XiaoMi-AI文件搜索系统
World File Search System构造

构造
2001 年 10 月,美国土木工程师学会 (ASCE) 董事会一致通过了政策声明 465,题为“执照和专业实践的学术前提条件”。2004 年 10 月,该政策获得一致修订。该政策支持“获得进入专业土木工程实践所需的知识体系 (BOK)。支撑该政策的信念是,未来进入专业土木工程实践所需的 BOK 将超出传统的 4 年制学士学位和所需的实践经验的范围。虽然 ASCE 认识到政策声明 465 的实施不会在一夜之间发生,但该政策有可能改变土木工程实践,并对 21 世纪建筑环境的安全性、质量、效率和可持续性产生积极影响。本文旨在描述过去一年的进展以及实施政策声明 465 的下一步措施。

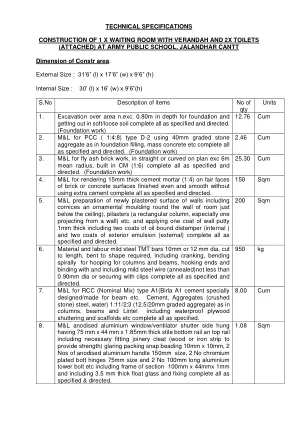
技术规格构造 1 X ...
9. M&L 铝制阳极氧化门百叶窗,具有 150mm x 44mm x 1.85mm 厚的底部横杆、150mm x 44mmx 1mm 厚的中部横杆、100mm x 44mmx 1.85mm 厚的立柱和顶部横杆,包括必要的配件细木工夹板、玻璃包装按扣压条 10mm x 10mm、200mm 长的阳极氧化铝手柄(02 号)、3 个 100mm 尺寸镀铬对接铰链、2 个 200mm 尺寸铝制塔式螺栓和铝制主体液压闭门器,名称为 3 号,通用类型,重量在 61 至 80kg 之间等,包括 100mm x 44mm x 1mm 截面框架和百叶窗,底部覆盖有 9mm 厚的预层压刨花板,一个插芯锁(品牌:Harrison),百叶窗和固定装置均按照指定和指示完成。 (主门(双门)5' x 8'6” – 01(D),门 2'6” x 6'6” – 02(D1 和 D2),窗 5' x 4' – 02(W),通风器 1'6” x 1'6” – 02(V)(均配有 ACP 面板)


金属构造剂...
图1。A)在PT/INGA/N -SI/SIO/SIO X/PT下,AO-ECL发射(AO-ECL)的方案是由EXC光子吸收触发的。b)电荷传输机制的方案,导致可见的440-nm光子在固体界面处产生。c)在PT/INGA/INGA/N -SI/SIO X/PT(CYAN曲线)和电解质吸收(灰色曲线)时,在PT/INGA/N -SI/N-SIO/SIO X/PT(灰色曲线)时,在PT/INGA/N -SI/N-SI/N-SIO/SIO X/PT(灰色曲线)处的IR 850 nm LED(棕色曲线)的归一化光谱。si bandGap由虚线的黑线表示,由AO-ECL诱导的波长的移位由红色箭头表示。d)N -Si/Sio X的XPS调查光谱,在涂层之前(橙色曲线)和N -SI/SIO X/PT的N -Si/Sio X/PT,在溅射2 nm厚的PT膜(粉红色曲线)后。

构造照明系统模型
摘要这项研究的重点是在贝宁市联邦教育学院Ekiadolor的教育目的建造汽车照明系统模型。这项研究涉及对汽车技术教育中实用教学辅助的关键需求,特别是针对对车辆照明系统的理解。该研究旨在设计和构建功能照明系统模型,该模型模拟汽车照明系统的关键操作,包括大灯,尾灯,转弯信号和制动灯。使用12伏电源系统,该模型包含了各种组件,包括电压调节器,控制机制,例如主照明开关,调光开关,闪光灯单元和紧急危害开关,以及多个照明单元。施工过程涉及在木板上系统地组装组件,全面的布线和彻底的测试程序。结果表明,构造的模型达到了26.4瓦的总功率输出,照明点在10,500伏特下运行,并受到3A保险丝系统的保护。该模型成功地证明了电能转换为光能,从而为学生提供了了解汽车照明系统的动手经验。研究得出结论,该模型是教授汽车照明系统的有效教育工具,并建议将其纳入技术和工程培训计划。在尼日利亚,在包括技术学院,教育学院(技术),理工学院和大学在内的各个机构提供了此培训。关键字:汽车教育,照明系统,技术教育,实用培训简介汽车技术教育是一项全面的计划,致力于为学生提供基本技能和知识的汽车行业。课程包括从设计和诊断到维修,维护和服务操作的各种汽车方面(Denton,2020年)。学生接受故障排除和解决各种车辆问题的培训,尤其是关注电气组件和照明等关键系统。该计划旨在为学生做好现代汽车挑战的准备,包括


HRSA-22-134 CDS 构造
购买设备项目。 创建新的独立结构或扩展现有结构以增加总面积。 改进和/或重新配置现有设施的内部布置。 安装永久固定设备。 改造和/或维修建筑物外部(包括窗户)。 供暖、通风和空调 (HVAC) 改造(包括安装气候控制和管道系统)。 电气升级和/或管道工程。 从规模、面积以及受影响的临床和非临床区域方面确定项目活动。 o 从规模、面积以及受影响的临床和非临床区域方面确定项目活动。 o 描述拟议的施工方法,例如设计/建造、有风险的施工管理、由申请人自己的力量进行或是否将使用第三方施工经理。 • 时间表 描述完成项目所需的活动或步骤。使用包含以下每项活动并确定负责人员的时间表:

构造情感的理论
古代哲学家和医生认为人类的思想是一系列精神能力。他们分裂了思想,而不是对生物学或大脑的理解,而是根据他们对真理,美丽和道德的关注来捕捉人性的本质。所讨论的能力已经在数千年中演变了,但总的来说,它们包括思维的心理类别(认知),感觉(情感)和意志(动作,以及更现代的版本,感知)。这些心理类别象征着西方文明中关于人性的珍贵叙事:情感(我们的内心野兽)和认知(进化的冠冕成就)战斗或合作以控制行为。1在这些古老的思想中伪造了情感的观点(图1)。情感神经科学从这种基于教师的方法中汲取灵感。科学家首先是最知名的英语(Pavlenko,2014; Wierzbicka,2014),例如愤怒,悲伤,恐惧和厌恶,并寻找他们难以捉摸的生物学本质(即他们的神经签名或