XiaoMi-AI文件搜索系统
World File Search System监督的

使用无监督的
摘要:阿尔茨海默氏病(AD)是一种进行性脑部疾病,是一种非常常见的痴呆症形式。神经影像学技术,例如磁共振成像(MRI),可产生大脑的详细3维图像,显示淀粉样蛋白沉积物的见解和作为疾病标志物的炎症改变。使用MRI的AD早期诊断为患者提供了一个很好的机会,可以通过阻止神经细胞的丧失来防止脑部恶化。本文探讨了无监督的聚类方法的使用来早期诊断AD。尽管使用分类技术来识别医疗疾病非常常见,但标记数据的缺乏或不准确性可能会产生问题。在这项工作中,使用基于体素的形态计量学(VBM)特征在MRI图像中提取的特征进行比较。还将选择某些兴趣的某些地方区域(ROI)与全球全脑分析进行了比较。结果表明,所提出的方法可以以76%的精度对AD进行早期诊断。关键词:无监督的学习,聚类,K-均值,K-米类动物,感兴趣的区域(ROI),阿尔茨海默氏病,磁共振成像(MRI)。1。介绍2018年,据报道,全世界有五千万人患有痴呆症。到2050年,这个数字预计将达到1.52亿人[1]。大约有68%的增加,据信属于埃及等低收入和中等收入国家[2]。阿尔茨海默氏病(AD)是一种进行性脑部疾病

监督与无监督的学习
●Breiman(2001)首先提出了随机森林算法,但基于1995年的Tim Kan Ho●RF采用了两种集合技术:首先是训练样本,以种植基于不同培训训练数据的树木森林。第二个是特征空间的子采样。●如果我选择变量的子集(例如x1, x3, x7) to create a split in a node of a decision tree, and another subset (x2, x4, x5, x7) to create a different one, there will be events that get classified in a different way by the two nodes ● Often there is a dominant variables that is used to decide the split, offsetting the power of the subdominant ones.rf通过减少不同树的相关性来避免该问题
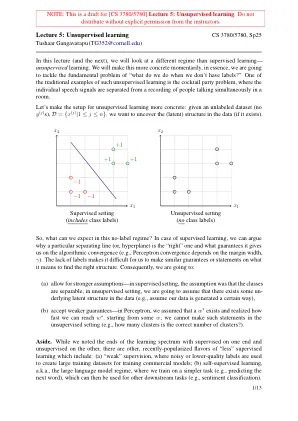
讲座5:无监督的学习
p(a | b;α)给定b的概率,由α参数化。注意:α是模型的参数,而不是随机变量x〜Bernoulli(p)x是带有参数p的Bernoulli随机变量。思考:x表示硬币折腾的结果,p(h)= p x〜多项式(φ)x是一个多项式随机变量,具有参数φ和n = 1-这是Bernoulli随机变量的概括。思考:x表示滚动骰子的结果,p(side-i)= p(i); φ= {p(1),。。。,p(6)} z一个随机变量,以指示滚动k flace die的结果(k = 2:bernoulli;多项式;否则)p(z(j)= i)从高斯i绘制数据点的概率。这更多是一种信念或先验,并且独立于数据。思考:上帝将其设置为先验p(z(j)= i | x(j))X(j)点是从高斯 - i生成的概率,因为我们观察到x(j)。将其视为:我们观察到x(j),现在是从高斯i绘制的吗?p(x(j)| z(j)= i)观察x(j)的概率,因为我们正在从z(j)= i生成数据;在本讲座中,我们假设x(j)| z(j)= i〜n(µ(i),σ(i))θθ一组模型参数;如果k = 2,θ= {µ(1),µ(2),σ(1),σ(2),p}

使用监督的机器学习和
630612,印度泰米尔纳德邦1 yoheswari1988@gmail.com摘要:社交媒体的兴起为沟通和互动创建了一个新的平台,但它也促进了诸如网络欺凌之类的有害行为的传播。在社交媒体平台上检测和缓解网络欺凌是需要先进技术解决方案的关键挑战。本文使用监督机器学习(ML)和自然语言处理(NLP)技术的组合提出了一种新的网络欺凌检测方法,并通过优化算法增强了。拟议的系统旨在实时识别和分类网络欺凌行为,从社交媒体帖子中分析文本数据以检测有害内容。使用有监督的ML算法(例如支持向量机(SVM),决策树和随机森林),该模型在大型标记的欺凌和非欺凌内容的实例上进行了训练。NLP技术,包括情感分析,关键字提取和文本矢量化,用于预处理和将数据转换为适合机器学习的格式。为了优化检测模型的性能,使用网格搜索,遗传算法和粒子群优化等技术可用于微调超参数,从而提高准确性和降低的假阳性。通过在各种社交媒体平台上进行的实验来验证系统的有效性,证明了其高精度检测网络欺凌的潜力。未来的工作将着重于增强模型对社交媒体中新兴语和不断发展的语言模式的适应性。

设计与监督的咨询服务
The main objective of the consulting services is (a) preparation of architectural design, (b) preparation of detailed structural design, (c) preparation of electro-mechanical designs, (d) preparation of sanitary and plumbing designs (e) preparation of specifications, estimate and bill of quantities, preparation of environmental and social assessments and all necessary safeguards documents, (e) contract management & construction supervisor along with supply installation of goods, (f)调查和土壤测试,(g)执行环境和社会承诺计划(ESCP),利益相关者参与计划(SEP),环境和社会管理框架的合规性; (h)准备社会(ESMF),安置政策框架(RPF),劳动管理程序(LMP)以及性别和海上/SH行动计划,以及(与相关ESSS不一致。; (c) preparation of Social and environmental plans as required based on the screening outcomes and plans required according to ESCP (d) Establish and operate a grievance mechanism for Project workers, as described in the LMP and SEP and (e) Project mana8ement support to ensure completion of proiect activities within the stipulated construction period and in conformity with the approved drawings and specifications, safeguard standards achieving objectives of the proiect with value for money.3。详细的咨询服务范围

博士候选人 9——无监督的不确定性......
• 被选中的候选人将在 Helmholtz Munich 工作 36 个月,负责 MSCA-DN 项目。 • 根据 MSCA 津贴和接收机构的规定,博士候选人将获得有竞争力的薪酬。 Helmholtz Munich 已获得以下欧盟补助金来招募博士候选人 (DC):每月生活津贴 3,342 欧元;每月流动津贴 600 欧元;每月家庭津贴 660 欧元(仅在适用时)。请注意,最终的月薪总额将从上述金额中扣除所有由雇主承担的强制性国家劳动税(社会保障等)。此外,还提供资金用于技术和个人技能培训以及参与国际研究活动。 • 预计开始日期:2025 年 4 月至 9 月之间。我们鼓励届时毕业的最后一年硕士生申请。有关 IQ-BRAIN 职位的一般信息文件中提供了更多信息。

监督的肺动脉高压运动康复
1英国格拉斯哥大学医学,兽医与生命科学学院; 2英国格拉斯哥大学医学,兽医与生命科学学院卫生与福祉学院; 3英国邓迪大学分子和临床医学; 4英国伦敦大学伦敦大学学院健康信息学研究所; 5英国伦敦国王学院医院; 6英国埃克塞特市皇家德文郡和埃克塞特医疗基金会信托基金会心脏病学系; 7澳大利亚新南威尔士州悉尼心脏研究所; 8英国埃克塞特市埃克塞特大学医学院卫生与生命科学学院卫生与社区科学系卫生与社区科学系初级保健研究小组; 9英国考文垂沃里克大学沃里克医学院卫生科学系; 1 0英国莱斯特莱斯特大学呼吸科学系; 11 MRC/CSO社会和公共卫生科学部门,罗伯逊生物统计学中心,卫生与福利研究所,格拉斯哥大学,英国格拉斯哥大学;和1 2心理学系,卫生科学学院,国家公共卫生研究所,南丹麦大学,丹麦,丹麦

第9节 - 自我监督的学习
自我监督学习是机器学习领域的新兴范式,尤其是深度学习,它专注于通过利用其固有结构来学习有用的数据。自我监督学习的主要目标是使学习过程能够通过使用输入数据本身作为监督的一种形式,而无需依靠大量标记的数据,而无需依靠大量标记的数据。

无监督的机器学习算法的类型
无监督的学习是一种机器学习方法,它处理了未标记的数据,与监督学习不同的是在其中标记了特定类别或结果的数据。无监督的学习算法在数据中找到模式和关系,而没有事先了解其含义,从而自行发现隐藏的群体和模式。该算法没有预定义的标签或类别,因此它必须使用诸如聚类,降低性降低或异常检测等技术基于固有模式来弄清楚如何根据固有模式进行分组或组织数据。此过程可以揭示从标记的数据集中显而易见的数据中的见解。例如,购物中心可以根据购买行为等参数将无监督的学习用于分组客户。该算法的输入包括可能包含嘈杂数据,缺失值或未知数据的非结构化数据。有三种用于无监督数据集的算法的主要类型:聚类,关联规则学习和降低维度。聚类是一种基于它们的相似性,用于无监督的机器学习中,将未标记的数据分组为群集。聚类的目的是在数据中识别数据中的模式和关系,而无需先验其含义。这些算法用于将原始的,未分类的数据对象处理为基团,例如根据其物种将大象,骆驼和母牛等动物分组。给定的文本是关于聚类算法,关联规则学习,降低维度,无监督学习的挑战以及无监督学习的应用。2。3。无监督的机器学习算法在没有预定义标签或类别的数据中识别数据中的模式和分组。应用程序包括欺诈检测,网络安全,设备预防,建议系统,图像和文本聚类,社交网络分析,天文学和气候科学。无监督学习的类型包括:1。聚类:分组相似的数据点。降低尺寸:在保留信息的同时降低功能。异常检测:识别偏差模式或异常值。4。建议系统:根据用户行为建议产品。无监督学习的挑战包括缺乏标记的数据,这可能会使评估变得困难,并且对数据质量的敏感性,这可能会影响算法性能。无监督的学习用于NLP任务,例如主题建模,文档群集和言论部分标记。它不同于监督学习,算法学会根据标记的培训数据将输入数据映射到所需的输出值。前8个无监督的机器学习算法是:[插入算法列表]此博客文章旨在帮助用户确定哪种算法最适合其解决问题的需求。k-means聚类,PCA,自动编码器和DBN算法用于无监督的机器学习:比较分析机器学习算法在数据分析中起着至关重要的作用,而无监督的学习是该领域的重要方面。我们将提供一个简短的概述,示例和详细信息,以了解哪些算法更适合特定类型的数据集。在本文中,我们将探讨四种流行的无监督机器学习算法:K-均值聚类,主成分分析(PCA),自动编码器和深度信念网络(DBN)。k-means聚类是用于数据分割的最流行的无监督的机器学习算法之一。它通过将数据集分区为K群集来工作,在K群集中,每个群集的均值是从训练数据中计算出来的。通常通过实验确定簇k的数量。k-均值聚类由于其易于理解和实施而具有优势,并且缺乏对数据基础分布的假设。但是,它可以对初始化值敏感,而不是对大数据集的可扩展性,并且与分类数据无法很好地工作。PCA算法用于降低维度,通常与K-均值聚类结合使用。它找到了一个较低维的空间,其中包含原始数据集中的大多数变化,可以通过降低维度而不会丢失太多信息来帮助使用高维数据集。PCA可以提高许多机器学习算法的性能,因为它们通常对维度敏感。但是,它在计算上可能很昂贵,并且可能不会总是降低维度的情况而不会丢失信息。自动编码器算法是一种用于无监督学习的神经网络。它通过获取输入数据集并将其编码为隐藏层,然后将编码数据与原始输入数据集进行解码和比较。它也无法与分类数据合作。如果两组之间有很高的相似性,则编码器已正确完成了其作业。自动编码器可以在数据中学习复杂的模式,但是如果编码器和解码器不够相似,则可能在计算上昂贵。深度信念网络(DBN)算法是一种用于无监督学习的深度学习算法。它创建了一个层的层次结构,其中每个层由多个神经元组成,从连接到原始数据集的输入层开始,并以产生最终输出的神经元组成的输出层结束。dbn可以学习数据中的复杂模式,但需要广泛的培训数据和计算资源。dbns根据所需的监督学习类型用于分类或回归。他们的快速训练时间是一个重要的优势,因为它们仅在输入到输出层的一个方向上训练。只要存在某些功能信息,它们也可以在有限的标记数据中表现良好。但是,DBN具有限制,例如大量的培训数据和需要大量的计算能力进行培训。此外,他们在分类数据上挣扎。卷积神经网络(CNN)是无监督和监督学习问题的流行选择,因为它们在数据集之间学习复杂的关系的能力。它们是通过将输入图像拆分到小窗口中的,然后将其通过多个执行卷积操作的神经元的层。此过程使CNN能够产生准确的预测,并且只能使用反向传播来快速训练。支持向量机(SVM)是用于无监督和监督学习问题的另一种机器学习算法。它们通过在高维空间中构建超平面而起作用,其中所有训练数据点位于一侧,目标是找到最佳的超平面,以对所有培训数据点进行分类。CNN和SVM都提供了诸如低维输入空间和快速培训时间之类的优点。但是,它们也有缺点,包括对大型数据集的高计算要求以及处理分类数据的局限性。对于有兴趣进一步探索这些算法的人,下面提供了Python代码参考。如果您对其他流行的AI和数据科学主题有建议,请随时让我们知道!

整合有监督的提取和生成的...
我们提出了一种整合监督的提取性和生成语言模型,以在Clpsych 2024共享任务中提供自杀风险的证据。我们的方法包括三个步骤。最初,我们构建了一个基于BERT的模型,用于估计句子级别的自杀风险和负面情绪。接下来,我们通过强调自杀风险和负面情绪的概率提高,精确地确定了高自杀的风险刑罚。最后,我们使用Mentallama框架和从确定的高自杀风险刑罚和自杀风险词的专业词典中进行了生成摘要。Sophiaads,我们的团队,以召回和一致性指标分别获得了突出提取的第一名,并分别以摘要生成排名第十。