XiaoMi-AI文件搜索系统
World File Search System用具


2018 年肯塔基州建筑规范
101.4.1 燃气。NFPA 54《国家燃气规范》的规定应适用于从输送点开始的燃气管道安装、燃气用具和本规范所涵盖的相关配件。这些要求适用于从输送点延伸到设备入口连接的燃气管道系统以及住宅和商业燃气用具及相关配件的安装和操作。101.4.2 机械。国际机械规范的规定应适用于机械系统的安装、改造、维修和更换,包括设备、器具、固定装置、配件和/或附属物,包括通风、供暖、制冷、空调和制冷系统、焚化炉和其他能源相关系统。

屠宰场肉类卫生安全处理指南
动物粪便、肠道内容物和皮肤(在屠宰场,细菌经常从肠道转移到肉上) 人(粪便、嘴、鼻子、手、指甲、皮肤)(如果不经常洗手,就会把细菌转移到肉上) 土壤和水 老鼠、昆虫和害虫 食物制备表面和用具/设备
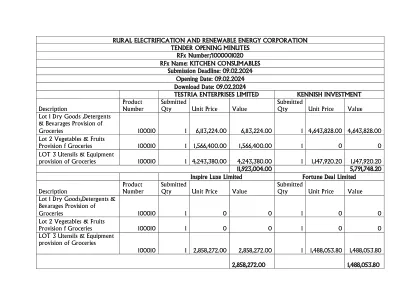
开幕式 RFX 1020 厨房......
提交数量 单价 价值 第 1 批 干货、洗涤剂及饮料 供应杂货 100010 1 6,113,224.00 6,113,224.00 1 4,643,828.00 4,643,828.00 第 2 批 蔬菜及水果 供应杂货 100010 1 1,566,400.00 1,566,400.00 1 0 0 第 3 批 用具及设备 供应杂货 100010 1 4,243,380.00 4,243,380.00 1 1,147,920.20 1,147,920.20 11,923,004.00 5,791,748.20 Inspire Luxe Limited 财富交易有限公司



可再生氢和最终用户的考虑,以期过渡到可再生气网(卫生)
燃气装置的氢混合水平的接受程度不同。某些设备需要使用客户设备来使用氢气,而另一些设备则不使用氢。通过标准实践项目,建立诸如WOBBE指数之类的工作限制以及确保材料兼容性和安全的氢浓度确定氢气的允许极限。尽管天然气管道可以运输更高浓度的氢气,包括高达100%,但预计分销网络的允许水平将被限制为20%,以适应现有的客户气体用具。

Modex 2024展位A11918
关于LG业务解决方案美国LG Electronics USA Business Solutions Divisions为美国住宿和酒店的商业客户提供服务,数字标牌,系统集成,医疗保健,教育,政府和工业市场 - 尖端的商业展示,机器人和电动汽车充电站。LG Business Solutions USA 设在伊利诺伊州林肯郡,其专门的工程和客户支持团队,美国提供了针对商业环境特定需求的业务对企业技术解决方案。 N.J. Englewood Cliffs的年度LG Electronics USA Inc.的十次EnergyStar®合作伙伴是LG Electronics Inc.的北美子公司,LG Electronics Inc.是600亿美元以上的全球消费电子产品,家庭用具,空中解决方案和车辆组件的全球范围。 有关更多信息,请访问www.lgsolutions.com。设在伊利诺伊州林肯郡,其专门的工程和客户支持团队,美国提供了针对商业环境特定需求的业务对企业技术解决方案。N.J. Englewood Cliffs的年度LG Electronics USA Inc.的十次EnergyStar®合作伙伴是LG Electronics Inc.的北美子公司,LG Electronics Inc.是600亿美元以上的全球消费电子产品,家庭用具,空中解决方案和车辆组件的全球范围。有关更多信息,请访问www.lgsolutions.com。

明尼苏达州地方法院蓝地球县第五司法区
车辆被证实被盗。瓦格纳警官在将车辆交给拖车公司之前对其进行了搜查。在车内,瓦格纳警官发现了一条香烟、麻醉用具、一个装有白色岩石物质的小透明塑料袋、一张装有白色粉末物质的一美元钞票以及一个装有三粒疑似芬太尼药丸的小透明塑料袋。岩石物质经现场检测呈可卡因阳性,重量为 2.5 克,白色粉末物质经现场检测呈可卡因阳性,重量为 1.07 克。