XiaoMi-AI文件搜索系统
World File Search System行人


使用混合特征融合
预测行人的穿越意图是在现实世界中安全驾驶自动驾驶汽车(AV)的重要任务。行人的行为通常会受到交通场景中周围环境的影响。基于基于视觉的神经网络的最新作品从图像中提取关键信息以执行预测。但是,在驾驶环境中,存在许多关键信息,例如驱动区域中的社交和场景互动,自我汽车和目标行人之间的位置和距离以及所有目标的运动。如何正确探索和利用上述隐式相互作用将促进自动驾驶汽车的发展。在本章中,两个新颖的属性,行人在道路或人行道上的位置,以及从目标行人到自我卡车的相对距离,这些距离源自语义图和深度图与边界框的相对距离。提出了基于多模式的混合预测网络,以捕获所有特征与预测行人交叉意图之间的相互作用。通过两个公共行人穿越数据集评估PIE和JAAD,拟议的混合框架的表现优于最先进的精度3%。关键字:行人交叉,特征融合

对视觉预测的行动推论 - 和...
视觉和语言导航(VLN)engoss从移动性的角度使用语言和视觉输入与自动驾驶汽车相互作用。该领域的大部分工作都集中在空间推理和视觉信息的语义基础上。但是,基于现场行人的行为的推理并不是那么考虑。在这项研究中,我们提供了一个VLN数据集,用于针对目标预测,以研究当前VLN模型执行动作推断的程度。我们介绍了一个众包过程,以两个步骤构建该任务的数据集:(1)考虑行人的下一个行动,考虑行人的下一个行动,考虑了行人的下一个行动,考虑行人的下一个动作。我们对目标预测的模型的基准测试结果使我们相信这些模型可以学会推理动作的效果以及对某个特定目的地的目标的效果。但是,仍然有很大的改进范围。
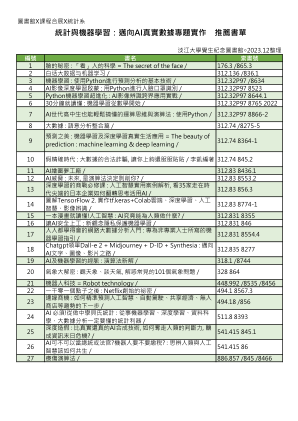
统计与机器学习:迈向AI真实数据专题实作推荐书单
编号书名索书号1 脸的秘密: 「看」人的科学= The secret of the face / 176.3 /865.3 2 白话大数据与机器学习/ 312.136 /836.1 3 机器学习: 使用Python进行预测分析的基本技术/ 312.32P97 /8634 4 AI影像深度学习启蒙: 用Python进行人脸口罩识别/ 312.32P97 8523 5 Python机器学习超进化: AI影像辨识跨界应用实战/ 312.32P97 8644.1 6 30分钟就读懂: 机器学习从数学开始/ 312.32P97 8765 2022

俄勒冈州审判律师协会
妮可·菲尔德(Nicole Fields)从野餐的城市小径上回家。城市步道上的行人天桥非常滑。Fields女士严重折断了她的腿。纽波特市说,她从事招募活动,因此该市不受责任感。Fields女士声称,从野餐回家正在使用行人天桥进行运输目的,因此,应该允许她试图说服陪审团,以维持人行人的疏忽。

使用交通摄像头进行车辆和行人检测、跟踪和速度估计的基于人工智能的视频分析:应用和机会
• 超速检测,超速者百分比 • 单个车辆的速度估计 • 平均链路速度估计和速度变化 • 当前纽约市交通局公共闭路电视馈送是不连续的,如果提供对具有连续流媒体的后台馈送的访问,则此方法可应用于该市所有 900 多个闭路电视 • 有可能填补非学校区域区域的空白

视觉人工智能 - Sentinel Safety
维护和监控行人禁区可靠的警报改变行为外部语音警报通知行人危险区域机舱内警报 - 提示操作员停止、检查和避免事故运动停止选项 - 是一种工程控制

使用增强的Yolo进行实时行人和物体检测
许多技术和系统,包括自动驾驶汽车,监视系统和机器人应用,都依赖能力来准确检测行人以确保其安全性。随着对实时对象检测的需求不断上升,许多研究人员致力于开发有效且值得信赖的算法以供行人识别。通过将学习复杂性意识到的级联反应与增强的级联集成,您只看一次(YOLO)算法,该论文提供了一个实时系统,用于识别项目和行人。使用Karlsruhe技术研究所和丰田技术学院(KITTI)行人数据集评估了所提出的方法的性能。优先考虑速度和准确性,增强的Yolo算法的表现优于其基线。在Kitti行人数据集上,建议的技术在现实世界中的有效性强调了其有效性。此外,复杂性感知的学习级联反应为简化的检测模型做出了贡献,而不会损害性能。当应用于需要对象和个人实时识别的方案时,提出的方法会始终提供有希望的结果。

等离子体P-TAU217预测常染色体显性阿尔茨海默氏病的体内脑病理学和认知
摘要 - 本文解决了使用增强的对象检测方法检测行人的问题。尤其是,本文考虑了在自主驾驶场景中的闭塞行人检测问题,在这种情况下,准确性和速度之间的性能平衡至关重要。现有的作品着重于独立于身体部位语义的独特人的学习表示。为了实现实时表现以及可靠的检测,我们引入了一个基于身体部位的行人检测体系结构,通过计算有效的约束优化技术将身体部位融合在一起。我们证明我们的方法显着提高了检测准确性,同时添加可忽略的运行时开销。我们使用现实世界数据集评估了我们的方法。实验结果表明,所提出的方法的表现优于现有的行人检测方法。
