XiaoMi-AI文件搜索系统
World File Search System符号

纸符号(将纸张的独特符号放在这里)
focation =𝑎𝑣𝑒𝑟𝑎𝑔𝑒𝑎𝑣𝑒𝑟𝑎𝑔𝑒𝑎𝑡𝑎𝑡𝐶𝑎𝑡𝑎𝑡7/𝑇7/𝐿3𝑎𝑣𝑒𝑟𝑎𝑔𝑒/𝑇ℎ𝑜𝑟𝑎𝑐𝑖𝑐/𝑇ℎ𝑜𝑟𝑎𝑐𝑖𝑐/𝑇ℎ𝑜𝑟𝑎𝑐𝑖𝑐/𝐿𝑢𝑚𝑏𝑎𝑟/𝐿𝑢𝑚𝑏𝑎𝑟×𝑐𝑜𝑟𝑑×100%(2)

符号和缩写
A 或 ˚ A 埃单位 5 10 2 10 米;3.937 3 10 2 11 英寸 A 质量数 5 N 1 Z;安培 AA 算术平均值 AAA 美国汽车协会 AAMA 美国汽车制造商协会 AAR 美国铁道协会 AAS 美国宇航协会 ABAI 美国锅炉及附属工业 abs 绝对 ac 空气动力中心 ac,ac 交流电 ACI 美国混凝土协会 ACM 计算机协会 ACRMA 空调和制冷制造商协会 ACS 美国化学协会 ACSR 铝电缆钢筋 ACV 气垫车 AD anno Domini(公元 1855 年) AEC 美国原子能委员会 af,af 音频频率 AFBMA 抗摩擦轴承制造商协会 AFS 美国铸造工人协会 AGA 美国燃气协会 AGMA 美国齿轮制造商协会 ahp 空气马力 AlChE 美国化学工程师协会 AIEE 美国电气工程师协会(参见 IEEE) AIME 美国采矿工程师协会 AIP 美国物理学会 AISC 美国钢结构协会 AISE 美国钢铁工程师 AISI 美国钢铁协会 am ante meridiem(中午之前) am, am 调幅 Am. Mach. 美国机械师(纽约) AMA 声学材料协会 AMCA 空气移动与调节协会 amu 原子质量单位 AN 硝酸铵(爆炸物);陆军-海军规范 AN-FO 硝酸铵燃料油(爆炸物) ANC 陆军-海军民用航空委员会 ANS 美国核能协会
缩写和符号
要求分开投票会员:§17第一部分“强调,基于性别,性别,性别,性取向,年龄,宗教或信仰,种族或种族或种族或种族渊源以及运动自由的水平原则,基于性别平等,反歧视,反歧视,应与ESF+;';'第二部分“强调在整个发展,对基金的实施,监视和评估中相交方法的重要性;”第21条第一部分“强调ESF+应该投资于针对妇女就业的项目以及妇女的社会和经济包容,并特别关注单身母亲和女性领导的家庭;坚持认为,ESF+支持处于脆弱情况的妇女,需要额外的支持以(重新)整合到社会和劳动力市场中,包括妇女,这些妇女是基于性别的暴力的受害者,包括经济暴力;”第二部分“要求沿ESF+进行横切性别方法;” §33第一部分文本整体上没有任何话:‘对于截断和远程连接规则的权利指令,关于工作场所的AI指令以及关于工作中的心理风险和福祉的指令,以及在工作中的福祉,以及增加资金的资金,以及第二部分的第二部分§41第41条第41条第41条第一部分文字,无效,以进一步的有效性,以便更有效地进行规则,以便更有效地进行规则;第二部分
符号与亚符号 AI 方法:朋友还是敌人?
符号和亚符号代表人工智能 (AI) 的两个主要分支。人工智能领域在 20 世纪 50 年代取得了巨大进步并确立了地位,在此之前,McCulloch 和 Pittes 做出了一些最著名和开创性的工作,他们在 1943 年建立了神经网络 (NN) 的基础,而 Turing 的工作则在 20 世纪 50 年代引入了机器智能测试,即图灵测试。自发明以来,该领域的发展经历了起起伏伏,俗称人工智能季节,其特点是“夏季”和“冬季”。这些起伏的具体时期尚不清楚,但是,我们根据维基百科和 Henry Kautz 在 AAAI 2020 上的演讲 1“第三个 AI 夏天”采用了中间惯例。我们在图 1 中展示了这些发展的时间表。第一个 AI 夏天,也称为黄金时代,始于 AI 诞生几年后,它基于对解决问题和推理的乐观态度。直到 20 世纪 80 年代,主导范式都是符号 AI。这时,亚符号 AI 开始占据主导地位并受到关注,直到最近几年。两种不同方法之间存在长期而未解决的争论。然而,不同人工智能领域之间的这场较量即将结束,因为我们目前正在经历第三次人工智能之夏,其中主导浪潮是

符号与亚符号人工智能方法:朋友还是敌人?
符号和亚符号代表人工智能 (AI) 的两个主要分支。人工智能领域在 20 世纪 50 年代取得了巨大进步并确立了地位,在此之前,McCulloch 和 Pittes 做出了一些最著名和开创性的工作,他们在 1943 年建立了神经网络 (NN) 的基础,而 Turing 的工作则在 20 世纪 50 年代引入了机器智能测试,即图灵测试。自发明以来,该领域的发展经历了起起伏伏,俗称人工智能季节,其特点是“夏季”和“冬季”。这些起伏的具体时期尚不清楚,但是,我们根据维基百科和 Henry Kautz 在 AAAI 2020 上的演讲 1“第三个 AI 夏天”采用了中间惯例。我们在图 1 中展示了这些发展的时间表。第一个 AI 夏天,也称为黄金时代,始于 AI 诞生几年后,它基于对解决问题和推理的乐观态度。直到 20 世纪 80 年代,主导范式都是符号 AI。这时,亚符号 AI 开始占据主导地位并受到关注,直到最近几年。两种不同方法之间存在长期而未解决的争论。然而,不同人工智能领域之间的这场较量即将结束,因为我们目前正在经历第三次人工智能之夏,其中主导浪潮是


符号、非符号和非...的 fMRI 适应性研究
人类大脑中不同格式的量级是如何表示的?我们使用功能性磁共振成像适应性来分离 45 名成年人的符号、数量和物理尺寸的表示。结果表明,支持数字符号被动处理的神经关联在解剖学和表征上与支持数量和物理尺寸的神经关联基本无关。从解剖学上讲,数量和大小的被动处理与右顶叶内沟的激活相关,而与数量处理相比,符号数字处理与左顶叶下小叶的激活相关。从表征上讲,支持符号的激活神经模式与支持双侧顶叶数量和大小的神经激活模式不同。这些发现挑战了长期以来的观点,即文化习得的将符号数字概念化的能力使用与支持用于处理数量的进化古老系统完全相同的大脑系统来表示。此外,这些数据表明,支持数值量级处理的区域对于非数值量级的处理也很重要。这一发现促使人们未来研究获取符号数字知识的神经后果。
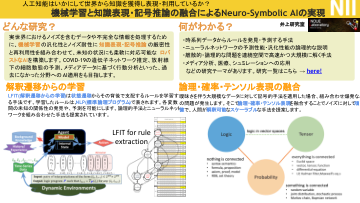
结合机器学习、知识表示和符号推理的神经符号......
为了处理现实世界中的噪声数据和不完整信息,我们将机器学习的通用性和抗噪性与知识表示和符号推理的严谨性和可重用性相结合,构建能够灵活应对未知情况的强大人工智能。我们还旨在将AI应用到以前从未应用过的领域,例如估计COVID-19的基因网络,预测辐射下的细胞动态以及基于媒体数据分析行为。

在教育和学习的背景下结合符号和亚符号人工智能
摘要 抽象能力是成功掌握 FHNW(Fachhochschule Nordwestschweiz)商业信息技术课程 (BIT) 的关键。面向对象 (OO) 就是一个例子 - 它广泛需要分析能力。为了测试与 OO 相关的能力,我们根据 Blackjack 场景开发了一份针对未来学生和一年级学生的问卷 (OO SET)。OO SET 的主要目标是识别在没有大量培训的情况下可能在 OO 相关模块中失败的学生群体。对于数据的解释,使用了 Kohonen 特征图 (KFM),它现在在数据挖掘和探索性数据分析中非常流行。但是,与所有亚符号方法一样,KFM 缺乏对其结果的解释和说明。因此,我们计划在现有算法的基础上添加一个“后处理”组件,该组件为集群生成命题规则,并有助于提高招生和教学过程中的质量管理。通过这种方法,我们通过在机器学习和知识工程之间架起一座桥梁,协同整合符号和亚符号人工智能。

神经符号AI:桥接神经网络和符号推理
人工智能(AI)在近几十年来取得了巨大的进步,由神经网络和象征性推理系统的进步提供支持。神经网络从数据中获得学习模式,在图像识别,自然语言处理和自动驾驶等任务中取得突破。另一方面,符号推理系统为逻辑推理和知识表示提供了结构化的,基于规则的框架,使其非常适合需要解释性,概括性和解释性的域。但是,这些范式通常是孤立地运行的,当面对需要强大的学习能力和逻辑推理的任务时,会导致局限性。本文探讨了神经符号AI的新兴领域,该领域试图将神经网络和象征性推理整合到统一的框架中,克服了它们各自的缺点并在AI开发中解锁了新的可能性。