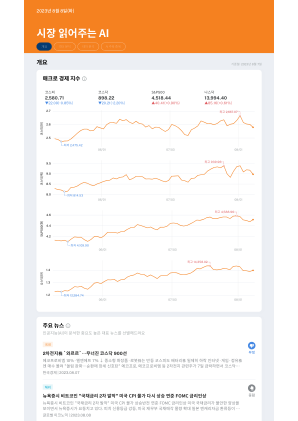
XiaoMi-AI文件搜索系统
World File Search System读取

基于DNA折纸的电子读取仅读取记忆
抽象的脱氧核糖核酸(DNA)已成为设计下一代超高密度存储设备的有前途的构建块。尽管DNA本质上是高度耐用且密度极高的,但其作为存储设备基础的潜力目前受到诸如昂贵且复杂的制造过程以及耗时的阅读工艺操作等限制的阻碍。在本文中,我们建议将DNA横梁阵列体系结构用于电气可读的读取 - 单位(DNA-ROM)。对于DNA-ROM,我们选择了两个DNA链分别代表位1和位0。DNA电荷传输已通过接触-DNA接触设置进行了研究。从DNA电荷运输研究中获得的结果已用于分析横梁阵列。通过将图像加载到128×128横杆上,对性能进行了分析。对于此应用,我们已经观察到了4.52%的位错误率,功耗为6.75 µW。

如何读取应变数据表
CECT 9999 CECT细菌中的登录数 /细菌 /细菌 /酵母 /丝状真菌型应变,如果应变是命名型型CECT CECT CECT验证的菌株,仅可用于CECT经过验证的菌株。提供了指定应变概况(小型化系统(如API测试和选择性和差异培养媒体上的增长)的概况的报告链接,如果库存出现的库存显示,如果劳力目前缺货(大约1个月),该物种的名称是该物种的科学名称,则应通过作者名称和本性名称的定期来指示。物种虽然该名称未有效出版。在真菌的情况下,由于活真菌培养物不能具有类型标本的形式命名命名状态,因此从类型标本中得出的任何分离物的真实性或产生干燥类型培养物(EX-Type)的真实性如下:T = t = ex type株(通常); HT = Ex Holotype菌株(如果要明确指示相关样品的整型状态); nt = ex neotype菌株; lt =外型应变; it = ex iSotype; st = ex syntype; pt = ex Paratype; ptt = pathotype; aut =正宗应变;或=原始应变;参考=参考应变品种,血清型,血清,血清,Biovar同义词的其他名称的其他名称名称是由存款人提供的应变的菌株名称名称,其他集合中的其他集合登录号和/或WDCM参考菌株分类目录访问(原位)采样数据。培养基的组成与培养物中的数量有关。在名古屋方案的背景下,在生态系统和自然栖息地中存在遗传资源的样本,以及在驯养或耕种物种的情况下,在他们开发出独特特性的环境中。包括(如果有),包括来源,位置,人员/机构和访问年份隔离数据数据,涉及与原始样品隔离的隔离。包括(如果有),包括位置,人员/机构和隔离的年度历史历史记录在cect中。从CECT收到压力的年份开始,然后在存款时,在括号中的菌株的科学名称,当时与当前的科学名称生长条件培养培养基和生长条件不同,这确保了应变的良好恢复和生长。还提供了有关该领域的更多详细信息的文档“培养条件”的链接

如何读取脱碳目标跟踪器
13基线年本列表示银行用来为煤炭部门设定其2030年脱碳目标的基线年。目标基础年份不得超过目标设定之前的两个完整报告。银行可以在设定进一步的目标或特殊经济环境的情况下和/或银行自身控制以外的数据质量问题的情况下,如果允许他们在大多数目标中使用相同的基准年和/或基本年度否则将是非典型的,则将长达四年。银行应在这种情况下提供理由。

如何读取消毒产品标签
对于一种更清洁和消毒剂的产品,可以使用一步产品清洁和消毒表面。如果它是两步产品,则需要先擦除表面才能清洁,然后再次擦拭以消毒。如果产品不是清洁和消毒剂,则需要单独的清洁剂才能在消毒之前清洁表面。每种消毒剂都包含一种活跃成分,该成分会使微生物失活并实现消毒。

基于多层 RRAM 的深度学习推理引擎的读取扰动和双极读取方案研究
摘要——基于多层电阻式随机存取存储器 (RRAM) 的突触阵列可以实现矢量矩阵乘法的并行计算,从而加速机器学习推理;然而,由于模拟电流沿列相加,因此单元的任何电导漂移都可能导致推理精度下降。在本文中,在基于 2 位 HfO 2 RRAM 阵列的测试车辆上统计测量了读取干扰引起的电导漂移特性。通过垂直和横向细丝生长机制对四种状态的漂移行为进行了经验建模。此外,提出并测试了一种双极读取方案,以增强对读取干扰的恢复能力。建模的读取干扰和提出的补偿方案被纳入类似 VGG 的卷积神经网络中,用于 CIFAR-10 数据集推理。

机场上的车间学习 - 读取和...
数学系成立于1996年,旨在为数学及其在本科和研究生级别的工程领域提供强大的基础。数学系有15名教职员工,他们都是博士学位,在各种领域,例如代数,粗糙的理论,排队理论,随机过程,图形论,流体力学,功能分析,拓扑,图像处理,机器学习,深度学习等部门组织了SSN Trust和其他资助机构定期赞助的各种研讨会,FDP和会议。该系在钦奈安娜大学的领导下被公认。大约29 Ph.D.学者获得了学位,在我们教师的指导下,约有27名学者正在追求学位。大约29 Ph.D.学者获得了学位,在我们教师的指导下,约有27名学者正在追求学位。

教区通讯读取弱 div>
教区新闻:Cathnews New Zealand:本周主教会议启动了新的Cathnews New Zealand项目。该部支持天主教徒和对教会感兴趣的人,以获取新闻和其他感兴趣的内容。它从已经发表的材料中汲取并包括原始内容。接收新西兰Cath News的最佳方法是签署新闻通讯,该通讯是在星期二和星期五早上发送的。访问Cathnews新西兰网站,并在https:// cathnewsnz.com

细胞如何读取基因组:从 DNA 到蛋白质
直到 20 世纪 50 年代初 DNA 结构被发现后,人们才清楚细胞中的遗传信息是如何编码在 DNA 核苷酸序列中的。自那时起,我们取得了惊人的进展。在 50 年内,我们知道了包括人类在内的许多生物的完整基因组序列。因此,我们知道了生产像我们这样的复杂生物所需的最大信息量。生命所需遗传信息的限制制约了细胞的生化和结构特征,并清楚地表明生物学并不是无限复杂的。在本章中,我们将解释细胞如何解码和使用其基因组中的信息。关于仅有四个“字母”——DNA 中的四种不同核苷酸——的字母表中的遗传指令如何指导细菌、果蝇或人类的形成,人们已经了解了很多。然而,我们仍有许多东西需要探索,比如生物体基因组中存储的信息如何产生具有 500 个基因的最简单的单细胞细菌,更不用说它如何指导具有大约 25,000 个基因的人类的发育。我们仍有许多未知之处,因此,许多令人着迷的挑战等待着下一代细胞生物学家。通过研究果蝇(Drosophila melanogaster)的一小部分基因组,我们可以了解细胞在解码基因组时面临的问题(图 6-1)。该基因组和其他基因组中存在的许多 DNA 编码信息指定了生物体制造的每种蛋白质的线性顺序(即氨基酸序列)。如第 3 章所述,氨基酸序列反过来决定了每种蛋白质如何折叠以产生具有独特形状和化学性质的分子。当细胞制造特定蛋白质时,它必须准确解码基因组的相应区域。基因组 DNA 中编码的其他信息精确地指定了生物体生命中的每个基因将在何时以及在哪种细胞类型中表达为蛋白质。由于蛋白质是细胞的主要成分,基因组的解码不仅决定了细胞的大小、形状、生化特性和行为,还决定了地球上每个物种的独特特征。人们可能已经预测到,基因组中存在的信息将以有序的方式排列,类似于字典或电话簿。尽管某些细菌的基因组似乎组织得相当好,但大多数多细胞生物(例如我们的果蝇示例)的基因组却出奇地混乱。小段编码 DNA(即编码蛋白质的 DNA)散布在大段看似毫无意义的 DNA 中。基因组的某些部分包含许多基因,而其他部分则完全没有基因。在细胞中彼此密切协作的蛋白质通常将其基因位于不同的染色体上,相邻基因通常编码细胞内彼此关系不大的蛋白质。因此,解码基因组并非易事。即使借助强大的计算机,研究人员仍然很难在复杂基因组的 DNA 序列中明确定位基因的起始和终止位置,更不用说预测每个基因在生物体生命中何时表达。尽管人类基因组的 DNA 序列是已知的,但识别每个基因并确定其产生的蛋白质的精确氨基酸序列可能至少需要十年时间。然而,我们体内的细胞每秒都会进行数千次这样的操作。