XiaoMi-AI文件搜索系统
World File Search System样本
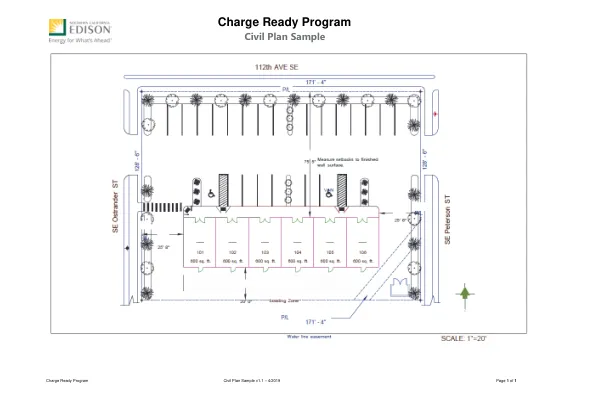




技术计划样本
1989 年 5 月,约翰·保罗二世发表了题为《教会必须学会应对计算机文化》的演讲。约翰·保罗二世……我们当然应该感谢新技术,它使我们能够将信息存储在大量人造的人工存储器中,从而可以广泛而即时地获取人类遗产中的知识。年轻人尤其迅速地适应了计算机文化及其“语言”。这当然是值得欣慰的。让我们“相信”年轻人。他们有在新的发展中成长的优势,他们有责任利用这些工具,在这个日益缩小的地球上共享的所有不同种族和阶级之间进行更广泛、更深入的对话。他们(和每个人)有责任寻找方法,利用新的数据对话和交换系统来帮助促进更大的普遍正义、对人权的更大尊重、所有个人和人民的健康发展以及充分的人性生活所必需的自由。无论年老还是年轻,让我们迎接新发现和新技术的挑战,以根植于信仰的道德观、对人的尊重和按照上帝的计划改变世界的承诺来对待它们。……让我们祈求智慧,利用“计算机时代”的潜力来服务于人类的人性和超然的使命,从而将荣耀归于上帝,一切美好的事物都来自他。




样本报告
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------》临床意义:widal检验用于对肠烧或伤寒发烧进行推定诊断。这种方法依赖于试管中的反应或感染者血液样本中存在的抗体与沙门氏菌(H和O)的特异性抗原之间的幻灯片,该抗原(H和O)产生可见的结块或凝集。- 1:80或更多的抗体滴度被认为具有硫磺具有意义。但是,显着的滴度可能与每个地区之间的人群之间和需求之间有所不同。-H凝集比O凝集素更可靠。- 凝集素素开始在第一周结束时开始出现在血清中,第二周和第3周急剧上升,滴度一直稳定到第四周,然后下降。--------------------------------------------------------------------------------- Limitations: - The Widal test may be falsely positive in patients who have had previous vaccination or infection with S. Typhi.- 除了与其他沙门氏菌物种的交叉反应性外,该测试还无法区分当前感染和对伤寒的先前感染或疫苗接种。- 伪阳性的宽大测试结果也发生在斑疹伤寒,急性恶性疟疾(特别是在儿童中),与球蛋白水平升高以及类风湿关节炎,骨髓瘤和肾动物综合征等疾病有关的慢性肝病。- 假阴性结果可能与早期治疗,骨和关节中的隐藏生物以及伤寒有关。偶尔,假阴性结果也可能是由于感染菌株的免疫原性不良,抗体反应被早期抗菌治疗或伤寒后的复发所阻断。-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------》与临床状况相关联。在
