XiaoMi-AI文件搜索系统
World File Search System经典

黑洞和半经典量子引力
为什么黑洞与量子引力有关?与广义相对论方程的所有其他解一样,它们是先验的完全经典的对象。然而,一个令人惊讶的特征是它们表现出热力学性质。普通热力学定律是许多微观状态集合的宏观、粗粒度描述;例如,使用统计力学,可以从气体动力学理论中推导出这些定律。同样,黑洞热力学定律可以看作是广义相对论提供的低能有效理论中引力的突现特性。了解黑洞热力学如何随着能量的增加而改变,可能会揭示一些关于量子引力基本理论的信息,从而为时空的量子结构提供一个窗口。相反,应该可以从量子引力的基本理论出发,采取一些适当的粗粒度极限,推导出黑洞热力学及其修正。

基于经典描述的模糊 Kolmogorov 复杂度
柯尔莫哥洛夫-所罗门诺夫-柴廷(Kolmogorov,简称 Kolmogorov)复杂度由 Solomonoff [ 1 ] 和 Kolmogorov [ 2 ] 独立提出,后来柴廷 [ 3 ] 也提出了这一复杂度。该复杂度基于可以模拟任何其他图灵机的通用图灵机的发现 [ 4 , 5 ]。单个有限字符串的柯尔莫哥洛夫复杂度是能够正确生成该字符串作为输出的通用图灵机的最短程序的长度,也是对字符串所含信息量的度量。已经证明,虽然存在多种图灵机,但最短程序的长度是不变的,在底层图灵机的选择下,其差异最多为一个加法常数 [ 6 ]。柯尔莫哥洛夫复杂度理论广泛应用于问答系统 [ 7 ]、组合学 [ 8 ]、学习理论 [ 9 ]、生物信息学 [ 10 ] 和密码学 [ 11 , 12 ] 等领域。1985 年,Deutsch [ 13 ] 引入量子图灵机作为量子计算机的理论模型。量子图灵机扩展了经典图灵机模型,因为它们允许在其计算路径上发生量子干涉。Bernstein 和 Vazirani [ 14 ] 表明量子图灵机在近似意义上具有通用性。最近,一些研究者提出了一些柯尔莫哥洛夫复杂度的量子版本。Vitányi [ 15 ] 提出了量子柯尔莫哥洛夫复杂度的定义,它度量近似量子态所需的经典信息量。Berthiaume 等人 [ 16 ] 提出了一种基于柯尔莫哥洛夫复杂度的量子柯尔莫哥洛夫复杂度定义。 [16] 提出了一种新的量子比特串量子柯尔莫哥洛夫复杂度定义,即通用量子计算机输出所需字符串的最短量子输入的长度。Zadeh [17] 提出了模糊计算的第一个公式,他基于图灵机和马尔可夫算法的模糊化,定义了模糊算法的概念。随后,Lee 和 Zadeh [18] 定义了模糊语言的概念。Santos [19] 证明了模糊算法和模糊图灵机之间的等价性。接下来,Wiedermann [20] 考虑了模糊计算的可计算性和复杂性。利用 Wiedermann 的工作,Bedregal 和 Figueira [21] 证明了不存在可以模拟所有模糊图灵机的通用模糊图灵机。随后,李[22,23]研究了模糊图灵机的一些变体。他证明了

经典电动力学中的排斥相互作用
摘要:在此,我们在感应方程(麦克斯韦方程之一)中引入了一个附加项。应用标量和矢量势的相关拉格朗日形式适用于此修改的麦克斯韦方程。在哈密顿原理的框架内,我们能够推导出场变量电场 E 和磁感应 B 具有负“质量项”的克莱因-戈登方程。我们可以从方程的数学结构得出结论,出现了排斥相互作用。可以计算出当前情况下的惠勒传播子,由此可以讨论场的时间演化。尽管这些方程具有快子解,但结果符合因果关系原理。根据该理论,场中可能会出现自发电荷分离过程。

Byte Jan 1995 - 经典苹果
BYTE(ISSN 0360·5280)0;在新罕布什尔州和其他国际邮局出版。邮资已付,邮编为 Wlnnipeg。MaMoba。加拿大邮政国际公共邮件产品销售协议编号 246492。GST 的 Aog\st oro d McGraw-HUI, Inc.。GST U 123075673。印于美国国情咨文。邮政信箱:发送地址更改并填写!quoSbOns 10 BYTE 订阅。P.0。Box 552。Hi\;hlSI._.. NJ 06520。
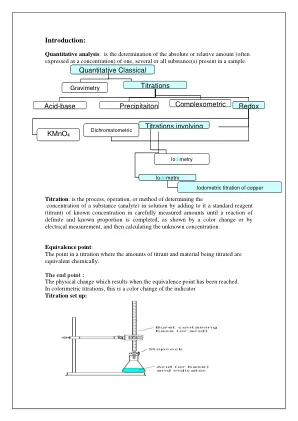
定量的经典化学分析滴定酸 -
弱酸是一种在产生氢(H 3 O +)离子水溶液中部分电离的化合物。任何弱酸解离的一般方程式可以写为:HA(aq) + H 2 O(l)a - (aq) + H 3 O +(aq)(1)添加强碱会导致中和反应导致氢氧化离子(oh -oh)与水合产生水:hydronium的水:在中和反应中,根据Le Chatelier的原理将方程1中的平衡移到右侧。neu tralization过程可以写成方程(1)和(2)的总和:ha(aq) + oh - (aq)a - (aq) + h 2 o(l)(l)(3)未知解的浓度可以通过测量添加的滴定剂量达到等效点来确定。当所有酸被碱中和时,等效点发生。将通过使用在等价点上更改颜色的指标来确定

估计经典和量子天空状态的模式
在这篇综述中,我们讨论了有关机器学习算法开发的最新结果,用于表征磁性的磁性磁纹理,这些磁性质地源自Dzyaloshinskii - Moriya - Moriya相互作用,该相互作用竞争了Heisenberg在Ferromagnets中的Heisenberg同型交换。我们表明,对于经典的自旋系统,有一系列的机器方法,可以根据几个磁化快照的基础,允许其准确的相位进行分类和定量描述。反过来,对量子天空的研究是一个较少探索的问题,因为对使用经典超级计算机进行此类波浪函数的模拟存在基本局限性。一个人需要找到模仿近期量子计算机上量子天空的方法。在这方面,我们讨论了基于从投影测量值获得的斑点数量有限的量子天空状态来估算经典对象的结构复杂性的实现。

交替分层变分量子电路可以利用经典阴影进行有效的经典优化
变分量子算法 (VQA) 是经典神经网络 (NN) 的量子模拟。VQA 由参数化量子电路 (PQC) 组成,该电路由多层假设(更简单的 PQC,与 NN 层类似)组成,这些假设仅在参数选择上有所不同。先前的研究已将交替分层假设确定为近期量子计算中潜在的新标准假设。事实上,浅层交替分层 VQA 易于实现,并且已被证明既可训练又富有表现力。在这项工作中,我们引入了一种训练算法,可指数级降低此类 VQA 的训练成本。此外,我们的算法使用量子输入数据的经典阴影,因此可以在具有严格性能保证的经典计算机上运行。我们证明了使用我们的算法在寻找状态准备电路和量子自动编码器的示例问题中将训练成本提高了 2-3 个数量级。

论量子密码学与经典通信的中心原语
最近的研究为密码学引入了“量子计算经典通信”(QCCC)(Chung 等人)。有证据表明,单向谜题(OWPuzz)是此设置(Khurana 和 Tomer)的自然中心密码原语。被视为中心的原语应具备若干特征。它应行为良好(在本文中,我们将其视为具有放大、组合器和通用构造);它应由多种其他原语所暗示;并且它应等同于某些类有用的原语。我们提出了组合器、正确性和安全性放大,以及 OWPuzz 的通用构造。我们对安全性放大的证明使用了来自 OWPuzz 的新的、更清晰的 EFI 构造(与 Khurana 和 Tomer 的结果相比),该构造可推广到弱 OWPuzz,是本文中技术含量最高的部分。此前已知 OWPuzz 由其他感兴趣的原语所隐含,包括承诺、对称密钥加密、单向状态生成器(OWSG)以及伪随机状态(PRS)。然而,我们能够通过展示一般 OWPuzz 与受限类 OWPuzz(具有有效验证的原语,我们称之为 EV-OWPuzz)之间的黑盒分离来排除 OWPuzz 与许多这些原语的等价性。然后我们证明 EV-OWPuzz 也由大多数这些原语所隐含,这也将它们与 OWPuzz 区分开来。这种分离还将扩展 PRS 与高度压缩 PRS 区分开来,回答了 Ananth 等人的一个悬而未决的问题。

来自经典预言机的量子状态混淆
量子密码学中一个尚未解决的主要问题是是否有可能混淆任意量子计算。事实上,即使在经典的 Oracle 模型中,人们仍然很难理解量子混淆的可行性,在经典的 Oracle 模型中,人们可以免费混淆任何经典电路。在这项工作中,我们开发了一系列新技术,用它们来构建量子态混淆器,这是 Coladangelo 和 Gunn (arXiv:2311.07794) 最近在追求更好的软件版权保护方案时形式化的一个强大概念。量子态混淆是指将一个量子程序(由一个具有经典描述的量子电路 C 和一个辅助量子态 | ψ ⟩ 组成)编译成一个功能等价的混淆量子程序,该程序尽可能隐藏有关 C 和 | ψ ⟩ 的信息。我们证明了我们的混淆器在应用于任何伪确定性量子程序(即计算(几乎)确定性的经典输入/经典输出功能的程序)时是安全的。我们的安全性证明是关于一个高效的经典预言机的,可以使用经典电路的量子安全不可区分混淆来启发式地实例化它。我们的结果改进了 Bartusek、Kitagawa、Nishimaki 和 Yamakawa (STOC 2023) 的最新工作,他们也展示了如何在经典预言机模型中混淆伪确定性量子电路,但仅限于具有完全经典描述的电路。此外,我们的结果回答了 Coladangelo 和 Gunn 的一个问题,他们提供了一种关于量子预言机的量子态不可区分混淆的构造,但留下了一个具体的现实世界候选者的存在作为一个悬而未决的问题。事实上,我们的量子状态混淆器与 Coladangelo-Gunn 一起为所有多项式时间函数提供了“最佳”复制保护方案的第一个候选实现。我们的技术与之前关于量子混淆的研究有很大不同。我们开发了几种新颖的技术工具,我们期望它们在量子密码学中得到广泛应用。这些工具包括一个可公开验证的线性同态量子认证方案,该方案具有经典可解码的 ZX 测量(我们从陪集状态构建),以及一种将任何量子电路编译成“线性 + 测量”(LM)量子程序的方法:CNOT 操作和部分 ZX 测量的交替序列。

用于识别黄色的经典和机器学习工具......
油菜籽在发育过程中含有叶绿素,使其呈现绿色。随着种子的成熟,它们会呈现出黑色、红褐色到黄色等颜色。黑色和红褐色种子的种皮会积累色素,而黄籽品种的种皮透明,可以露出胚的颜色。研究表明,黄籽油菜籽比黑籽品种休眠期短、发芽更简单、含油量更高,因此培育黄籽油菜籽是提高油分含量的有效方法(Yang et al.,2021)。芥菜和油菜黄籽品种的鉴别相对简单,因为纯黄色表型在遗传上是稳定的(Li et al.,2012;Chen et al.,2015)。然而,由于种皮颜色变异复杂,包括黄色中夹杂黑色斑点、斑块或棕色环等杂色,油菜种皮一直未能获得稳定的纯黄色后代,且分离后代的种皮颜色呈现连续变异(刘,1992;Auger等,2010;Qu等,2013),因此准确、高效地测定油菜种皮颜色仍是一项关键且具有挑战性的任务。许多研究涉及油菜籽颜色的鉴别(Li等,2001;Somers等,2001;Zhang等,2006;Baetzel等,2003;Tańska等,2005;Li等,2012;Liu等,2005;Ye等,2018)。例如,Li等(2001)通过目视观察来评估甘蓝型油菜的黄籽程度,这种方法简单但过于依赖观察者,导致识别可能不准确。Somers等(2001)利用光反射来评估黄籽颜色等级,通过测量反射值并计算籽粒颜色指数或光反射值。该方法虽然较为客观,但仅能捕捉亮度等单维颜色数据,忽略了原始材料的丰富信息。为了解决这一限制,许多学者致力于通过 RGB 颜色系统进行数字图像分析( Zhang et al.,2006 ; Baetzel et al.,2003 ; Ta ńska et al.,2005 ; Li et al.,2012 ; Liu et al.,2005 ; Ye et al.,2018 )。然而,油菜籽表皮颜色复杂且相似,精准识别颜色具有挑战性,现有的技术缺乏可靠性和标准化。因此,准确、有效地测量黄籽油菜的颜色仍然至关重要。化学计量学和计算机技术的最新进展导致了近红外光谱技术(NIRS)的发展,这是一种结合物体图像和光谱数据的技术。 NIRS 以其速度快、无损和高效而闻名,被广泛用于农产品的快速、无损分析。多项研究已经证明了它的实用性(Guo 等人,2019年;布等人,2023;梁等人,2023;刘等人,2021;佩蒂斯科等人,2010;森等人,2018;刘等人,2022;张等人,2020;魏等人,2020;张等人,2018;江等,2017;李等人,2022;江等,2018;他等人,2022)。例如,郭等人。 (2019) 使用 NIRS 成像系统 (380 – 1,000 nm) 来准确量化掺假大米,而 Bu 等人。 (2023) 将高光谱成像与卷积神经网络相结合,建立了高粱品种识别的智能模型,准确率超越了现有模型。该技术也已应用于油菜生长诊断。例如,刘等人 (2021) 开发了一种基于高光谱技术的检测算法来预测甘蓝型油菜中的油酸含量。Petisco 等人 (2010) 研究了甘蓝型油菜的可见光和近红外光谱。