XiaoMi-AI文件搜索系统
World File Search System谓词

BIM第五学期教学大纲2024.pdf-管理学院
单元4。知识表示14 LHS。Definition and importance of Knowledge, Issues in Knowledge Representation, Knowledge Representation Systems, Properties of Knowledge Representation Systems, Types of Knowledge Representation Systems: Semantic Nets, Frames, Conceptual Dependencies, Scripts, Rule Based Systems(Production System), Propositional Logic, Predicate Logic, Propositional Logic(PL): Syntax, Semantics, Formal logic-connectives, truth tables, tautology, validity, well-formed-formula,使用分辨率,向后链式和前进的推理,谓词逻辑:FOPL,语法,语义,语义,定量,与FOPL的推断:通过转换为PL(存在和普遍实例化),统一和提升,使用分辨率,使用不确定的知识来处理不确定的知识,辐射变量,先前和后网络,使用完整的范围,使用完整的范围,bayes bay obles,bayes bay obles,bays bay obles,bayes bay obles,bayes obles of bay bay bays bay bay bay'模糊逻辑:模糊集,模糊集中的会员资格,模糊规则基础系统。

510(k)摘要-Cobas Integra Gen. 3
特征谓词设备:葡萄糖HK修饰的装置:葡萄糖HK液体新配方(K972250)一般预期用途/ cassefte cobas Integra在体外测试葡萄糖HK液体的定量指示,包括在血清中确定葡萄糖的葡萄糖,使用体外诊断型原子胶质质量,尿布素,尿布素,尿布素,尿布量,塞雷氏菌,塞雷氏症,系统的Cobas Integra Integra系统。葡萄糖测量是对血清中诊断和治疗葡萄糖浓度的定量确定,碳水化合物代谢血浆,包括糖尿病(CSF)在内的碳水化合物代谢血浆,尿液和脑脊髓疾病。葡萄糖测量值和特发性用于诊断和低血糖。治疗包括糖尿病和特发性低血糖在内的碳水化合物代谢疾病。_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ Specimen type Serum, plasma, urine, CSF Same Test principle Reference Enzymatic reference method with Same method hexokinase.试剂信息稳定性 - 架子2-8 0 c直到到期日期相同的寿命和板载柯巴斯Integra 400 8周在10至15°C

探索基于人工智能的聊天机器人的潜力来生成联合SPARQL查询通过生物信息学知识图
生物数据库中的大量数据泛滥提供了医疗保健和生命科学领域的各种信息。这些数据库为研究人员,科学家和工作专业人员提供了加速发现,开发新的假设并确定新型模式的机会[1]。另一方面,这些数据库需要实现复杂的存储和检索系统来从这些大数据库中检索信息。这成为研究人员和科学家的挑战[2]。作为RDF知识图发布的大多数生物数据库都依赖于SPARQL(SPARQL协议和RDF查询语言)等复杂的查询语言[3]来从数据库中检索信息。没有技术知识或有限的技术知识,研究人员和域用户无法编写准确且可靠的SPARQL查询,这可能会成为利用这些数据库的全部潜力的瓶颈[3] [1]。SPARQL是一种查询语言,可以使用户从数据库中查询信息[4] [3]。许多生物数据库利用RDF(资源描述框架)数据模型,其中RDF表示信息为适用于蛋白质功能(例如蛋白质功能,基因相互作用)的复杂生物学关系的互连三元组(受试者,谓词,对象)[2] [2] [4]。RDF数据可通过SPARQL端点提供,而SPARQL查询语言是专门设计用于查询RDF数据的,可以有效
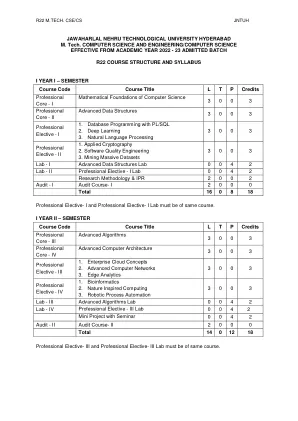
r22 m. 技术。中央安全与环境部
第一单元:基础逻辑与证明:命题逻辑、命题逻辑的应用、命题等价、谓词和量词、嵌套量词、推理规则、证明简介、证明方法与策略。第二单元:基本结构、集合、函数、序列、和、矩阵和关系:集合、函数、序列与和、集合和矩阵关系的基数、关系及其性质、n 元关系及其应用、表示关系、关系的闭包、等价关系、偏序。第三单元:算法、归纳与递归:算法、函数的增长、算法的复杂性。归纳与递归:数学归纳、强归纳与良序、递归定义与结构归纳、递归算法、程序正确性。第四单元:离散概率和高级计数技术:离散概率简介。概率论、贝叶斯定理、期望值和方差。高级计数技术:递归关系、解决线性递归关系、分治算法和递归关系、生成函数、包含-排除、包含-排除的应用。第五单元:图:图和图模型、图术语和特殊类型的图、表示图和图同构、连通性、欧拉和汉密尔顿路径、最短路径问题、平面图、图着色。树:树的简介、树的应用、树的遍历、生成树、最小生成树。教科书:

使用Probstars对神经网络进行定量验证
最深层的神经网络(DNN)验证研究重点是定性验证,该验证回答了DNN是否具有安全性/鲁棒性属性。本文提出了一种将定性验证转换为神经网络定量验证的方法。由此产生的定量验证方法不仅可以回答是或否问题,而且可以计算违反财产的可能性。为此,我们介绍了概率恒星(或简短概率)的概念,即众所周知的恒星集的新变体,其中谓词变量属于高斯分布,并提出了一种方法来计算高维空间中概率恒星的可能性。与处理约束输入集的现有作品不同,我们的工作将输入集视为截断的多元正常(高斯)分布,即除了输入变量的约束外,输入集还具有满足约束的可能性。输入分布表示为概率恒星集,并通过网络传播,以构建包含多个ProbStars的可触及到的可触发设置,该集合用于验证网络的安全性或鲁棒性属性。在违反财产的情况下,违规概率可以通过精确的验证算法来精确计算,也可以通过过度验证验证算法来计算。所提出的方法是在名为Starv的工具中实现的,并使用著名的ACASXU网络和火箭着陆基准进行评估。

cctr:校准不确定性的轨迹预测 -
自主驾驶系统依靠精确的轨迹前词进行安全有效的运动计划。尽管努力提高预测准确性,但由于数据噪声和不完整的观察,固有的不确定性仍然存在。许多策略需要将预测结果形式化为分布,并利用差异代表不明显。然而,我们的实验研究表明,现有的轨迹预测模型产生了不可靠的不可估计的估计,需要进行其他定制的核心过程。另一方面,直接将电流校准技术应用于预测输出可能会产生亚最佳结果,因为对所有预分解使用了通用缩放器并忽略了信息性的数据提示。在本文中,我们提出了使用调节器(CCTR)的定制校准温度,这是一个通用框架,可以校准外部分布。具体来说,CCTR 1)采用基于校准的正规器将输出差异与预测与地面真相之间的差异相一致,并且2)使用上下文和历史信息为每个预测提供了每个预测的量身定制的温度缩放器。涉及多种谓词和计划方法的广泛评估表明,CCTR比现有的校准算法和不确定性意识方法的优越性,校准质量的11% - 22%的显着提高,运动计划的17%-46%。

在大环境下从DNA序列中的单细胞基因表达预测
人类遗传变异影响诸如疾病易感性等性状的人类遗传变异经常通过以高细胞类型的特异性方式调节基因表达来起作用。能够直接从DNA序列预测基因表达的计算模型可以帮助解释表达调节变体的解释,而机器学习模型现在在捕获远程人体转录调控所需的较大序列环境中运行。然而,现有的谓词集中在批量转录测量上,其中基因表达异质性可以淹没在广泛定义的细胞类型中。在这里,我们使用转移学习框架,SEQ2细胞,利用预训练的表观基因组模型从单细胞分辨率的大序列上下文中进行基因表达预测。我们表明,SEQ2CELLS捕获了超出伪膨胀数据的分辨率的细胞特异性基因表达。使用SEQ2CELLS进行变异效应预测揭示了带注释的细胞类型中的异质性,并在细胞种群之间启用了变异效应的硅化转移。我们证明了单细胞分辨率下基因表达和变异效应预测的挑战和价值,并为解释基因组变异的解释提供了毫不妥协的分辨率和规模。

cctr:校准不确定性的轨迹预测 -
自主驾驶系统依靠精确的轨迹前词进行安全有效的运动计划。尽管努力提高预测准确性,但由于数据噪声和不完整的观察,固有的不确定性仍然存在。许多策略需要将预测结果形式化为分布,并利用差异代表不明显。然而,我们的实验研究表明,现有的轨迹预测模型产生了不可靠的不可估计的估计,需要进行其他定制的核心过程。另一方面,直接将电流校准技术应用于预测输出可能会产生亚最佳结果,因为对所有预分解使用了通用缩放器并忽略了信息性的数据提示。在本文中,我们提出了使用调节器(CCTR)的定制校准温度,这是一个通用框架,可以校准外部分布。具体来说,CCTR 1)采用基于校准的正规器将输出差异与预测与地面真相之间的差异相一致,并且2)使用上下文和历史信息为每个预测提供了每个预测的量身定制的温度缩放器。涉及多种谓词和计划方法的广泛评估表明,CCTR比现有的校准算法和不确定性意识方法的优越性,校准质量的11% - 22%的显着提高,运动计划的17%-46%。

从头运动和面部表达动力学
我们探讨了多模式行为线索的疗效,以解释人性和访谈特异性特征。我们利用名为Kinemes的基本头部动作单元,原子面部运动称为动作单元和语音特征来估计这些以人为中心的特征。经验结果证实,运动和动作单元可以发现多种特征的行为,同时还可以在支持谓词方面进行解释。对于融合提示,我们探讨了决策和特征级融合,以及基于添加剂的融合策略,该策略量化了三种方式对性状预测的相对重要性。在麻省理工学院访谈和第一印象候选筛查(FICS)数据集中检查各种长期长期记忆(LSTM)架构,用于分类和回归数据集,我们注意到:(1)多模式的方法优于非模态反应,以达到0.98的最高PCC,以获得激动人心的特质,以实现MIT和0.57的高级特征,以实现fick和0.57。 (2)通过单峰和多模式方法可以实现有效的性状预测和合理的解释,并且(3)遵循薄片的方法,即使是从两秒钟的行为snippets中也实现了有效的性状预测。我们的提示代码可在以下网址提供:https://github.com/deepsurbhi8/explainable_human_traits_预测。

在大环境下从DNA序列中的单细胞基因表达预测
人类遗传变异影响诸如疾病易感性等性状的人类遗传变异经常通过以高细胞类型的特异性方式调节基因表达来起作用。能够直接从DNA序列预测基因表达的计算模型可以帮助解释表达调节变体的解释,而机器学习模型现在在捕获远程人体转录调控所需的较大序列环境中运行。然而,现有的谓词集中在批量转录测量上,其中基因表达异质性可以淹没在广泛定义的细胞类型中。在这里,我们使用转移学习框架,SEQ2细胞,利用预训练的表观基因组模型从单细胞分辨率的大序列上下文中进行基因表达预测。我们表明,SEQ2CELLS捕获了超出伪膨胀数据的分辨率的细胞特异性基因表达。使用SEQ2CELLS进行变异效应预测揭示了带注释的细胞类型中的异质性,并在细胞种群之间启用了变异效应的硅化转移。我们证明了单细胞分辨率下基因表达和变异效应预测的挑战和价值,并为解释基因组变异的解释提供了毫不妥协的分辨率和规模。