XiaoMi-AI文件搜索系统
World File Search System递归

Diamond IO:晶格的不可区分性混淆的简单结构
难以区分的混淆(IO)已经取得了显着的理论进步,但是由于其高复杂性和效率低下,它仍然不切实际。最近的IO方案中的一种常见瓶颈是依赖自动化技术从功能加密(Fe)到IO中的依赖,该技术需要递归地调用每个输入位的Fe加密算法,这是为实用IO方案的重要障碍。在这项工作中,我们提出了钻石IO,这是一种新的基于晶格的IO结构,它用轻量级的矩阵操作代替了昂贵的递归加密过程。我们的构造在学习中被证明是安全的(LWE)和回避的LWE假设,以及我们在伪甲骨文模型中的新假设(All-Product LWE)。通过利用Agrawal等人引入的伪随机功能的Fe方案。(eprint'24)在非黑色盒子中,我们消除了对先前的Fe-io bootstrapping技术的依赖,从而显着降低了复杂性。剩下的挑战是将我们的新假设减少到LWE等标准的标准,进一步促进了实用和合理的IO构造的目标。

19it103 - 计算思维和python ...
条件:布尔值和运算符,条件(如果),替代(如果 - 否),有条件的(if-eLif-else);迭代:状态,and,and,nate,nate,tor,for,for,break,nock,继续,通过;富有成果的功能:返回值,参数,本地和全局范围,功能组成,递归;字符串:字符串切片,不变性,字符串函数和方法,字符串模块;列表为数组。说明性程序:平方根,GCD,指数,总和数字数量,线性搜索,二进制搜索。

埃德加·莫林复杂性范式下的大脑
摘要:本文旨在指出埃德加莫兰的复杂性理论对大脑研究的贡献。莫林认为,大脑是多元体的统一体,“Unitas multiplex”,因为它通过对话发挥作用,社会文化和遗传的大脑领域汇聚于其中,大脑中出现多种生态系统,使其成为现象关联、塑造和繁殖的核心。大脑是多中心的、多现象的和多维的;秩序-混乱-组织是通过递归、循环、组织操作结合在一起的。关键词:大脑、复杂性分析、创造力、心理生理学、健康。摘要:这是一篇反思性的文章,旨在指出埃德加·莫兰的复杂性理论对大脑研究的贡献。对于莫兰来说,大脑是一个多元的单位,“unitas multiplex”,因为它以对话的方式发挥作用,并且遗传-大脑-社会文化领域在其中汇聚,由此产生了多种生态系统联系,使大脑成为关联、形成和现象再现的中心。大脑是多中心的、多现象的和多维的,其中的有序-混乱-组织通过递归-循环的组织功能结合在一起。关键词:分析、大脑、复杂性、创造力、心理生理学、健康。

网格空白的太阳能光伏电动电池应用
摘要 - 该项目的主要目的是开发一个系统,以连续为电动汽车电池充电并控制三个相网系统。使用扰动和观察方法用于从太阳PV阵列中获取最大功率。电动汽车电池在直流链路处的双向转换器连接,直流链路也连接到电压源转换器,该电动汽车电池在低负载需求下会充电并在高负载需求下排放。此转换器通常通过此电池电池在DC链路处保持最大功率,可以通过拿到低额定电池来存储额外的电源来充电。使用网格连接的太阳能PV电池电池系统以更好的方式使用自适应递归数字过滤器。当太阳能消失发生变化并更改负载需求时,具有递归过滤器控制的系统是可控制的。VSC在没有太阳能发电的情况下没有任何干扰,并将反应性转移到网格中,而无需任何干扰。该项目是在MATLAB中的仿真的帮助下完成的,并且在稳态条件和动态条件下都可以完成硬件原型的测试结果。

安全的Web网关(SWG) - Innet
威胁英特尔基于我们自己的AI/ML模型和第三方供稿。第一方英特尔源自全球遥测,是最大的权威和递归DNS解析器之一(2T+查询/天)。我们的Web攻击者还每隔几周就会索引整个网络(8B+页),以揭示新兴的广告系列基础架构。自定义威胁饲料和签名(IP,URL和域等)也得到支持。

使用AES算法
方案也已广泛用于构建几种类型的加密协议[4],因此,它们在不同领域(例如访问控制,打开银行库,打开保险箱的存款箱甚至发射导弹)中有许多应用程序。Borchert [5]建议的基于细分的视觉加密图仅可用于加密包含符号的消息,尤其是诸如银行帐号,金额等数字等。Wei-Qi Yan等人提出的VC [6]只能应用于印刷文本或图像。Monoth [7]提出的一种递归VC方法在计算上是复杂的,因为编码的共享被递归地编码为子共享数量。同样,Kim [8]提出的一种技术也遭受了计算复杂性,尽管它避免了像素的抖动。先前关于VC的大多数研究工作都致力于改善两个参数:像素扩展和对比[9] [10] [11]。在这些情况下,所有持有股份的参与者都是诚实的,也就是说,在恢复秘密图像的阶段,他们不会出现虚假或假股份。因此,股票堆叠中显示的图像被视为真实的分泌图像。,但这可能并非总是如此。因此,Yan [12],Horng [13]和Hu Metal [14]引入了预防作弊方法。,但在所有这些方法中都可以观察到,没有身份验证测试的设施。
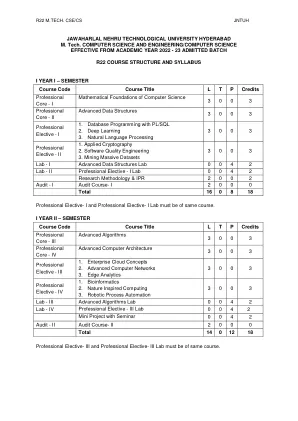
r22 m. 技术。中央安全与环境部
第一单元:基础逻辑与证明:命题逻辑、命题逻辑的应用、命题等价、谓词和量词、嵌套量词、推理规则、证明简介、证明方法与策略。第二单元:基本结构、集合、函数、序列、和、矩阵和关系:集合、函数、序列与和、集合和矩阵关系的基数、关系及其性质、n 元关系及其应用、表示关系、关系的闭包、等价关系、偏序。第三单元:算法、归纳与递归:算法、函数的增长、算法的复杂性。归纳与递归:数学归纳、强归纳与良序、递归定义与结构归纳、递归算法、程序正确性。第四单元:离散概率和高级计数技术:离散概率简介。概率论、贝叶斯定理、期望值和方差。高级计数技术:递归关系、解决线性递归关系、分治算法和递归关系、生成函数、包含-排除、包含-排除的应用。第五单元:图:图和图模型、图术语和特殊类型的图、表示图和图同构、连通性、欧拉和汉密尔顿路径、最短路径问题、平面图、图着色。树:树的简介、树的应用、树的遍历、生成树、最小生成树。教科书:

使用机器学习的慢性肾脏疾病风险预测
在医疗保健中,在对患者的药用病史进行了彻底的身体评估和分析以及对适当的诊断测试和程序的利用后进行诊断。由于慢性肾脏疾病(CKD)的并发症,全球170万人每年都会丧生。尽管有其他诊断方法的可用性,但由于其卓越的准确性,此研究依赖于机器学习。患有慢性肾脏疾病(CKD)的患者患有健康并发症,例如高血压,贫血,矿物质骨疾病,营养不良,酸异常和神经系统并发症,可能会受益于及时且准确地识别疾病水平,以便尽可能尽可能地接受最有效的药物治疗。已经研究了有关CKD使用机器学习(ML)策略的早期认可的几项作品。舞台预期的准确性并不是他们的主要关注点。在本研究中,二进制和多类分类方法已用于阶段预期。随机福雷(RF),支持 - 矢量机(SVM)和决策树(DT)是所采用的预测模型。特征选择是通过使用交叉验证(CV)的变异和递归特征消除的审查进行的。10-FLOD CV用于评估模型。实验表明,使用CV的递归特征去除的RF优于SVM和DT。

证书
理论介绍;有限状态机(FSM):FSM 介绍、FSM 示例、正则语言上的操作、非确定性 FSM 介绍、非确定性 FSM 的形式定义、确定性和非确定性 FSM 的等价性;正则语言:正则操作的闭包、正则表达式、正则表达式与正则语言的等价性、正则语言的抽水引理、正则语言总结;上下文无关语法和语言(CFG 和 CFL):CFG 和 CFL 介绍、CFG 示例、CFL 的种类、CFL 的事实;上下文相关语言:乔姆斯基范式、乔姆斯基层次结构和上下文相关语言、CFL 的抽水引理;下推自动机(PDA):PDA 介绍、CFG 和 PDA 的等价性、从 CFG 和 PDA 的等价性得出结论;图灵机 (TM):TM 简介、TM 示例、TM 定义和相关语言类、Church-Turing 论题、TM 编程技术、多带 TM、TM 中的不确定性、TM 作为问题求解器、枚举器;可判定性:可判定性和可判定问题、对于 DFA 的更多可判定问题、有关 CFL 的问题、通用 TM、无穷大 - 可数和不可数、不可图灵识别的语言、停机问题的不可判定性、不可图灵识别的语言、可归约性 - 一种证明不可判定性的技术、停机问题 - 通过归约证明、可计算函数、TM 的等价性、将一种语言归约成另一种语言、后对应问题、PCP 的不可判定性、线性边界自动机;递归:打印自身的程序、编写自身描述的 TM、递归定理、递归定理的结果、不动点定理;逻辑:一阶谓词逻辑 - 概述、真值(含义和证明)、真实陈述和可证明陈述、哥德尔不完备定理;复杂性:时间复杂度和大 O 符号、计算算法的运行时间、使用不同计算模型的时间复杂度、时间复杂度类 P 和 NP、NP 的定义和多项式可验证性、NP 完备性、SAT 是 NP 完备的证明、空间复杂度类

原始研究产后出血风险预测模型由机器学习算法开发:CLI
背景:产后出血(PPH)是一种严重的并发症,是孕产妇死亡率后的原因。这项研究使用机器学习算法和新功能选择方法来构建有效的PPH风险预测模型,并为PPH风险管理提供了新的想法和参考方法。方法:从2021年1月1日至2022年3月30日在温州人民医院分娩的妇女的临床数据进行了追溯分析,并根据失血量将妇女分为一个高血病组(337例患者)和低血病组(431例)。使用特征选择方法,例如递归功能消除(RFE),交叉验证(RFECV)(RFECV)和SelectkBest,以及以建立预测模型,使用特征选择方法,例如递归功能消除(RFE),递归功能消除,并识别来自多个临床变量中与产后出血相关的特征。结果:对于所有女性,与产后出血相关的特征是“年龄”,“新生体重”,“妊娠周”,“围产裂缝”和“剖腹产”。由随机森林分类器建立的预测模型表现最佳,F1得分为0.73,曲线下的面积为0.84。对于接受剖腹产或阴道分娩的妇女,与产后出血风险相关的特征不同。接受剖腹产的妇女产后出血的危险因素是“年龄”,“平等”,“早产”和“ Placenta Previa”。由随机森林分类器建立的预测模型表现最佳,F1值为0.96,AUC为0.95。阴道分娩女性产后出血的危险因素是“年龄”,“奇偶校验”,“妊娠周”,“糖尿病”,“辅助繁殖”,“高血压(前宾夕法尼亚)”和“多重怀孕”。由Adaboost分类器建立的预测模型表现最佳,F1值为0.65,AUC为0.76。结论:机器学习算法可以有效地识别与临床变量产后出血风险相关的特征,并建立准确的预测模型,为临床医生提供一种新颖的方法,以评估和预防产后出血的风险并防止产后出血。