XiaoMi-AI文件搜索系统
World File Search System整数

量子计算
我们将考虑数字计算,因此我们有兴趣计算整数值x的整数值f(x)。这是实际计算机执行的操作。正如我们将看到的,可以将功能视为逻辑操作(和,或,不等等的组合);具有实际数字的有限优先操作也可以通过这种方式来表示,通过将实际数字的小数扩展为某些整数。计算是评估给定函数f(x)的某些过程。我们将通过电路图使用计算的抽象模型。这是函数f(x)的图形表示,它是通过一组简单的基本操作来构建的。这捕获了实际计算机操作模式的某些功能,尽管特定功能A给定电路计算是固定的,而可编程计算机可以计算我们输入程序指定的任何函数。电路模型不应过于从字面上看作为物理计算机的描述,而应作为理解如何从更简单的操作中构建所需功能的一种抽象方式。我们在这里介绍此内容主要是因为我们将在讨论量子计算的讨论中大量使用类似的图形表示。我们要代表整数x的整数值函数。我们用二进制表示法表示x,作为一串x n -1 x n -2。。。x 0。这是一个位置符号,因此不同的位乘以2的功率;这意味着

数字硬件的高效储层计算
摘要 — 我们提出了一种回声状态网络 (ESN) 的近似方法,该方法可以基于超维计算数学在数字硬件上有效实现。所提出的整数 ESN (intESN) 的储存器是一个仅包含 n 位整数的向量(其中 n < 8 通常足以获得令人满意的性能)。循环矩阵乘法被高效的循环移位运算取代。所提出的 intESN 方法已通过储存器计算中的典型任务进行验证:记忆输入序列、对时间序列进行分类以及学习动态过程。这种架构可显著提高内存占用和计算效率,同时将性能损失降至最低。在现场可编程门阵列上的实验证实,所提出的 intESN 方法比传统 ESN 更节能。

2.1:先进的处理器技术
• 独立的指令和数据存储器单元,带有 4 KB 数据缓存和 4 KB 指令缓存,以及由地址转换缓存 (ATC) 支持的独立存储器管理单元 (MMU),相当于其他系统中使用的 TLB。 • 处理器使用 16 个通用寄存器实现 113 条指令。 • 18 种寻址模式包括:寄存器直接和间接、索引、内存间接、程序计数器间接、绝对和立即模式。 • 指令集包括数据移动、整数、BCD 和浮点算术、逻辑、移位、位域操作、缓存维护和多处理器通信,以及程序和系统控制和内存管理指令 • 整数单元组织在六级指令流水线中。



密码学中的RSA算法
Φ(n):我们需要计算 Φ(n) = (P-1)(Q-1) 使得 Φ(n) = 3016 现在让我们计算私钥 d:d = (k*Φ(n) + 1) / e,其中 k 为某个整数,当 k = 2 时 d 的值为 2011。


量子计算 / jku linz < / div>
计算机科学中的核心目标之一是计算事情。在高水平上,这通常是通过开发算法来实现的,这些算法将潜在复杂的任务分解为一系列简单,标准化的操作。然后可以在(经典)硬件上执行这些标准化操作。例如,现代CPU可以在短短几秒钟内执行数十亿逻辑和算术操作,因此我们拥有大量的原始计算能力。a,原始计算能力可能并不总是足够的。存在大量的计算问题,其中可伸缩性问题甚至可以阻止超级计算机变成非常大的问题大小。此类众所周知的问题是整数分解:将A(通常是大的)数字分解为𝑛lit(𝑛= log 2(log 2(𝑁)⌋+ 1)构成素数,即整数分解a -bit编号𝑁=𝐹= 0×·××𝐹 -1,使用𝐹0,。。。,𝐹 -1∈ℕprime。(1.1)

第 3 章 自旋的基本量子统计力学...
其中 ϵ abc 是完全反对称张量,ϵ xyz = 1。该代数被称为旋转(即角动量分量)生成代数。这里,旋转不是在自旋的位置,而是在其“方向”上(加引号是因为当然不可能测量量子自旋的所有三个分量)。量子自旋的希尔伯特空间通过选择自旋算子的表示来定义。李代数的表示是一组满足对易关系的三个矩阵,对于 su (2),由 (3.1) 给出。不可约表示是一组矩阵,使得没有一个酉变换 US a U † 能使这三个矩阵块对角化。根据李代数理论,已知对于 su (2),每个整数 n 恰好有一组(最多酉变换)不可约 n × n 矩阵。出于很快就会明白的原因,对于所有整数和半整数 s ,习惯上都写为 n = 2 s + 1 。指标 s 通常被称为粒子的“自旋”,这有点令人困惑。因此,空间中固定点处的单个自旋为 s 的量子粒子具有希尔伯特空间 C 2 s +1 ,因此矩阵 S a 均为 (2 s + 1) × (2 s + 1)。正交基由任何一个矩阵的特征态给出。哪一个并不重要;任何选择的此类基都可以“旋转”(在自旋空间中!)为任何其他基。对于 s = 0,矩阵都由数字零组成;毫不奇怪,这被称为平凡表示。对于 s = 1 / 2,它变得有趣;S a = σ a ℏ / 2,其中 σ a 为
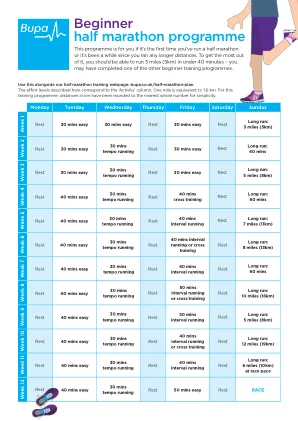
初学者半程马拉松计划
与我们的半程马拉松培训网页一起使用:bupa.co.uk/half-marathon-plan。此处描述的工作级别对应于“活动”列。一英里等于1.6公里。对于此培训计划,为了简单起见,公里的距离已四舍五入到最接近的整数。