XiaoMi-AI文件搜索系统
World File Search System猜词

专注的创新者提供可持续的长期增长
本演讲包含前瞻性陈述,可提供我们对未来事件的期望或预测,例如新产品介绍,产品批准和财务绩效。前瞻性陈述包括但不限于任何可能预测,预测,指示或暗示未来的结果,表现或成就,并且可能包含诸如“相信”,“预期”,“期望”,“预测”,“估算”,“预测”,“计划”,“计划”,“ PLAN”,“ PROVENT”,“ PROVECT”,“将继续”,“将继续”,“将“”,“可能”的词或其他任何词相似的词,“可能”或任何词,“或其他方式”,或者,“”本演示文稿中包括的历史事实陈述以外的所有陈述,包括但不限于我们的财务状况,业务策略,计划和对未来运营的管理的计划和目标(包括开发计划和与我们的产品有关的目标),都是前瞻性陈述。

2023 年美国新兵指南 - JFC BRUNSSUM - 北约
两种护照:官方/“免费”护照仅用于出入境官方指定国家。官方/免费护照签发给根据政府命令出国旅行的军事人员和其他政府人员。家属必须持有官方/免费护照才能前往荷兰。这要求您在报告日期之前提前到您最近的美国军事基地护照办公室或基地旅行办公室申请“免费”护照。您可能已经猜到了,政府免费提供它。所有其他旅行都需要每个家庭成员(包括婴儿)持有旅游护照才能在欧洲及周边旅行,无论旅行方式如何。如果您计划在工作地点以外旅行,则需要有效的旅游护照。旅游护照不予退还。

2023 年性别平等指数 - 迈向交通和能源领域的绿色转型
( 1 ) 本报告使用 LGBTQI* 这一缩写词,因为它是最具包容性的统称,指的是性取向与异性恋规范不同且性别认同不属于二元类别的人群。用于表示这一非常异质群体的语言不断发展,以期实现更大的包容性,不同的参与者和机构采用了不同版本的缩写词(LGBT、LGBTIQ 和 LGBTI)。报告在描述其工作成果时使用了机构选择的缩写词。

2004 年 BGA 滑翔会议 - Amazon S3
担任主席。它让我有机会亲眼目睹俱乐部工厂如何发展其设施并吸引新成员。见证他们投入日常滑翔运动的热情和奉献精神,而不仅仅是比赛中的最高水平。我在肯特俱乐部最开心的事是看到一位年长的新成员——我猜他已经很强壮了——获得了俱乐部奖杯,以表彰他克服健康障碍并独自参加比赛的决心。晚宴结束后,他来找我,通过我向他表示感谢所有创造环境的人,让他有机会发现新的和高度有益的爱好。俱乐部显然对他非常尊重,这让我意识到我们争取自由是多么重要,因为这些自由可能会导致他不被允许进入俱乐部

集中创新推动可持续增长
本演讲包含前瞻性陈述,可提供我们对未来事件的期望或预测,例如新产品介绍,产品批准和财务绩效。前瞻性陈述包括但不限于任何可能预测,预测,指示或暗示未来的结果,表现或成就,并且可能包含诸如“相信”,“预期”,“期望”,“预测”,“估算”,“预测”,“计划”,“计划”,“ PLAN”,“ PROVENT”,“ PROVECT”,“将继续”,“将继续”,“将“”,“可能”的词或其他任何词相似的词,“可能”或任何词,“或其他方式”,或者,“”本演讲中包括的历史事实陈述以外的所有陈述,包括但不限于拟议收购Londbeck的Longboard Pharmaceuticals,Inc。(“ Longboard”)和Lundboard的财务状况,业务策略,计划和目标的目标(包括未来运营的计划和目标)(包括与Lundbeck和Longboard的产品有关),包括与Lundboard和Longboard的产品有关),以及均符合了款项)。

写作课中的人工智能:编辑、合著者、代笔作家还是缪斯?
国会图书馆是世界上最全面的图书馆。它通过玩一个简单的反复试验的语言游戏(猜猜从文本中随机删除的单词)来处理这些数据,以不断改进其知识库,使用 1,024 台强大的计算机每天 24 小时运行,预计耗时 34 天。结果是一个拥有 1750 亿个参数的神经网络,这是人类大脑中突触的电子模拟。随着 GPT-3 在庞大的文本语料库中经过数十亿次试验掌握猜单词任务,该系统获得了词汇、句子结构、单词内涵、世界事实、写作风格等知识。然后它可以使用这些知识来响应各种各样的请求。当然,它没有每个人通过经验和互动获得的对世界的理解,所以可以说它有知识的深度但缺乏广度。

从脑磁信号进行连续语言语义重建
从神经信号中解码语言具有重要的理论和实践意义。先前的研究表明从侵入式神经信号中解码文本或语音的可行性。然而,当使用非侵入式神经信号时,由于其质量低下,面临着巨大的挑战。在本研究中,我们提出了一种数据驱动的方法,用于从受试者听连续语音时记录的脑磁图 (MEG) 信号中解码语言语义。首先,使用对比学习训练多受试者解码模型,从 MEG 数据中重建连续词嵌入。随后,采用波束搜索算法根据重建的词嵌入生成文本序列。给定波束中的候选句子,使用语言模型来预测后续单词。后续单词的词嵌入与重建的词嵌入相关联。然后使用这些相关性作为下一个单词的概率度量。结果表明,所提出的连续词向量模型可以有效利用特定主题和共享主题的信息。此外,解码后的文本与目标文本具有显著的相似性,平均 BERTScore 为 0.816,与之前的 fMRI 研究结果相当。

黑暗中的量子视觉
原子领域中其他粒子的相互作用——却不是这样。通过量子力学和巧妙的实验设计,确实可以实现无相互作用的测量。如果珀尔修斯掌握了量子物理知识,他就能想出一种方法来“看见”美杜莎,而不需要任何光线真正照射到美杜莎身上并进入他的眼睛。他可以不看就能看。这种量子魔术为构建可在现实世界中使用的检测设备提供了许多想法。也许更有趣的是令人难以置信的哲学含义。这些应用和含义最好在思想实验的层面上理解:流线型分析包含真实实验的所有基本特征,但没有实际的复杂性。因此,作为一个思想实验,考虑一种贝壳游戏的变体,它使用两个贝壳和藏在其中一个贝壳下的一颗鹅卵石。然而,鹅卵石很特别:如果暴露在任何光线下,它就会变成尘埃。玩家尝试确定隐藏的鹅卵石的位置,但不能将其暴露在光线下或以任何方式打扰它。如果鹅卵石化为灰尘,玩家就输了。最初,这个任务似乎不可能完成,但我们很快发现,只要玩家愿意一半的时间都成功,那么一个简单的策略就是抬起他认为没有鹅卵石的贝壳。如果他猜对了,那么他就知道鹅卵石在另一个贝壳下面,即使他没有看到它。当然,用这个策略获胜只不过是碰运气猜对了。接下来,我们进一步修改,看似简化了游戏,但实际上让局限于经典物理领域的玩家不可能获胜。我们只有一个贝壳,鹅卵石可能在壳下也可能不在壳下,这是一个随机的机会。玩家的目标是判断鹅卵石是否存在,同样,不将其暴露在光线下。假设贝壳下面有一颗鹅卵石。如果玩家不看贝壳下面,那么他就不会得到任何信息。如果他看了,那么他就知道鹅卵石在那里,只是他必须把它暴露在光线下,所以只会发现一堆灰尘。玩家可以尝试调暗

JIOS Vol44 No2.indd
测量文本的语义相似度在自然语言处理领域的各种任务中起着至关重要的作用。在本文中,我们描述了一组我们进行的实验,以评估和比较用于测量短文本语义相似度的不同方法的性能。我们对四种基于词向量的模型进行了比较:Word2Vec 的两个变体(一个基于在特定数据集上训练的 Word2Vec,另一个使用词义的嵌入对其进行扩展)、FastText 和 TF-IDF。由于这些模型提供了词向量,我们尝试了各种基于词向量计算短文本语义相似度的方法。更准确地说,对于这些模型中的每一个,我们测试了五种将词向量聚合到文本嵌入中的方法。我们通过对两种常用的相似度测量进行变体引入了三种方法。一种方法是基于质心的余弦相似度的扩展,另外两种方法是 Okapi BM25 函数的变体。我们在两个公开可用的数据集 SICK 和 Lee 上根据 Pearson 和 Spearman 相关性对所有方法进行了评估。结果表明,在大多数情况下,扩展方法的表现优于原始方法。关键词:语义相似度、短文本相似度、词嵌入、Word2Vec、FastText、TF-IDF
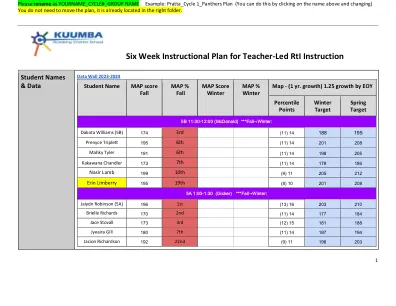
教师主导的 RtI 教学的六周教学计划
简介:文本以各种结构书写。这让读者更容易理解他们正在阅读的内容。今天,我将为您示范如何确定您正在阅读的文本结构类型。发布一张图表,其中包含六种最常见的文本结构:因果关系、问题和解决方案、问题和答案、比较和对比、描述和时间顺序,以及每种文本结构的一些提示词。这些是六种最常见的文本结构和提示词,它们将帮助您确定您正在阅读的文本结构类型。当我今天阅读文本时,我将大声思考文本可能具有哪种类型的结构。学生练习:给一个小组六段短文和六张索引卡。每张索引卡都应包含与文本结构相匹配的提示词列表。让学生一起阅读每段文本,并使用提示词卡作为指南确定其结构。然后让学生自己完成文本结构图形组织器。