XiaoMi-AI文件搜索系统
World File Search System百万

词典:对数百万...
与基因组数据库的一致性是生物信息学的基本操作,被BLAST推广了12。但是,测序的微生物基因组的速率持续增加,现在有13个数据集,现在数百万的数据集远远超出了现有的对齐工具的能力。我们14引入了词典,这是一种核苷酸序列比对工具,用于有效查询中度长度15个序列(> 500 bp),例如基因,质粒或长期读取数百万个原核生物16基因组。关键创新是构造一小部分探针K -Mers(例如n = 40,000)17“窗口覆盖”整个数据库的索引,从某种意义上说,每18个数据库基因组的每500 bp窗口都包含多个种子k -mers,每个k -mers每个都带有一个带有一个探针的共享前缀。19存储这些种子,并由他们同意的探针索引,在层次索引中可以实现20个快速和低内存可变长度匹配,伪有序,然后完全对齐。我们21表明,词典比BlastN能够与更高的灵敏度保持一致,因为查询≥1kb的查询差异从90%降至80%,然后在Small(GTDB)和大23(Allthebacteria和GenBank+GenBank+Repeq)数据库上基准基准。我们表明,与最先进的方法相比,词典词法可以达到更高的24个灵敏度,速度和较低的记忆。对25个基因的比对与来自Genbank和Refseq的234万个原核生物基因组的比对需要36秒26(稀有基因)至15分钟(16S rRNA基因)。词典MAP以标准格式27产生输出,其中包括BLAST的输出,可在MIT许可证28 https://github.com/shenwei356/lexicmap上获得。29 div>

nist 预算(百万美元)
安全、容量、维护和重大维修——7500 万美元 • 4000 万美元 – 固定劳动力成本和合同 • 2400 万美元 – 公用事业基础设施维修 • 100 万美元 – 继续多年屋顶更换 • 300 万美元 – IT 基础设施升级 • 700 万美元 – 其他维修和更换项目

COTS 坚固耐用百万像素摄像机 - Alacron
图像控制和处理 RA1000 系列相机可通过其行业标准 Camera Link 接口与流行的现成图像采集卡板进行连接。通过 Adimec 与知名成像设备供应商的合作,还可以实现其他接口选项。Adimec 能够提供额外的相机功能,并为大批量项目创建客户专用相机。如需更多信息,请联系您最近的 Adimec 办事处。
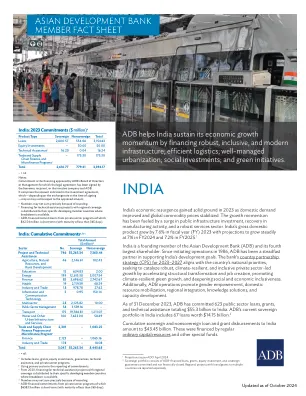
印度:2023 年承诺额(百万美元)a
运营挑战。印度各邦的规模、发展需求和优先事项以及财政状况各不相同,这对亚行的运营构成了重大挑战,亚行必须调整其项目以满足当地需求和客户的高期望。各邦的需求和借贷空间是渠道建设的重要考虑因素。确保进入时做好充分准备并保证质量对于实现良好的实施绩效至关重要。随着亚行转向复杂的多学科项目并增加私营部门的参与,由于机构能力薄弱以及执行机构在实施此类新、复杂和创新项目方面经验有限,运营挑战是可以预见的。

巴基斯坦:2023 年承诺额(百万美元)a
亚行将为巴基斯坦制定 2026-2030 年国家伙伴关系战略,该战略将确定主要挑战和发展要求,支持政府实施关键结构性改革,并通过一系列公私合作项目和私营部门发展增强经济韧性。未来的项目预计将侧重于减轻气候变化的影响、投资社会部门和发展气候智能型经济基础设施。亚行还将探索利用数字技术促进包容性增长、扩大机遇和改善政府服务。亚行对私营部门的投资将继续帮助企业释放投资机会、建立创业文化并为可持续发展做出贡献。亚行的知识工作将继续包括政策咨询、提供相关知识产品以及促进其他亚行成员国的经验转移。

菲律宾:2023 年承诺额(百万美元)a
亚行提供知识支持,以加强该国的经济复苏。亚行的技术援助将侧重于增长走廊和城市发展规划、农村发展和粮食安全、卫生服务提供、改善地方治理、就业恢复和技能提升等方面的气候适应性举措。亚行与世界粮食计划署合作,进行了一项研究,探讨以食品券形式进行现金转移的潜力,以帮助减少菲律宾的粮食不安全和营养不良。该研究肯定了社会保护计划的必要性,以支持弱势家庭的粮食和营养需求。这成为 2023 年试点数字食品券计划的基础,该计划名为 Walang Gutom(零饥饿)2027:食品券计划,政府于 2023 年 10 月将其作为旗舰计划采用。

不丹:2023 年承诺金额(百万美元)a
运营挑战。不丹是一个丘陵密布的内陆小国,经济基础薄弱。水电项目和旅游业历来是该国经济的主要推动力。亚行项目工地分散在全国各地,连通性差限制了进入这些工地。不丹市场规模小,供应商、承包商和技术工人有限,这增加了项目实施的复杂性。为了解决亚行对口机构人员频繁变动的问题,亚行正与政府密切合作,以提高国家和地方机构及工作人员的实施能力。亚行继续对实施和执行机构的工作人员进行采购流程、保障措施、财务管理和结果管理方面的培训。

容错百万量子比特级分布式量子计算机
百万量子比特级量子计算机对于实现量子霸权至关重要。现代大型量子计算机集成了位于稀释制冷机 (DR) 中的多台量子计算机,以克服每个 DR 的不可扩展冷却预算。然而,大型多 DR 量子计算机带来了其独特的挑战(即缓慢且错误的 DR 间纠缠、量子比特规模增加),并且它们通过增加门操作的数量和 DR 间通信延迟来解码和纠正错误,从而使基线错误处理机制无效。如果不解决这些挑战,就不可能实现容错的大型多 DR 量子计算机。在本文中,我们提出了一种百万量子比特级分布式量子计算机,它使用一种新颖的错误处理机制来实现容错的多 DR 量子计算。首先,我们应用低开销的多 DR 错误综合征测量 (ESM) 序列来减少门操作的数量和错误率。其次,我们应用可扩展的多 DR 错误解码单元 (EDU) 架构来
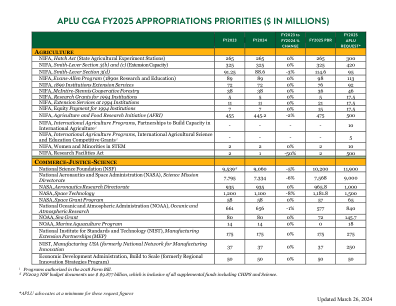
APLU CGA 2025 财年拨款重点(百万美元)
APLU 请求 * A 农业 NIFA,哈奇法案 (州农业实验站) 265 265 0% 265 300 NIFA,史密斯-利弗法案第 3(b) 和 (c) 节 (推广能力) 325 325 0% 325 420 NIFA,史密斯-利弗法案第 3(d) 节 91.25 88.6 -3% 114.6 95 NIFA,埃文斯-艾伦计划 (1890 年代研究和教育) 89 89 0% 98 113 NIFA,1890 年机构推广服务 72 72 0% 76 92 NIFA,麦金蒂尔-斯坦尼斯合作林业 38 38 0% 36 46 NIFA,1994 年机构研究补助金 5 5 0% 5 17.5 NIFA,1994 年机构的推广服务 11 11 0% 21 17.5 NIFA,1994 年机构的股权支付 7 7 0% 15 17.5 NIFA,农业和食品研究计划(AFRI) 455 445.2 -2% 475 500 NIFA,国际农业计划,国际农业能力建设伙伴关系 i - - - - 10

用于检测 AI 生成图像的百万级基准
生成模型生成摄影图像的非凡能力加剧了人们对虚假信息传播的担忧,从而导致对能够区分人工智能生成的假图像和真实图像的检测器的需求。然而,缺乏包含来自最先进图像生成器的图像的大型数据集,这对此类检测器的开发构成了障碍。在本文中,我们介绍了 GenImage 数据集,它具有以下优点:1)图像丰富,包括超过一百万对人工智能生成的假图像和收集的真实图像。2)图像内容丰富,涵盖广泛的图像类别。3)最先进的生成器,使用先进的扩散模型和 GAN 合成图像。上述优势使在 GenImage 上训练的检测器经过彻底的评估,并表现出对各种图像的强大适用性。我们对数据集进行了全面分析,并提出了两个任务来评估检测方法在模拟真实场景中的表现。跨生成器图像分类任务衡量了在一个生成器上训练的检测器在其他生成器上测试时的性能。降级图像分类任务评估了检测器处理降级图像(例如低分辨率、模糊和压缩图像)的能力。借助 GenImage 数据集,与现行方法相比,研究人员可以有效地加快开发和评估更优秀的 AI 生成图像检测器。