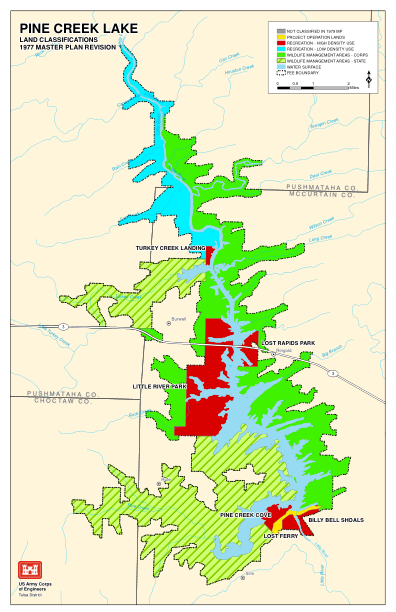
XiaoMi-AI文件搜索系统
World File Search System长叶松


泊松等级印度自助餐 -
在这项工作中,我们对我们称为泊松层的印度bu效过程进行了全面的贝叶斯后验分析,该过程旨在用于复杂的随机稀疏计数物种采样模型,该模型允许跨组内和内部共享信息。此分析涵盖了可能有限数量的物种和未知参数,在贝叶斯机器学习环境中,我们能够随着更多信息的采样而学习。为了实现我们的结合结果,我们采用了一系列从贝叶斯潜在特征模型,随机占用模型和偏移理论中汲取的方法。尽管有这种复杂性,但我们的目标是使从业人员(包括那些可能不熟悉这些领域的人)可以访问我们的发现。为了促进理解,我们采用了一种伪式风格,强调清晰度和实用性。我们的目标是用一种与微生物组和生态学专家产生共鸣的语言来表达自己的发现,以解决建模能力的差距,同时承认我们不是这些领域中的专家。这种方法鼓励将我们的模型用作域专家采用的更复杂框架的基本组成部分,从而体现了Dirichlet过程中开创性工作的精神。最终,我们对后验分析不仅会产生可进行的计算程序,而且还可以实现实际的统计实施,并在微生物组分析中为相关数量提供了明确的映射。

白松泵储存项目</div>
rplus hydro,lllp是Rplus Energies,LLC的子公司。Rplus Energies开发了现代发电厂,以促进对美国能源基础设施的重建。通过与私营部门,市政当局和公用事业的合作,RPLUS Energies开发了公用事业规模的发电厂,以获取该地区最佳可再生资源的最佳组合,以实现更具调度和可靠的电源。RPLUS Energies在美国的15个市场领域拥有30多个项目,包括太阳能,风能,泵送储存水力和太阳能加电池。


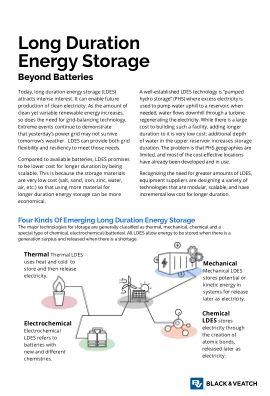
利用长读长的优势进行靶向测序
长读测序技术通过生成足够长的读长来跨越和解析基因组的复杂或重复区域,提高了基因组组装的连续性,从而提高了质量。一些研究小组已经展示了长读长在检测数千个基因组和表观基因组特征方面的强大功能,而这些特征以前被短读长测序方法遗漏了。虽然这些研究表明了长读长如何帮助解析基因组的重复和复杂区域,但它们也强调了使用这些平台准确解析大量群体中的变异等位基因所需的通量和覆盖率要求。在撰写本文时,在最高通量短读长仪器上,全基因组长读长测序比短读长测序更昂贵;因此,实现足够的覆盖率以检测异质样本中的低频变异(如体细胞变异)仍然具有挑战性。另一方面,靶向测序提供了在异质群体中检测这些低频变异所需的深度。在这里,我们回顾了当前使用和最近开发的靶向测序策略,这些策略利用现有的长读技术来提高我们在各种生物背景下观察核酸的分辨率。


长表格通知
因为FI集团和FI员工通常会承担溢价付款的经济负担,因此分配计划分配了两者之间的保费。提出索赔时,FI组和FI员工可以选择默认或替代选项,以确定雇主与该FI集团的任何雇员之间支付的总保费分配。为了有效地处理索赔,分配计划设定了默认分配,如下所示:(1)员工保险费的15%被认为是由雇员支付的(剩余时间)(2)雇员的家庭保险费的34%是由雇员支付的(与雇员一起支付)(与雇员一起支付)。替代选项允许索赔人提交支持供款的数据或记录,高于默认值。以下方案是如何计算估计保费的示例,用于确定索赔人在FI NET和解基金中的比例份额。在FI集团提出索赔的任何情况下,它将获得任何未分配给索赔员工的保费的信贷。