公共服务。据预测,人工智能的下一阶段是增强智能时代。无处不在的传感系统和可穿戴技术正在推动智能嵌入式的发展

印度 STEM 领域的女性:挑战与机遇
我们所熟知的“工作”正在发生变化。越来越多的因素正在改变就业格局,从技能成果和特定行业的就业创造到生育率和家庭规模。麦肯锡公司估计,到 2030 年,全球可能有 4000 万至 1.6 亿女性需要转换职业,从事更高技能的工作。此外,据预测,由于自动化,近 1200 万印度女性可能会面临失业。在这种背景下,当我们面临日益激烈的就业前景时,什么方法可能有助于让女性留在印度劳动力队伍中?通过二手研究和对利益相关者的采访,本系列简报强调了不同主题领域的性别响应原则,这些原则可以促进和利用女性的劳动力参与。

自我意识车辆 - CORE
传感技术(小型化、分布式传感器网络)的进步与计算能力的提高相结合,显著提高了感知能力、实时决策/推理能力和不确定性下的动态规划能力以及大数据预测分析能力,为实现自主系统能力奠定了基础。这些进步为自我感知车辆开辟了设计和操作空间,这些车辆能够评估自己的能力并调整其行为以完成分配的任务或修改任务以反映其当前能力。本文讨论了自我感知车辆的概念以及充分利用该概念所需的相关技术。自我感知飞机、航天器或系统是指能够了解其内部状态、对周围环境具有态势感知、能够评估其当前能力并将其投射到未来、了解其任务目标并能够在不确定的情况下就其实现任务目标的能力做出决策的飞机、航天器或系统。
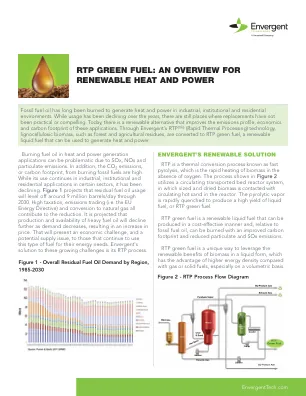
RTP 绿色燃料
在供热和发电应用中燃烧燃料油可能会产生问题,因为会产生 SOx、NOx 和颗粒物排放。此外,燃烧化石燃料产生的 CO 2 排放量或碳足迹很高。虽然某些行业的工业、机构和住宅应用中仍在继续使用燃料油,但使用量一直在下降。图 1 预测,到 2030 年,残余燃料油使用量将稳定在 900 万桶/天左右。高税收、排放交易(即欧盟能源指令)和天然气转换都有助于减少使用量。据预测,随着需求的减少,重质燃料油的产量和供应量将进一步下降,从而导致价格上涨。对于那些继续使用这种燃料来满足能源需求的人来说,这将带来经济挑战和潜在的供应问题。Envergent 针对这些日益严峻的挑战的解决方案是其 RTP 工艺。