XiaoMi-AI文件搜索系统
World File Search System控制应用程序

基于四元数和动态逆的无人机精确航迹控制
知识共享署名许可协议( http : / / creativecommons.org / licenses / by / 4.0 ),其中这是一篇开放获取的文章,根据知识共享署名许可协议( http : / / creativecommons.org /许可/ by/ 4.0 ),其中

船舶操控台控制界面人机工程设计标准研究
控制器等方面提出了工效学设计要求。 从国外组织来看,国外涉及船舶驾驶室操控界面的标准主要包括:国际海事组织IMO 于2000 年制定的标准《船桥设备和布局的工效学指南》( MSC/ Circ.982 ) [16] ,内容涉及船桥(包括驾驶室)布置、 作业环境、工作站布置、报警、控制界面、信息显示、 交互控制等7 个方面的驾驶室人机界面设计要求。国际海上人命安全公约SOLAS 于2007 年制定的标准《船桥设计、设备布局和程序》( SOLAS V/15 ) [17] , 内容涉及驾驶室功能设计、航海系统及设备设计、布置、船桥程序等,其显着特点是对于驾驶室团队管理作出相关要求,包括船桥程序、船员培训等。 从各个国家来看,美、英等西方国家在军事系 统工效学方面的研究已具有较大的规模,也制定了 一系列军用标准。美国军方军事系统的人机工程学设计准则包括“ 人机工程系统的分析数据” ( MIL.H.sl444 ) [118] , “ 军事系统人机工程学设计准则” ( MIL.STD.1472F ) [19] ,以及1999 年修订的“ 人机工程过程和程序标准” ( MIL.STD.46855A ) [20] 。 MIL-STD-1472 的第一版发布于20 世纪60 年代( 1968 年),在第二次世界大战期间,当时各交战国竞相发展新的高性能武器装备,但由于人机界面设计上的不合理,人难以掌握这些新性能的武器,导致发生了许许多多事故。因此,二次大战结束后,首先美国陆航部队(以后成为美国空军)和美国海军建立了工程心理学实验室,进行了大量的控制器、显示器等的人因素研究,获得了大量的数据,并开始将这些研究成果汇编成手册或制订成各种有关人类工程学的标准或规范。 MIL-STD-1472 就是在这样的时代背景下产生 的。该标准是为军用系统、子系统、设备和设施制定通用人类工程学设计准则,由美国陆军、海军和空军等多个单位评审,美国国防部批准,并强制性要求美国国防部所有单位和机构使用,具有较广泛的影响。 该标准在控制 - 显示综合和控制器章节有针对控制器 通用设计规则的阐述。 美国在船舶人机工程领域的投入力度也较大,不但开展了一系列的船舶人机工程专项试验,而且颁布了多项船舶人机工程设计标准和文件,主要侧重于研究人机环境对船舶的战斗力的影响。其中, ASTMF 1166—88 海军系统装备和设施的人因素工程设计标准是一个通用型标准,涵盖了控制、显示和告警、楼梯和台阶、标识和计算机、工作空间布局等海军设计的所有元素[21 ] 。 英国国防部于2005 年组织建立的船舶SRDs 系统,对船舶人机界面涉及的多方面问题进行梳理和整合,将人机界面研究作为船舶系统设计的一个重要环节,以提高人机界面设计在船舶项目中的优先级别。 英国国防部 2009 年的 MARS 项目计划,将早期人机 界面设计干预纳入到舰艇设计系统中,并委任专业公
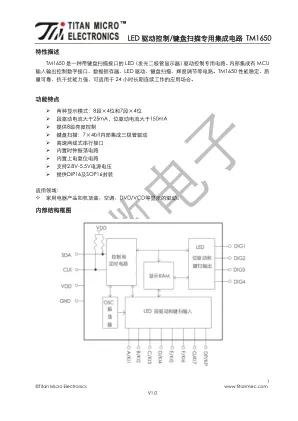
LED 驱动控制/键盘扫描专用集成电路TM1650
接口和TM1650 通信,在输入数据时当SCL 是高电平时,SDA 上的信号必须保持不变;只有SCL 上的 时钟信号为低电平时,SDA 上的信号才能改变。数据输入的开始条件是SCL 为高电平时,SDA 由高变

算法控制、角色压力与员工变革态度的关系研究
技术和算法越来越多地渗透到日常工作的管理中,特别表现出在员工控制中的巨大潜力。为了深入探索算法控制对员工对数字传输背景下改变态度的态度的影响,这项研究以角色理论为基础,并深入了解算法控制的概念,构建了一个调解模型,包括算法,算法,责任控制,员工的承诺,雇员的承诺,以改变和变化。利用在线和离线问卷调查方法中,本研究验证了算法控制对就业对变革及其基础途径的态度的影响。研究结果表明,算法控制大大加剧了员工的角色压力,随后提高了他们对变革的抵抗力,并相应地减少了他们对变革的承诺。这项研究不仅为组织环境中算法控制的研究开辟了新的理论观点,而且还为努力实施科学问题的组织提供了宝贵的实践指导。

应用程序样本 - 质量控制-DKFZ-TAPESTATION- ...
碎裂后,将DNA末端修饰以进行下游目标富集,包括最终修复,A尾和适配器连接。修改步骤后,使用Ampure XP珠纯化扩增的DNA样品。用4200贴抽系统和D1000筛选分析确定纯化DNA的尺寸和浓度(图5)。根据30μl的可用体积计算总DNA量。根据Agilent低输入SURESELECT XT人类所有外显子V5方案¹,库应具有225至275 bp的峰值大小。只有两个样品略低于建议的225 bp。以下部分中的杂交协议需要每个扩增的DNA库的750 ng。两个DNA样品略低于建议的总DNA量(图5)。三个样本没有根据大小或定量来满足QC标准,而是通过工作流程处理的,因为自动库的准备不允许排除单个样本。


基于近端策略优化算法及视觉感知的机械臂导纳控制研究
在现代操纵器交互任务中,由于环境的复杂性和不确定性,准确的对象表面建模通常很难实现。因此,改善操纵器与环境之间相互作用的适应性和稳定性已成为相互作用任务的重点之一。针对操纵器的互动任务,本文旨在在视觉指导下实现良好的力量控制。因此,基于Mujoco(带有触点的多关节动力学)物理引擎,我们为操纵器构建了交互式仿真环境,并创新地集成了基于位置的视觉伺服控制和录取控制。通过深度强化学习(DRL)中的近端策略优化(PPO)算法,有效地集成了视觉信息和力量信息,并提出了结合视觉感知的接收性控制策略。通过比较实验,将允许控制与视觉感知相结合,并将力控制的整体性能提高了68.75%。与经典的入学控制相比,峰值控制精度提高了15%。 实验结果表明,在平坦和不规则的凹面环境中,允许控制与视觉感知结合表现良好:它不仅可以准确地执行视觉构成的力控制任务,而且还可以在各种接触表面上维持施工力,并迅速适应环境变化。与经典的入学控制相比,峰值控制精度提高了15%。实验结果表明,在平坦和不规则的凹面环境中,允许控制与视觉感知结合表现良好:它不仅可以准确地执行视觉构成的力控制任务,而且还可以在各种接触表面上维持施工力,并迅速适应环境变化。在精确组装,医疗援助和服务操纵器的领域中,它可以提高操纵器在复杂和不确定的环境中的适应能力和稳定性,从而促进智能操纵器的自主操作的发展。

Aurix™TC3XX电动机控制应用程序套件开始
N.C. 39 40 N.C. VEXTB 2 1 1 CHC_IN N.C. 37 38 /SOFF GND 4 3 GND N.C. 35 36 N.C. N.C. 6 5 N.C. N.C. 33 34 N.C. N.C. 8 7 N.C. /ERR 31 32 N.C. /NH 10 9 N.C. CSN 29 30 CLK_SPI N.C. 12 11 N.C. MOSI 27 28 CGPWM_P小姐(PRIM.COIL)14 13 CGPWM_N(PRIM.COIL)N.C. 25 26 ENA在16 15 N.C. N.C. 23 24 N.C. HALL_C 18 17 HALL_B N.C. 21 22 N.C. ENC_B 20 ENC_A N.C. 19 20 PFB2 N.C. 22 21 INC_C_C_C_C_C_ENABLE 17 18 PFB3 IL1 24 23 N.C. N.C. 16 16 GS0MS IL2 30 29 /ih3 cos-(VCC /2)9 10 Col+ N.C. 32 31 N.C. BEMF_U 8 8 volt_dc N.C. 34 33 N.C. SIN-(VCC/2)5 6 IDC_HS 36 35 BEMF_V GND 3 4 GND VO3 VO3 38 37 37 N.C. VCC_IN 1N.C. 39 40 N.C. VEXTB 2 1 1 CHC_IN N.C. 37 38 /SOFF GND 4 3 GND N.C. 35 36 N.C. N.C. 6 5 N.C. N.C. 33 34 N.C. N.C. 8 7 N.C. /ERR 31 32 N.C. /NH 10 9 N.C. CSN 29 30 CLK_SPI N.C. 12 11 N.C. MOSI 27 28 CGPWM_P小姐(PRIM.COIL)14 13 CGPWM_N(PRIM.COIL)N.C. 25 26 ENA在16 15 N.C. N.C. 23 24 N.C. HALL_C 18 17 HALL_B N.C. 21 22 N.C. ENC_B 20 ENC_A N.C. 19 20 PFB2 N.C. 22 21 INC_C_C_C_C_C_ENABLE 17 18 PFB3 IL1 24 23 N.C. N.C. 16 16 GS0MS IL2 30 29 /ih3 cos-(VCC /2)9 10 Col+ N.C. 32 31 N.C. BEMF_U 8 8 volt_dc N.C. 34 33 N.C. SIN-(VCC/2)5 6 IDC_HS 36 35 BEMF_V GND 3 4 GND VO3 VO3 38 37 37 N.C. VCC_IN 1

通过应用程序
摘要:贝叶斯优化(BO)在大量控制应用程序中对昂贵的黑盒功能进行全局优化的数据效果表现出了巨大的希望。传统的BO是无衍生的,因为它仅依赖于性能函数的观察来找到其最佳。最近,已经提出了所谓的第一阶BO方法,该方法还将绩效函数的梯度信息进一步加速收敛。一阶BO方法主要利用标准采集功能,而间接使用内核结构中的梯度信息来学习性能功能的更准确的概率替代物。在这项工作中,我们提出了一种直接利用性能函数(Zeroth-order)及其相应梯度(第一阶)评估的梯度增强的BO方法。为此,提出了一个新型的基于梯度的采集功能,可以识别性能优化问题的固定点。然后,我们利用从多目标优化的想法来制定一种e显策略,以找到最佳贸易点的查询点,这些查询点是传统的Zeorth-rorder-rorde获取功能与拟议的基于梯度的采集函数之间的。我们展示了如何使用拟议的获取 - 增强梯度增强的BO(AEGEBO)方法来加速基于策略的增强型学习的收敛,通过将噪声观察结果结合到可以直接从闭环数据中估算的奖励函数及其梯度的噪声。将AEGBO的性能与传统的BO和基准LQR问题上众所周知的增强算法进行了比较,我们始终如一地观察到在有限的数据预算中显着提高了性能。
