XiaoMi-AI文件搜索系统
World File Search System查集

癌症免疫检查点抑制剂健保给付问答集
108/03/25 ( 第 1 版 ) 108/03/28 ( 第 2 版 ) 108/04/11 ( 第 3 版 ) 108/04/22 ( 第 4 版 ) 108/05/31 ( 第 5 版 ) 108/11/08 ( 第 6 版 ) 109/03/27 ( 第 7 版 ) 109/09/21 ( 第 8 版 ) 110/10/01 ( 第 9 版 ) 111/05/13( 第 10 版 )

不使用并查集的并查集量子解码
并查集解码器是一种领先的算法方法,用于纠正表面代码中的量子误差,实现的代码阈值与最小权重完美匹配 (MWPM) 相当,且摊销计算时间与物理量子比特数近乎线性相关。这种复杂性是通过不相交集数据结构提供的优化实现的。然而,我们证明,由于双重分析和算法原因,解码器在大规模上的行为未充分利用此数据结构,并且可以对架构设计进行改进和简化以减少实践中的资源开销。为了加强这一点,我们模拟了解码器形成的擦除簇的行为,并表明在任何操作模式下,数据结构内都不存在渗透阈值。这为解码器在大规模上产生了线性时间最坏情况复杂度,即使使用忽略流行优化的简单实现也是如此。
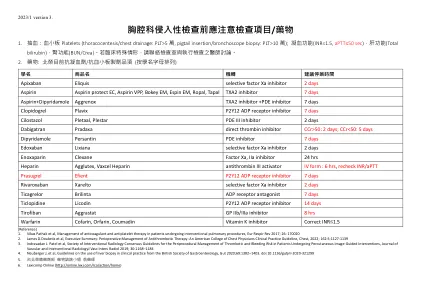
胸腔科侵入性检查前应注意检查项目/药物
[参考] 1。Vikas Pathak等人,接受介入肺部程序的患者的抗凝剂和抗血小板治疗的管理,Eur Respir Rev 2017; 26:170020 2。James D.Douketis等人,执行摘要:抗血栓疗法的围手术期管理:美国胸部医师学院临床实践指南,胸部,2022年; 162:5:1127-1139 3。Indravadan J. Patel等人,介入放射学共识学会指南,围骨围骨治疗的血栓形成和出血风险,接受经皮图像引导的患者,血管和介入放射学杂志杂志,介入介绍性和介入的放射性放射学指南。 30:1168–1184 4。neuberger J等人,关于英国胃肠病学会临床实践中使用肝活检的指南,直肠2020; 69:1382–1403。doi:10.1136/gutjnl-2020-321299
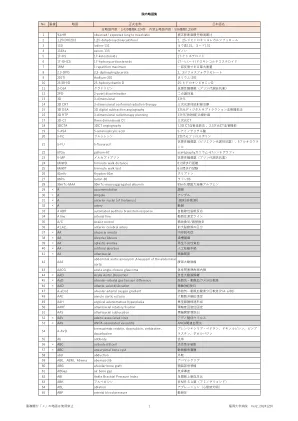


基因组编辑
1)山本2018 2)Jinek M,Chylinski K,Fonfara I等。适应性细菌免疫中可编程的双RNA引导的DNA内切酶。Science,337(6096):816-821,2012 3)Nishimasu H,Shi X,Ishiguro S等。工程CRISPR-CAS9核酸酶,具有扩展的靶向空间。Science,361(6408):1259-1262,2018 4)RAN FA,HSU PD,LIN CY等。通过RNA引导的CRISPR CAS9进行双重划痕,以增强基因组编辑特异性。Cell,154(6):1380-1389,2013 5)Vakulskas CA,Dever DP,Rettig GR等。作为核糖核蛋白复合物传递的高保真CAS9突变体可以在人造血茎和祖细胞中有效地编辑。nat Med。24(8),1216-1224,2018 6)Suzuki K,Tsunekawa Y,Hernandez-Benitez R等。通过CRISPR/CAS9介导的同源性靶向整合进行体内基因组编辑。 自然,540(7631):144-149,2016 7)Sakuma T,Nakade S,Sakane Y等。 使用Talens和CRISPR-CAS9与音高系统进行 MMEJ辅助基因敲入。 自然方案,11(1),118–133,2016 8)Sakuma T,Nishikawa A,Kume S等,使用多合一的CRISPR/CAS9矢量系统在人类细胞中的多重基因组工程。 科学报告,4:5400,2014)Nishida K,Arazoe T,Yachie N等。 使用杂种p ro kar yotic yotic and d ver teb速率自适应IM MU N E系统进行靶向核苷酸编辑。 Science,353(6305):AAF8729,2016 10)Anzalone AV,Randolph PB,Davis JR等。 搜索和重新定位基因组编辑通过CRISPR/CAS9介导的同源性靶向整合进行体内基因组编辑。自然,540(7631):144-149,2016 7)Sakuma T,Nakade S,Sakane Y等。MMEJ辅助基因敲入。自然方案,11(1),118–133,2016 8)Sakuma T,Nishikawa A,Kume S等,使用多合一的CRISPR/CAS9矢量系统在人类细胞中的多重基因组工程。科学报告,4:5400,2014)Nishida K,Arazoe T,Yachie N等。使用杂种p ro kar yotic yotic and d ver teb速率自适应IM MU N E系统进行靶向核苷酸编辑。Science,353(6305):AAF8729,2016 10)Anzalone AV,Randolph PB,Davis JR等。搜索和重新定位基因组编辑


2.3.7基因组编辑和表观基因组编辑
•这是世界上所有领域的首要发展,包括在微生物中繁殖有用的菌株,农业,渔业和牲畜产品的繁殖,以及将其应用于基因治疗,通过大学机构,大型公司,大型公司,大型公司,捐赠公司之间的密切协作,可以改善研究和发展能力。许多风险投资公司,包括酥脆的治疗剂,编辑医学,内部治疗疗法和光束治疗药,正在从事农作物开发,工业能源开发和人类疾病治疗方面的尖端研究与发展。 •CRISPR/CAS9,CAS12A,CAS13以及许多与CRISPR相关的基本技术和应用技术知识产权都得到了保护。 •Talaen的高油酸大豆的生产和工业用途已经发展。 •主动促进体内和离体基因组编辑处理。 Laber先天性黑色素症,经胸蛋白淀粉样变性和镰状细胞疾病的临床试验已经开始如体内基因组编辑治疗。 •计划进行体内基础变体疗法(镰状细胞疾病)的临床试验。 •使用ZFN和CRISPR进行基因组编辑治疗的研发临床试验以及更安全的表观基因组编辑治疗正在进行中。已有30多次临床试验参加了FDA,领先的基因治疗研究。 •新型核酸检测技术(夏洛克和检测方法)已经开发出来,并正在作为新型冠状病毒中POCT的诊断剂开发。

2.4.4 基因组编辑和表观基因组编辑
• 日本在培育有用微生物菌种、改良农畜产品、基因治疗的应用等各开发领域都处于世界领先水平,并通过与大学机构、大企业、风险投资公司、捐赠基金会等密切合作,进一步提高研发能力。 CRISPR Therapeutics、Editas Medicine、Intellia Therapeutics、Beam Therapeutics等多家创业公司正在农作物开发、工业能源开发、人类疾病治疗等领域开展前沿研发。 • 我们已获得CRISPR/Cas9、Cas12、Cas13以及大部分CRISPR相关基础技术和应用技术的知识产权。 • TALAEN 在高油酸大豆的开发和工业应用方面取得了进展。 • 积极推进体内和体外基因组编辑治疗。针对莱伯先天性黑蒙的体内基因组编辑治疗的临床试验已经开始。 • 使用 ZFN 和 CRISPR 的基因组编辑疗法以及更安全的表观遗传编辑疗法的研究、开发和临床试验正在进行中。该公司已在FDA注册了30多项临床试验,在基因治疗研究领域处于世界领先地位。 • 新型核酸检测技术(Sherlock和DETECTR)已经研发成功,正在开发作为新冠病毒的POCT诊断技术。

香港航天科技集团有限公司
回顾期内,集团录得营业额约人民币324.5百万元,较2021年同期增加约25.6%;而本公司权益持有人应占亏损约人民币46.6百万元,而2021年同期本公司权益持有人应占亏损约人民币4.1百万元。集团于2021年下半年开展航空航天业务,并于过去一年在航空航天业务上投入大量资源,包括但不限于扩充航空航天专家团队及业务发展团队,以及租赁新物业以建立航空航天制造及研究设施。因此,航空航天业务的快速扩张加上在中国惠州成立全新EMS业务营运子公司,导致行政开支大幅增加,从而导致回顾期内本公司权益持有人应占亏损增加。