XiaoMi-AI文件搜索系统
World File Search System盐叶


盐河项目农业改善...
公众应在参加会议或向董事会讲话时避免发表任何不适当的评论。也禁止听众的颠覆性活动,大声,鼓掌,脚踩脚或任何类似的示威游行(包括任何标牌)。违反此规则可能导致会议撤离。根据A.R.S.§38-431.03(a)(3),目的是与法律顾问讨论或咨询法律顾问,就议程上列出的任何事项。根据A.R.S.§30-805(b),以讨论与竞争活动有关的记录和诉讼,包括商业秘密或特权或机密商业或财务信息。访问者:公众可以选择通过Zoom进行面对面或观察,并可以通过(602)236-4398与公司秘书办公室联系,从而获得电话会议信息。如果参加面对面的所有财产,包括钱包,公文包,包裹,

消息传递基于贝叶斯的贝叶斯对推车系统的控制
摘要。我们描述了一个贝叶斯控制器的贝叶斯控制器,这是控制理论中众所周知的基准。卡车孔系统的特征是其非线性和不足的性质,我们通过(1)假设控制器缺乏传感器噪声方差的知识,并且(2)在控制信号上施加界限。传统的控制算法通常难以适应不确定性和约束。然而,贝叶斯框架,尤其是专用推理框架,可以顺利地适应这些复杂性。在拟议的控制器中,整个计算过程由在线贝叶斯推理组成。通过工具箱简化了此过程,以在因子图中快速传递基于消息传递的推断。我们描述了在因子图中传递消息的机制,解决了诸如非线性因素,有限控制和实时参数跟踪之类的挑战。本文的主要目的是证明,随着主动推理框架的发展和自动推理工具箱的效率,贝叶斯控制成为应用程序工程师的吸引人选择。

检测棕榈油叶病
摘要这项研究调查了机器学习技术在检测油棕叶中疾病的应用,并利用来自Tanah Laut地区种植园的1,119张图像的数据集。数据集包含488例患病和631个健康的叶片样品,这些样品经过精心裁剪以隔离叶片区域,并在域专家的帮助下标记。用于特征提取,同时考虑了实验室和RGB颜色空间,以及Haralick纹理特征,每个像素总共有11个功能。采用了尺寸和选择相关特征,应用主成分分析(PCA)和随机森林方法。随后使用支持向量机(SVM)进行叶片健康状况的分类,并使用准确性,精度,召回和F1得分指标评估模型性能,这些均来自混淆矩阵。研究发现,PCA和随机森林显着提高了模型性能,从而提高了区分健康和患病叶片的能力。这些发现为在油棕种植园中开发自动疾病检测系统的发展提供了宝贵的见解,并在精确农业中使用了潜在的应用。此外,结果提出了进一步研究植物疾病诊断的途径,强调了先进的机器学习技术在增强作物管理和支持可持续农业实践中的作用。
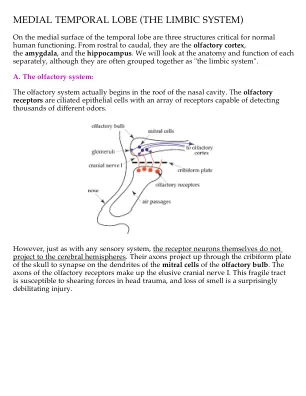
内侧颞叶(边缘系统)
一位名叫 HM 的著名患者让海马体的重要性得到了深刻的体现。作为癫痫手术的一部分,医生切除了他大部分的内侧颞叶。自 1953 年那次手术以来,他没有形成任何新的记忆。他能记得童年和手术前的一切,他仍然有工作记忆和形成程序记忆的能力。你可以和他进行正常、清晰的对话,但如果你离开房间片刻,当你回来时,他不会记得你或对话。他完全失去了形成陈述性记忆的能力。

使用Chrysomelidae(叶甲虫)
结果:数据库包括73342个条形码,分为来自101个国家 /地区的5310个垃圾箱(物种代理)。哥斯达黎加贡献了所有条形码序列的近一半,而将近50个国家 /地区的条形码少于十个。只有五个国家,哥斯达黎加,加拿大,南非,德国和西班牙,尽管条形码数据库涵盖了大多数主要的分类学和生物地理位置上的谱系,但采样了很高的完整性。pd显示出中度饱和度,因为一个国家添加了更多的物种多样性,并且社区系统发育表明国家动物群的聚类。然而,在物种层面,即使在最激烈的采样国家中,库存仍然不完整,并且对全球物种丰富度模式的评估不足。



全球NIP更新网络研讨会1国家的基础知识...
1。POPS农药的清单2。五氯苯酚,其盐和酯(PCP)的清单3。多氯联苯(PCB)的库存4。多溴二苯基醚的清单(POP-PBDES) - HBB,C-OCTABDE和C-PENTABDE 5。六焦叶氯二烷(HBCD)的清单6。decabromodiphenyl醚(C-DECA-BDE)的清单7。Hexachlorobutadiene(HCBD)的清单8。多氯联苯(PCNS)的库存9.短链氯化石蜡(SCCPS)10。双胃植物11.浓度含量(PFOA),其盐和PFOA相关的化合物12. pluluorohehexane sulfonicac和Pfhxs和Pfhxs和Pfhx-reftory的盐和PFOA相关化合物12. 14.全氟辛烷磺酸,其盐和全氟辛烷磺酰氟化物

贝叶斯人工智能
在我们的理解中,贝叶斯人工智能是将贝叶斯推理方法融入人工智能 (AI) 软件架构的开发中。我们认为,这种架构的重要组成部分将是贝叶斯网络和通过观察和实验进行的贝叶斯网络贝叶斯学习 (贝叶斯因果发现)。在本书中,我们介绍了贝叶斯网络技术的要素、自动因果发现、从数据中学习概率,以及如何在开发概率专家系统中使用这些技术的示例和想法,我们称之为使用贝叶斯网络的知识工程。这是一个非常实用的项目,因为使用贝叶斯网络进行数据挖掘 (应用因果发现) 以及在工业和政府中部署贝叶斯网络是当今应用人工智能最有前途的两个领域。但这也是一项非常理论化的项目,因为贝叶斯人工智能的成就将是一项重大的理论成就。我们的标题中有许多我们可以自然而然地包括但尚未包括的主题。因此,有效贝叶斯人工智能的另一个必要方面是概念的学习以及概念的层次结构。存在用于概念形成的贝叶斯方法(例如,Chris Wallace 的 Snob [290]),但我们在此不讨论它们。我们还可以讨论贝叶斯分类方法、多项式曲线拟合、时间序列建模等。我们选择贴近使用和发现贝叶斯网络的主题,因为这是我们自己的主要研究领域,而且尽管其他贝叶斯学习方法很重要,但我们认为贝叶斯网络技术是整个项目的核心。我们的文本在许多方面与其他关于贝叶斯网络的文本不同。我们的目标是对该技术的主要概念进行实用且易于理解的介绍,同时关注基础问题。该领域的大多数文本需要比我们更多的数学复杂性;我们假设只对代数和微积分有基本的了解。此外,我们对网络的因果发现和使用已发现网络的贝叶斯推理程序给予大致相同的重视。大多数文本要么忽略因果发现,要么轻描淡写。Richard Neapolitan 的最新著作《学习贝叶斯网络》[200] 是个例外,但它在技术上比我们的要求更高。我们还根据我们自己的应用研究,详细阐述了该技术的各种应用。我们文本的另一个显著特点是,我们提倡对贝叶斯网络进行因果解释,并讨论使用贝叶斯网络进行因果建模。我们希望这些例子会引起人们的兴趣,并指出一些可能性