XiaoMi-AI文件搜索系统
World File Search System门阵列

边缘视觉变压器:对模型压缩和加速策略的全面调查
近年来,视觉变形金刚(VIT)已成为计算机视觉任务(例如图像分类,对象检测和分割)的强大而有前途的技术。与依赖层次特征提取的卷积神经网络(CNN)不同,VIT将图像视为斑块和杠杆自我发项机制的序列。但是,它们的高计算复杂性和内存要求对资源受限的边缘设备部署构成重大挑战。为了解决这些局限性,广泛的研究集中在模型压缩技术和硬件感知加速策略上。尽管如此,一项全面的审查系统地将这些技术及其在精确,效率和硬件适应性方面进行了对边缘部署的适应性的权衡。这项调查通过提供模型压缩技术的结构化分析,用于推理边缘的软件工具以及VIT的硬件加速策略来弥合此差距。我们讨论了它们对准确性,效率和硬件适应性的影响,突出了关键的挑战和新兴的研究方案,以推动Edge平台上的VIT部署,包括图形处理单元(GPU),张量处理单元(TPU)(TPU)和现场编程的门阵列(FPGAS)。目标是通过当代指南,以优化VIT,以在边缘设备上进行有效部署,以激发进一步的研究。

在 Xilinx Virtex-4 FPGA 中实现数字射频存储器
数字射频存储器 (DRFM) 是国防工业广泛使用的一种技术,例如,用于生成虚假雷达目标的电子对抗设备。DRFM 技术的目的是使用高速采样以数字方式存储和重建射频和微波信号。在 Saab Bofors Dynamics AB,该技术用于电子战模拟器 (ELSI) 等。DRFM 技术在安装在 ELSI 电路板上的全定制 ASIC 电路中实现。如今,可编程硬件领域的进步使得在现场可编程门阵列 (FPGA) 中实现 DRFM 设计成为可能。与全定制 ASIC 设计相比,FPGA 技术具有许多优势。因此,本硕士论文的目的是开发一种新的 DRFM 设计,该设计可以在 FPGA 中实现,使用一种名为 VHDL 的硬件描述语言。本硕士论文的方法是首先制定时间计划和需求规范。之后,根据需求规范制定设计规范。这两个规范已成为开发 DRFM 电路的基础。设计要求之一是电路应能够通过外部以太网接口进行通信。因此,部分工作是审查市场上可用的外部以太网模块。结果是一个通过模拟测试的 DRFM 设计。测试表明,设计按照设计规范中的描述工作。

评论文章Triboelectric nanogenerator启用了可穿戴电力的智能鞋
摘要 - 作为量子信息处理器在quantum位(Qubit)计数和功能性中生长,控制和测量系统成为大规模可扩展性的限制因素。为了应对这一挑战并保持速度不断发展的经典控制要求,完全控制堆栈访问对于系统级别的优化至关重要。我们设计了一个基于模块化的FPGA(可编程门阵列)的系统,称为Qubic,以控制和测量超导量子处理单元。该系统包括室温电子硬件,FPGA门软件和工程软件。由几个商业现成的评估板和内部开发的电路板组装的原型硬件模式。gateware和软件旨在实现基本的量子控制和测量协议。通过在劳伦斯·伯克利国家实验室(Lawrence Berkeley National Laberatory)的高级量子测试中运行的超导量子处理器上的超导量子处理器上进行量子芯片表征,栅极优化和随机基准测量序列来证明系统功能和性能。通过随机基准测量,单量和两级工艺条件的测量为0.9980±0.0001和0.948±0.004。具有快速电路序列加载能力,Qubic可以有效地执行随机编译实验,并证明执行更复杂的算法的可行性。

UC Berkeley
摘要 - 作为量子信息处理器在quantum位(Qubit)计数和功能性中生长,控制和测量系统成为大规模可扩展性的限制因素。为了应对这一挑战并保持速度不断发展的经典控制要求,完全控制堆栈访问对于系统级别的优化至关重要。我们设计了一个基于模块化的FPGA(可编程门阵列)的系统,称为Qubic,以控制和测量超导量子处理单元。该系统包括室温电子硬件,FPGA门软件和工程软件。由几个商业现成的评估板和内部开发的电路板组装的原型硬件模式。gateware和软件旨在实现基本的量子控制和测量协议。通过在劳伦斯·伯克利国家实验室(Lawrence Berkeley National Laberatory)的高级量子测试中运行的超导量子处理器上的超导量子处理器上进行量子芯片表征,栅极优化和随机基准测量序列来证明系统功能和性能。通过随机基准测量,单量和两级工艺条件的测量为0.9980±0.0001和0.948±0.004。具有快速电路序列加载能力,Qubic可以有效地执行随机编译实验,并证明执行更复杂的算法的可行性。

使用FPGA
摘要:机器人技术,自动驾驶,监视和更多字段依赖于对象检测,这是计算机视觉中的基本工作。由于其低延迟速度和并行处理功能,FPGA系统吸引了对实现对象检测算法的越来越兴趣,这很重要,因为实时处理变得越来越重要。这项工作提供了FPGA体系结构,优化和实时实现的对象检测的概要。建议的方法是选择一个适当的对象检测算法,例如著名的Yolo(您只看一次)或SSD(单镜头多伯克斯检测器),该对象以其速度和准确性比率而闻名。为了实现实时速度,该算法被映射到基于FPGA的硬件体系结构上,该架构利用其可重构性和并行性。基于FPGA的对象检测的重要组成部分是硬件体系结构的设计。优化数据途径,有效控制逻辑的构建以及将算法拆分为硬件友好型组件都是此过程的一部分。以最大程度地利用资源来实现最大化吞吐量的目标,使用了包括并行处理,循环展开和管道的技术。此外,对FPGA的优化需要调整算法和硬件设计,以充分利用目标FPGA设备的功能。减少延迟和增加的吞吐量需要优化数据传输,并行性和内存访问模式。修复错误,提高性能并添加新功能都需要定期维护和升级。使用FPGA的对象检测系统的另一个重要部分是它们与各种传感器或输入流集成的能力。获取用于实时处理的输入数据需要与各种传感器(例如相机和LIDAR设备)集成。由于它们的适应性,FPGA平台很容易被整合到各种应用程序情况下,这要归功于它们与不同传感器的接口。确保在FPGA上构建的对象检测系统是准确,快速且有弹性的,请使用常见数据集和现实世界情景进行验证和测试。为了确保系统实现目标性能指标,对实时处理要求进行了彻底评估。一旦测试,基于FPGA的对象检测系统就可以将其放置在预期的设置中,作为独立设备或较大嵌入式系统的组件。关键字: - FPGA,对象检测,计算机视觉,实时处理,硬件优化,并行处理,嵌入式系统。简介自动驾驶汽车,监视系统,机器人和更多字段依赖于对象检测,这是计算机视觉中的基本工作。在许多领域的智能决策依赖于实时检测和定位事物的能力。即使它们起作用,传统的对象检测方法也不能总是处理实时处理的强烈需求,尤其是在带有移动场景的复杂设置和众多项目中。在开发对象检测系统时,使用FPGA而不是CPU或GPU有很多好处。因此,为了加快对象检测算法并获得实时性能,在使用专用硬件平台(例如现场可编程式门阵列(FPGA))的使用方面一直在增加。首先,现场编程的门阵列(FPGA)非常适合并行化,这意味着可以有效地实现卷积神经网络(CNN)之类的对象识别技术

基于OpenCL的设计的FPGA仪器框架
摘要通过使用开放的计算语言(OPENCL)提高了对高性能重新确定异质计算(HPRHC)系统的生产率。但是,在可编程的门阵列(FPGA)中,OpenCL编译器生成的硬件可能会导致严重的性能瓶颈解决方案。问题是由于生成的NetList细节杂乱无章的事实,使它们大部分不可读取,并且仅对设计师而言仅部分可见。本文提出了一种FPGA仪器方法和一个新的框架,用于提取基于OpenCL的设计的FPGA周期 - 准确的时间表演。结果清楚地表明,基于OPENCL的设计的选择执行模型在未正确实现时会强烈影响时间性能。我们的框架是在包含CPU和两个ARRIA10 FPGA的HPRHC平台上实现的,并通过各种具有不同复杂性的基准进行评估。在报告的基准测试后,一个插入仪器的平均逻辑开销是自适应查找表(ALUTS)总量的0.2%,而FPGA中总寄存器的0.1%。此资源利用率比最佳先前发表的作品中报告的资源低1.5至六倍。还可以通过插入多达50个乐器来评估框架的可伸缩性。实验结果表明,当插入50个仪器时,每工具的平均逻辑利用率为0.19%的Alut和0.17%的寄存器。

人工光合作用:可再生能源的来源-IJRPR
大多数人工智能算法在现有的计算系统上运行,例如中央处理单元(CPU),图形处理单元(GPU)和现场可编程可编程的门阵列(FPGAS)。(Batra,Jacobson,Madhav,Queirolo和Santhanam,2019年; Viswanathan,2020年),也正在开发用于加速机器学习的数字类型或模拟数字混合信号类型的应用特定的集成电路(ASIC)。然而,随着摩尔法律方法的扩展极限,通过现有扩展可以实现的性能和功率效率正在下降。需要一个特殊的处理器来在短时间内接受和处理学习数据,而该处理器是“ AI半导体”。AI半导体是专门针对效率的非内存半导体,以超高速度和超功率实施AI服务所需的大规模计算。AI半导体对应于核心大脑,学习数据并从中得出推断的结果。(Al-Ali,Gamage,Nanayakkara,Mehdipour,&Ray,2020; Batra等,2019; Esser,Appuswamy,Merolla,Arthur,&Modha,2015年)CPU是处理计算机所有输入,输出和命令处理的计算机的大脑。但是,对于需要大规模并行处理操作的AI,串行处理数据的CPU并未优化。为了克服这一限制,GPU已成为替代方案。gpu是针对3D游戏等高端图形处理开发的,但具有并行处理数据的特征,使其成为AI半导体之一。

tauvid™:第一个用于成像阿尔茨海默氏病tau病理学的FDA批准的宠物示踪剂
摘要 - 专门的深度学习(DL)加速器和神经形态处理器的出现为将深度和尖峰神经网络(SNN)算法应用于医疗保健和生物医学应用的新企业带来了新的机会。这可以促进医学互联网系统(IoT)系统和护理点(POC)设备的进步。在本文中,我们提供了一个教程,描述了如何使用各种技术,包括新兴的回忆设备,可编程的门阵列(FPGA)和互补的金属氧化物半导体(CMOS),可用于开发有效的DL加速器,以解决各种诊断诊断,模式识别的诊断,信号过程和信号过程中的各种问题。此外,我们探讨了尖峰神经形态处理器如何补充其DL对应物以处理生物医学信号。该教程通过应用于医疗保健领域的大量神经网络和神经形态硬件的大量文献进行了研究。我们通过执行将传感器融合信号处理任务与计算机视觉相结合的传感器融合信号处理任务来标记各种硬件平台。在推理潜伏期和能量方面进行了专用神经形态处理器和嵌入AI加速器的比较。最后,我们对领域的分析进行了分析,并分享了各种加速器和神经形态处理器引入医疗保健和生物医学领域的优势,缺点,挑战和机遇的观点。

脑刺激
背景:经颅磁刺激 (TMS) 可以对皮质进行非侵入性刺激。在多点 TMS (mTMS) 中,通过调节换能器线圈中的电流,无需线圈移动即可电子控制刺激电场 (E- 场)。目标:开发一种 mTMS 系统,该系统可以调整皮质区域内 E- 场最大值的位置和方向。方法:我们设计并制造了一个平面 5 线圈 mTMS 换能器,以便控制直径约 30 毫米的皮质区域内感应 E- 场的最大值。我们开发了电子设备,其设计由独立控制的 H 桥电路组成,可驱动多达六个 TMS 线圈。为了控制硬件,我们编写了在场可编程门阵列和计算机上运行的软件。为了在皮质中感应出所需的 E- 场,我们开发了一种优化方法来计算线圈中所需的电流。我们对 mTMS 系统进行了表征,并对一名健康志愿者进行了概念验证运动映射实验。在运动映射中,我们保持换能器位置固定,同时以电子方式移动中央前回上的 E 场最大值并测量对侧手的肌电图。结果:换能器由一个椭圆形线圈、两个八字形线圈和两个堆叠在一起的四叶草线圈组成。技术特性表明 mTMS 系统的性能符合设计。测得的运动诱发电位幅度随着 E 场最大值的位置而持续变化。结论:开发的 mTMS 系统能够在皮质区域内进行电子靶向大脑刺激。© 2021 作者。由 Elsevier Inc. 出版。这是一篇根据 CC BY-NC-ND 许可 (http://creativecommons.org/licenses/by-nc-nd/4.0/) 开放获取的文章。
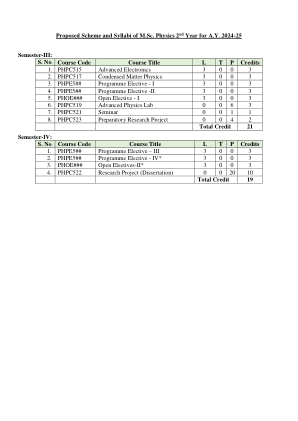
理学硕士物理学第二年拟议的方案和教学大纲...
高级电子学学分 3-0-0:3 课程教育目标: COE1 让学生熟悉先进的电子设备及其应用。 COE2 培养对数字电路设计和使用微控制器连接简单系统的理解。 COE3 培养对通信系统的理解。 UNIT-1 9 L 半导体器件:载流子的漂移和扩散、电荷的产生和复合、直接和间接半导体。PN 结、二极管方程、PN 结的势垒宽度和电容、变容二极管、开关二极管、作为开关和放大器的 FET、光电器件:LED、二极管激光器、光电探测器和太阳能电池。 UNIT-2 9 L 先进电子设备:金属氧化物场效应晶体管 (MOSFET)、MOSFET 中的短沟道效应、鳍式场效应晶体管 (FinFET)、铁电场效应器件和 2D 纳米片器件;新兴存储设备:DRAM、ReRAM、FeRAM 和相变存储器 (PCM) 以及通用存储设备。UNIT-3 10 L 模拟系统:锁相环及其应用频率倍增;模拟乘法器及其应用;对数和反对数放大器;仪表放大器;传感器:温度、磁场、位移、光强度和力传感器组合电路设计:编程逻辑器件和门阵列、7 段和 LCD 显示系统、数字增益控制、模拟多路复用器、基于 PC 的测量系统;序贯电路设计:不同类型的 A/D 和 D/A 转换技术、TTL、ECL、MOS 和 CMOS 操作和规格。 UNIT-4 9 L 通信系统:通信系统的概念、电磁频谱的作用、通信系统术语的基本概念、调制的必要性、幅度、频率、脉冲幅度、脉冲位置、脉冲编码调制、通信系统中的信息、编码、脉冲调制的类型、脉冲宽度调制 (PWM)、脉冲位置调制 (PPM)、脉冲编码调制 (PCM) 的原理;数字通信简介。参考书: