XiaoMi-AI文件搜索系统
World File Search System熊猫


gaia-project-rules-cg.0609sm2.pdf
非常感谢Inga Keutmann的英文翻译,Christine Conrad的规则和纸牌布局,Bastian Winkelhaus为许多共享的Playtests,Johannes Grimm,Johannes Grimm校对规则手册,以及Alexandar Ortloff,Andrea ortloff,Andrea andrea dell'Agnese和Julia faeta和Julia faeta for英语规则。我们要感谢莫滕·蒙拉德·佩德森(Morten Monrad Pedersen)和他的自动团队(Automa Solo Game Mode),熊猫游戏(Panda Games),以支持有关实现游戏的支持,而巴里(Barry)提供了测试论坛。Automa团队要感谢James Ataei-Kachuei校对独奏规则。

爱切斯特杂志
亲爱的朋友们,首先,我们要向所有常规广告商表示衷心的感谢 - 我们重视您的忠诚,也热烈欢迎我们的新广告商!我们祝愿所有重返校园和高中的孩子们好运,未来充满激情。切斯特动物园将于 9 月 15 日参加“国际小熊猫日”,并于 9 月 22 日参加“世界犀牛日”,如果您能在那些日子去动物园,动物园管理员团队将随时为您庆祝熊猫和犀牛的一切!别忘了让我们的广告商知道您在 Love Chester 杂志上看到了他们的广告,没有他们就没有杂志,所以这是重要的信息!在 Facebook 和我们的新 Facebook 群组、Twitter 上关注我们的最新动态,并访问我们的网站:www.love-chester.com
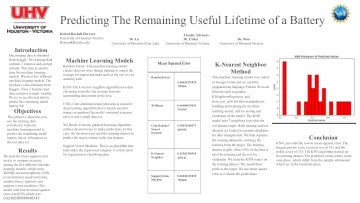
预测电池的剩余有用寿命
方法此机器学习模型是在Google Colab中编码的,我们使用了编程语言Python。我们使用诸如Pandas,KneighBorsRegressor和Train_test_split之类的库进行数据操纵,构建和培训机器学习模型,以及对模型的测试和验证。KNN模型使用7个邻居来预测测试数据集目标。将培训和测试数据集加载到熊猫数据框架上进行数据操作。然后,我们通过将功能与目标分离来分开训练数据集。培训数据集被拆分,其中80%的数据用于培训,其余数据用于验证。我们在培训数据集上训练KNN模型。然后该模型预测目标。我们使用均方根误差来评估预测。

主题:应用人工智能(APAI)
什么是计算机视觉?图像分析和计算机视觉的应用。常见的图像和视频格式(非常简短的描述 .jpeg、.tiff、.bmp、.mp4、.avi)、颜色模型:RGB、计算机中的图像表示、图像二值化(基于阈值)、图像特征 - 像素特征、灰度值作为特征、通道的平均像素值、边缘特征(Prewitt 核、Sobel 核)、纹理特征、用例:使用动物数据集进行图像分类(三类 - 狗、猫和熊猫)、带有示例的图像表示、动物数据集的描述、使用 k-NN 或其他 ML 工具进行分类(步骤的简要描述:数据收集、数据表示、将数据集拆分为训练集和测试集、训练分类器、使用 Scikit 学习工具进行评估)。


教学大纲
Python简介 - Google Colab和Jupyter笔记本,数据结构,熊猫(读,写文件,加载数据等),Numpy等。。matplotlib(区域图,散点图,线图,直方图,条形图,框图,热图,刻面,配对图),Seaborn。什么是数据科学,各种类型和数据级别,结构化与非结构化数据,定量数据,定性数据,数据科学生命周期等。数据收集和准备,缺失价值处理,数据擦洗,数据转换,探索性数据分析,人群和样本,矩和生成功能,可变性,假设测试,偏差和方差的度量。有监督的分类,例如KNN和无监督的分类,例如K-均值聚类,模型定义和培训,模型评估。特征工程,尺寸降低 - PCA,回归线性模型:线性回归,逻辑回归。

人工智能助力外语沉浸式学习
2.2 认知沉浸式房间 (CIR):展示了两种沉浸式情境(街头市场和餐厅)。沉浸式房间为对话练习提供了视觉环境。AI 代理为对话练习提供了社交环境。它们共同为学生创造了机会,让他们感觉自己仿佛身处其他地方,与智能实体(AI 代理)一起练习语言。非侵入式沉浸式体验允许协作和延长体验,而不像要求用户佩戴耳机的系统。图 (a) 描绘了街头市场环境:人形 AI 代理扮演店主居住在上海的虚拟街头市场。两名学生正在与 AI 代理和彼此一起练习购物。图 (b) 描绘了中餐馆环境:一名学生正在练习如何点菜。她使用多模式(语音 + 手势)交互。服务器是一个化身为熊猫的 AI 代理。视频 — youtu.be/lZWtDqhFlAc . . . . . 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 24

通过恢复策略
摘要 - 离线目标条件的强化学习(GCRL)的目的是通过脱机数据集的稀疏重新解决目标解决目标任务。虽然先前的工作已经阐明了代理商学习近乎最佳策略的各种方法,但在处理复杂环境(例如安全限制)中处理各种约束时,这些方法会遇到限制。其中一些方法优先考虑目标,而无需考虑安全性,而其他方法则以牺牲培训效率为代价而过度关注安全性。在本文中,我们研究了限制离线GCRL的问题,并提出了一种称为基于恢复的监督学习(RBSL)的新方法,以完成具有各种目标的安全至关重要的任务。为了评估方法性能,我们基于具有随机定位的障碍物的机器人提取环境建立基准测试,并使用专家或随机策略来生成离线数据集。我们将RBSL与三种离线GCRL算法和一种离线安全RL算法进行比较。结果,我们的方法在很大程度上可以执行现有的最新方法。此外,我们通过将RBSL部署在真正的熊猫机械手上来验证RBSL的实用性和有效性。代码可在https://github.com/sunlighted/rbsl.git上找到。

板球数据分析
摘要:这项研究调查了现代数据分析技术在板球领域的应用,板球是一项富含数据的运动,但通常受传统分析方法的限制。使用来自ESPN CRIC-INFO的T20世界杯的数据,这项研究证明了网络刮擦,Python,Pandas和Power BI在将原始数据转换为板球战略家和爱好者的可行见解方面的功能。Bright Data的Web刮擦工具用于有效收集全面的匹配数据,然后通过Python脚本进行了转换和清洁,以确保质量和准确性。熊猫库在数据操作中起着至关重要的作用,可以在许多统计类别上进行有效的分类,分组和计算。最后,Power BI用于创建动态可视化和仪表板,为深入分析提供了交互式平台。这项研究的结果不仅强调了可以通过体育中的先进数据分析获得的关键见解,而且还强调了这些分析工具在从复杂数据集中提取有意义的解释方面的兼容性和强度。这项工作通过识别模式,预测结果并告知板球决策,从而有助于运动分析的不断增长领域。关键字:板球数据分析,网络刮擦,Python,Pandas,Power BI,T20世界杯,ESPN CRIC-INFO,数据转换,数据清洁,数据可视化,体育分析,板球决策,交互式仪表板。I.II。 板球分析与机器学习的播放器绩效预测II。板球分析与机器学习的播放器绩效预测引言随着运动的景观的不断发展,对战略决策制定的数据分析的依赖变得至关重要。板球及其大量的统计和绩效指标,是数据驱动的见解的肥沃基础。T20板球的引入进一步扩大了这一需求,因为游戏的较短格式需要基于实时数据的快速而有影响力的决策。本研究论文着重于利用先进的分析方法提取,处理和分析板球数据,目的是为T20世界杯表演提供增强的见解。这项研究的核心宗旨是当代数据分析工具和技术的凝聚力应用,以探索板球数据的无数方面。该项目展示了Web刮擦在收集板球统计领先的领先机构ESPN CRIC-INFO的广泛板球数据方面的功效。利用了Bright Data的强大网络刮擦功能,本文展示了为体育中任何分析努力构建综合数据集的第一步。随后,本文深入研究Python的出色数据转换和清洁能力,确保收集到的数据的完整性和可用性。python的多功能性和其生态系统中可用的功能强大库,尤其是熊猫,促进了复杂的数据操纵过程。pandas在简化板球数据方面起着关键作用,从而允许诸如合并,重塑和聚合数据集以准备分析等复杂的操作。相关工作是一些与板球,pandas和Power BI(或类似工具)相关的现实世界项目:1。