XiaoMi-AI文件搜索系统
World File Search System非专业

生成式 AI 指南 – 非律师
• 亲自出庭的诉讼当事人:在法院或法庭上代表自己的人(有时也称为自我代理或无代理的诉讼当事人)。• 麦肯齐之友:出庭支持没有法律代表的人的非律师。• 非专业辩护律师:出庭青年和家庭法院的法院指定的非律师,或出庭(有时代表)某些法庭的人的非律师。• 就业辩护律师:代表涉及就业纠纷的人的非律师。


使用彩色编码的平视飞行符号系统进行飞行员表现
在显示符号设计中,色彩处理一直被认为是一种改善操作员体验和性能的方法。彩色平视显示器 (HUD) 和头盔显示器 (HMD) 技术的最新发展强调了了解符号颜色编码与传统单色符号格式的人为因素考虑的必要性。在这个低保真桌面人机在环实验中,叠加符号集上的飞行符号颜色被编码为冗余提示,以指示专业和非专业飞行员在一系列模拟飞行操作中的飞行剖面的准确性。这项研究的主要发现是彩色编码飞行符号支持专业和非专业飞行员的手动飞行性能。值得注意的是,倾斜指示器和空速带的颜色编码分别最大限度地减少了转弯和高度变化操作期间的性能误差。彩色编码符号的可用性也高于单色符号。我们得出结论,用户更喜欢彩色编码的 HUD/HMD 符号系统,并且可能在低工作量手动飞行任务中提高性能。要更全面地了解性能和工作量的影响,需要未来的研究采用更高工作量的飞行任务,并检查颜色编码在更高保真度环境中的实用性。



GPT-3 人工智能模型的诊断和分类准确性
重要性:医疗保健中的人工智能 (AI) 应用已在医学的许多领域中有效发挥作用,但它们通常使用标记数据进行单一任务训练,这使得部署和普遍性具有挑战性。通用 AI 语言模型是否可以执行诊断和分类尚不得而知。目标:将通用生成式预训练 Transformer 3 (GPT-3) AI 模型的诊断和分类性能与使用互联网的主治医生和非专业成年人进行比较。设计:我们比较了 GPT-3 对 48 个经过验证的常见(例如病毒性疾病)和严重(例如心脏病发作)病例小插图的诊断和分类能力与非专业人士和执业医师的准确性。最后,我们检查了 GPT-3 对诊断和分类的信心校准程度。设置和参与者:GPT-3 模型,一个具有全国代表性的非专业人士和执业医师样本。接触:经过验证的案例小插图(<60 字;<6 年级阅读水平)。主要结果和测量:正确诊断,正确分类。结果:在所有病例中,GPT-3 对 88%(95% CI,75% 至 94%)的病例的前 3 位做出了正确诊断,而普通人为 54%(95% CI,53% 至 55%)(p<0.001),医生为 96%(95% CI,94% 至 97%)(p=0.0354)。GPT-3 的分类(71% 正确;95% CI,57% 至 82%)与普通人(74%;95% CI,73% 至 75%;p=0.73)相似;两者都明显差于医生(91%;95% CI,89% 至 93%;p<0.001)。根据 Brier 评分,GPT-3 对其最佳预测的信心在诊断(Brier 评分 = 0.18)和分类(Brier 评分 = 0.22)方面相当准确。结论和相关性:通用 AI 语言模型无需任何内容特定训练即可执行接近但低于医生的诊断水平,并且优于普通人。该模型在分类方面的表现较差,其表现更接近普通人。
COVID-19 疫苗谣言与事实社交媒体工具包
此工具包适用于哪些人?此工具包旨在帮助社区、卫生和社会服务组织、非专业健康顾问 (promotoras)、基督教青年会/基督教女青年会、兄弟会、学校组织(例如 PTA/PTO)、老年中心、信仰组织和其他组织在其社交媒体网络和教育渠道上分享有关 COVID-19 疫苗和 COVID-19 的准确信息、FDA 官方 COVID-19 信息,以对抗错误信息和疫苗犹豫。

提高加拿大孕妇的疫苗接种率
该工具包为卫生专业人员(以及社区和患者团体)提供循证资源,以支持建设性对话并帮助孕妇做出明智的疫苗接种选择。它以非技术语言表达直接、易于理解的答案,满足非专业受众的需求,帮助卫生专业人员无需将复杂的循证信息改编成患者可以理解的语言。总体而言,该工具包为卫生专业人员提供了清晰的信息,让他们可以依靠这些信息与患者一对一讨论妊娠期疫苗接种问题。

2022 年重点更新和指南
美国红十字会重点更新和指南 2022 致力于护士、医生、院前专业人员、治疗师、技术人员、执法人员、消防/救援人员、高级执业专业人员、救生员、急救人员、非专业急救人员以及所有其他专业人员和个人,他们准备好并愿意在紧急情况发生或有人需要护理时采取行动。这些更新和指南也致力于美国红十字会的员工和志愿者,他们贡献自己的时间和才华来支持和教授世界各地的救生技能。
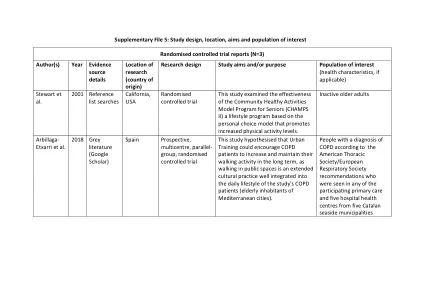
研究设计,位置,目标和感兴趣的人群...
这项研究的目的是确定针对2型糖尿病,糖尿病前期和有糖尿病风险患者的基于电话的非专业患者导航的可行性和可接受性。该计划中患者导航员的主要任务是将其家庭医生转介的患者根据他们的需求和准备改变而将其转诊为最合适的社区资源,并探讨了这种适应性的患者导航器模型是否可能是弥合差距,以弥合与糖尿病护理的初级保健提供者和社区资源相关联的差距。