XiaoMi-AI文件搜索系统
World File Search System数据检索

1 人力资源的技术决定因素...
越来越多的组织正在从传统的纸质文件转向数字归档系统,以获得竞争优势并改善对人力资源和人力资源相关信息的访问。这一数字化过程不仅使数据更易于访问,而且还提高了其在人力资源决策中的利用率。因此,人力资源相关信息变得更加全面、准确和最新。本研究专门调查了技术因素对坦桑尼亚地方政府当局 (LGA) 人力资源信息系统 (HRIS) 有效性的影响。该研究结合了描述性和推论性统计数据,包括有序逻辑回归分析,以检查技术特征对人力资源信息系统 (HRIS) 有效性的影响。研究结果表明,兼容性、复杂性、实用性和可靠性等因素在确定 HRIS 中数据检索的及时性、全面性和准确性方面起着至关重要的作用。该研究为通过采用计算机化的 HRIS 来改进 LGA 的人力资源管理实践提供了宝贵的见解。所讨论的方法增强了决策能力并改善了信息访问,有助于实现组织目标。它还强调了定期更新系统以跟上不断变化的技术形势的重要性。

LLM是否准备好发现现实世界的材料?
大语言模型(LLMS)创造了令人兴奋的可能性,以加速材料科学中的科学发现和知识传播。虽然LLM已成功地用于选择科学问题和基本挑战,但他们目前不属于实用的材料科学工具。从这个角度来看,我们在材料科学中显示了LLM的相关故障案例,这些案例揭示了与理解和推理有关复杂,相互联系的材料科学知识的当前局限性的局限性。鉴于这些缺点,我们概述了建立基于域知识的材料科学LLM(Matsci-llms)的框架,该框架可以实现假设产生,然后进行假设检验。在很大程度上,获得表现型Matscilms的途径在于构建源自科学文献中采购的高质量的多模式数据集,其中各种信息提取挑战持续存在。因此,我们描述了关键材料科学信息提取挑战,这些挑战需要克服,以构建大规模的多模式数据集,以捕获有价值的材料科学知识。旨在实现解决这些挑战的连贯努力,我们概述了通过六个互动步骤将Matsci-llms应用于现实世界材料发现的路线图:1。材料查询; 2。数据检索; 3。材料设计; 4。Insilico评估; 5。实验计划; 6。实验执行。最后,我们在可持续性,包容性和政策制定方面讨论了Matscillms对社会的一些广泛含义。

mick:与...
癌症仍然是全球健康挑战,其发病率和死亡率很高。在2020年,癌症造成了近1000万人死亡,这使其成为全球第二大死亡原因。但是,化学抗性的出现成为成功治疗患者的主要障碍。人类肠道微生物在通过其代谢物调节药物疗效中的作用而被认可,最终导致化学抗性。目前可用的数据库仅限于有关肠道微生物组与药物之间相互作用的知识。然而,尚未报道包含人类肠道微生物基因序列的数据库及其对化学疗法对癌症患者疗效的影响。为了应对这一挑战,我们提出了微生物化学抗性知识库(MICK),这是一种与化学耐药性癌症相关的综合数据库分类微生物基因序列。mick包含160万个与化学抗性和药物代谢相关的29种基因类型的序列,并从最近的文献和序列数据库中手动策划。数据库支持有效的数据检索和分析,为序列搜索和下载功能提供用户友好的Web界面。Mick旨在通过作为研究人员的宝贵资源来促进癌症中化学抗性的理解和缓解

根据机器学习应用程序的微生物组数据的全面概述:分类,可访问性和未来方向
宏基因组学,代谢组学和元蛋白质组学通过将独立的见解与其组成和功能潜力提供了无关的见解,从而显着提高了我们对微生物群落的了解。然而,这个领域的一个关键挑战是缺乏与原始数据相关的标准和全面的元数据,从而阻碍了执行强大的数据分层并考虑混杂因素的能力。在这篇全面的综述中,我们将公开可用的微生物组数据分为五种类型:shot弹枪测序,扩增子测序,元转录组,代谢组和元蛋白质组数据。我们探讨了元数据对数据再利用的重要性,并解决了收集标准化元数据的挑战。我们还评估收集宏基因组数据的现有公共存储库的元数据收集的局限性。本综述强调了元数据在解释和比较数据集中的重要作用,并强调了对标准化元数据协议的需求,以充分利用元基因组数据的潜力。此外,我们探讨了在元数据检索中实施机器学习(ML)的未来方向,并为有前途的途径提供了对微生物群落及其生态作用的更深入了解。利用这些工具将增强我们对各种生态系统中微生物功能能力和生态动态的见解。最后,我们强调了ML模型开发中至关重要的元数据作用。

营养材料中的计算策略
目的本研究旨在通过整合来自Litvar数据库,PubMed和GWAS目录的多个来源的数据来创建与营养相关的人类遗传多态性的全面和精心策划的数据集。该合并资源旨在通过提供可靠的基础来探索与营养相关性状相关的遗传多态性,以促进营养学的研究。方法我们开发了一个数据集成管道来组装和分析数据集。管道从Litvar和PubMed执行数据检索,数据合并以构建统一的数据集,全面网格列表的定义,通过网格查询该数据集以检索相关的遗传关联,并使用GWAS目录将输出交叉引用。结果结果数据集汇总了有关遗传多态性和与营养相关性状的广泛信息。通过网格查询,我们确定了与营养相关性状相关的关键基因和SNP。与GWAS目录的交叉引用提供了有关与这种遗传多态性相关的潜在影响或风险等位基因的见解。共发生的分析揭示了有意义的基因 - 基因相互作用,推进了个性化的营养和营养学研究。结论此处介绍的数据集合并并组织有关与营养相关的遗传多态性的信息,从而详细探讨了基因 - 迪特相互作用。该资源通过提供标准化和全面的数据集来推进个性化的营养干预措施和营养学研究。数据集的灵活性允许其应用于其他遗传多态性研究。
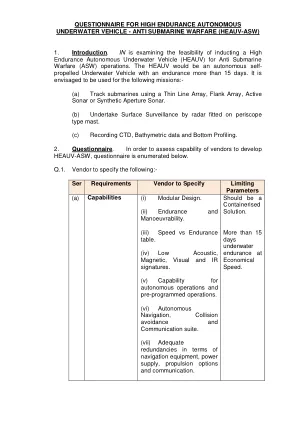
反潜战 (HEAUV-ASW) 1. 简介...
Q.14。降低/提升/部署 HEAUV 的机制是什么?该机制可以安装在任何船只上,如 OSV、军舰等吗?如果可以,要求和相关时间表是什么?Q.15。HEAUV 从岸上和海上船舶部署时需要哪些配件?指出日常工作、充电/再充电和其他活动所需的电源,以方便从船上进行操作?还应提及与船上电源的兼容性。Q.16。运输 HEAUV 的容器类型有哪些,运输(海陆)需要满足哪些要求?还请说明集装箱的尺寸、重量、电源和空调要求?问 17。预计在船上和岸上装载和维护 HEAUV 所需的基础设施是什么?问 18。当尝试未经授权的数据检索时,HEAUV 是否具有数据保护/销毁功能?如果有自毁模式,请说明其详细信息?问 19。HEAUV 的设计是否本土化(以后需要设计的知识产权)?HEAUV 的所有组件(包括有效载荷)将从哪里进口?还请说明预期的 IC 百分比?还请提及相关软件的详细信息(是否为本土软件等)?Q.20。请详细说明与用于 ASW 任务的 HEAUV 开发相关的自主导航、耐力、指挥和控制、传感器等使能技术的本土化情况?Q.21。项目批准令授予后,原型开发的预计时间表是什么?是否愿意在 Make II 下推进原型开发,并在购买印度 IDDM 计划下进行后续开发?Q.22。是否愿意提供全面的 AMC 和/或费率维修合同。简要说明 AMC/RRC 的范围和成本。Q.23。提供以下项目的预算报价:-

社交媒体和生成人工智能研究的披露标准:走向透明度和可复制性
摘要 社交媒体主导着当今的信息生态系统,为社会研究提供了宝贵的信息。市场研究人员、社会科学家、政策制定者、政府实体、公共卫生研究人员和从业人员都认识到社交数据具有激发创新、支持产品和服务、描述公众舆论和指导决策的潜力。挖掘这些丰富数据集的吸引力是显而易见的。然而,存在数据滥用的潜在风险,这凸显了研究中同样巨大而根本的缺陷:没有程序标准,透明度低。由于专有算法,收集和分析社交媒体数据的过程的透明度通常受到限制。人工智能 (AI) 引入的虚假发现和偏见表明了这种缺乏透明度给研究带来的挑战。社交媒体研究仍然是一个虚拟的“狂野西部”,没有关于数据检索、预处理步骤、分析方法或解释的明确报告标准。使用新兴的生成式人工智能技术来增强社交媒体分析可能会破坏研究结果的有效性和可复制性,可能将这项研究变成一个“黑箱”企业。需要对社交媒体分析和报告提供明确的指导,以确保最终研究的质量。在本文中,我们提出了基于既定科学实践的评估使用社交媒体数据进行研究质量的标准。我们提供明确的文档指南,以确保在研究和应用中正确、透明地使用社交数据。提出了一份满足最低报告标准的披露要素清单。这些标准将使学者和从业者能够使用数字数据评估研究结果的质量、可信度和可比性。

文献计量研究
方法:2022 年 7 月 28 日,从 Web of Science 核心合集检索了 2001 年 1 月 1 日至 2020 年 12 月 31 日期间发表的有关康复机器人主题的报告。文献类型仅限于“文章”和“会议”(不包括“评论”类型),以确保我们对该研究随时间演变的分析具有高度有效性。我们使用 CiteSpace 进行共现和共引分析,并可视化该研究领域的特征和新兴趋势。使用中介中心性和爆发强度等指标来识别具有里程碑意义的出版物。结果:通过数据检索、清理和去重,我们检索到了 2001 年至 2020 年期间出版的关于康复机器人主题的 9287 篇出版物和其中引用的 110,619 篇参考文献。Mann-Kendall 检验的结果表明,与康复机器人相关的出版物数量(P <.001;S t =175.0)和引用数量(P <.001;S t =188.0)均呈现显著的逐年增加趋势。共现结果显示有 120 个类别与康复机器人研究相关;我们使用这些类别来确定研究关系。共引结果确定了 169 个共引集群,这些集群表征了该研究领域及其新兴趋势。最突出的标签是“软机器人技术”(爆发强度为 79.07),它已成为上、下肢康复领域备受关注的主题。此外,任务导向的上肢训练、机器人辅助下肢康复的控制策略以及外骨骼机器人的动力都是当前研究的热门话题。结论:我们的工作为康复机器人的研究提供了深刻的见解,包括其在过去 20 年的特点和新兴趋势,从而为该研究领域提供了全面的了解。

r e v i w审查了不同因素与自闭症和多动症的发生之间的机制
摘要:尤其是在儿童中,神经发育障碍的发生率在最近几十年中一直在增加,这可能是由许多不同因素引起的。为了进一步解释这种情况并引起了足够的关注,这篇综述将特别详细阐述了这两种神经发育精神疾病,自闭症和注意力缺陷多动障碍(ADHD),同时分析不同环境毒素与这两种疾病之间的关系,对这两种神经发育精神疾病(ADHD)中的这两种神经发育精神疾病。这些致病因素的影响,例如重金属铅,汞,聚氯乙烯(PVC)和多氯联苯(PCB)及其强大的病原体城市的影响,将通过文献数据检索和分析详细解释。此外,其他神经递质(例如去甲肾上腺素(NE)和5-羟色胺(5-HT)信号传感因子都归结为这两种神经发育障碍,以及它们在血液中的异常浓度以及如何在实验组和对照组中的完全相反的结果。此外,其他高风险和高暴露因素可能会导致疾病,例如父母之间的酒精和吸烟,空气污染物PM2.5和PM10在环境中也将在综述中进行讨论。关键字:自闭症,ASD,ADHD,神经毒素,曝光由于本文中讨论的这些环境毒素和其他有害物质与近几十年来越来越多的自闭症和多动症儿童有关,从医学的角度来看,这一审查将提出某些简洁的指标,以最大程度地减少相关的临床和日常生活中相关的风险,以及在这些父母中的发展,以及对这些父母的态度,并在这些公共健康方面的出现,并在这些公共卫生方面依靠这些公共保健,并在这些公共卫生方面依靠这些公共健康,并在这些方面提出了这些方面的建议。通过提高对人口的认识并减少不必要的接触。

利用机器学习来增强信息探索
软件架构师,劳动力身份云,okta.inc。通过合并监督学习,无监督学习,强化学习和深度学习等技术,系统可以自动从大量的数据存储库中提取见解和模式。自然语言处理可以更深入地理解文本,而图像识别则可以从视觉数据中解锁知识。机器学习能力个性化的推荐引擎和准确的情感分析。整合知识图将机器学习模型与背景知识丰富,以增强准确性和解释性。应用程序涵盖语音搜索,异常检测,预测分析,文本挖掘和数据聚类。但是,可解释的AI模型对于实现透明度和可信度至关重要。关键挑战包括有限的培训数据,复杂的领域知识要求以及围绕偏见和隐私的道德考虑。正在进行的研究结合了机器学习,知识表示和以人为本的设计将推动智能搜索和发现。人工与人类智能之间的合作具有彻底改变信息访问和知识获取的潜力。k eywords机器学习,人工智能,搜索引擎,数据检索,自然语言处理,数据挖掘1。介绍各个领域的信息的大量增长已经更需要更好地搜索和分析数据的方法。1.1。传统的搜索引擎和数据库正在努力处理日益增长的复杂性和信息量。机器学习(ML)具有自动学习和从经验中进行改进的能力,为这一挑战提供了有希望的解决方案。通过使用机器学习算法,可以通过个性化建议,预测分析和智能数据分类来增强信息检索。本研究旨在探索机器学习的潜力,以改变信息的发现,组织和利用。通过利用机器学习技术的功能,研究人员和专业人员可以更有效地浏览大量信息,从而提供更好的决策过程和见解[1]。信息探索的背景在信息探索方面,了解该领域的历史背景和演变对于掌握机器学习技术的能力至关重要。信息探索的起源可以追溯到数据挖掘和信息检索系统的早期发展。这些系统旨在从大型数据集中提取有价值的见解,以帮助决策过程。随着时间的流逝,机器学习算法的进步改变了信息的访问,处理和分析的方式。