XiaoMi-AI文件搜索系统
World File Search System顺序

大型语言模型用于可验证的顺序决策...
摘要:基于自动机知识的基于自动机知识的表示在控制和计划的顺序决策问题中起着重要作用。但是,获得建立这种自动机所需的高级任务知识通常很困难。同时,大型语言模型(LLMS)可以自动生成相关的任务知识。但是,LLMS的文本输出不能被验证或用于顺序决策。我们开发了一个名为GLM2FSA的新颖算法,该算法构建了有限的态自动机(FSA),从简短的自然语言描述中编码高级任务知识的任务目标。因此,所提出的算法填补了自然语言任务描述和基于自动机的表示之间的差距,并且可以根据用户定义的任务规范对构造的FSA进行正式验证。我们相应地提出了一种基于结果的结果,从验证中提出了一种方法,以迭代地改进LLM的查询。我们演示了GLM2FSA构建和验证日常任务的基于自动机的表示以及需要高度专业知识的任务的能力。

量子顺序采样器.pdf - 城市研究在线
决策理论中最重要的挑战之一是如何将贝叶斯理论的规范预期与概率推理中常见的明显谬误相协调。最近,贝叶斯模型受到这样的见解的推动,即明显的谬误是由于估计(贝叶斯)概率的抽样误差或偏差造成的。解释明显谬误的另一种方法是调用不同的概率规则,特别是量子理论中的概率规则。可以说,量子认知模型为大量发现提供了更统一的解释,从基线经典视角来看,这些发现是有问题的。这项工作解决了两个主要的相应理论挑战:首先,需要一个结合贝叶斯和量子影响的框架,认识到人类行为中存在两者的证据。其次,有经验证据超越了任何当前的贝叶斯和量子模型。我们开发了一个概率推理模型,无缝集成了贝叶斯和量子推理模型,并通过顺序采样过程进行了增强,将主观概率估计映射到可观察的反应。我们的模型称为量子顺序采样器,它与目前领先的贝叶斯模型贝叶斯采样器 (Zhu、Sanborn 和 Chater,2020) 进行了比较,使用了一项新实验,产生了迄今为止概率推理中最大的数据集之一。量子顺序采样器包含几个新组件,我们认为这些组件为概率推理提供了一种理论上更准确的方法。此外,我们的实证测试揭示了一种新的、令人惊讶的系统性概率高估。
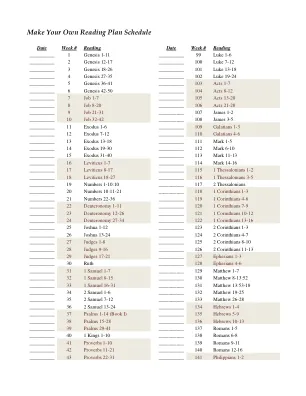
按时间顺序阅读计划 - 制定自己的计划
日期 周数 阅读 日期 周数 阅读 __________ 1 创世纪 1-11 __________ 99 路加福音 1-6 __________ 2 创世纪 12-17 __________ 100 路加福音 7-12 __________ 3 创世纪 18-26 __________ 101 路加福音 13-18 __________ 4 创世纪 27-35 __________ 102 路加福音 19-24 __________ 5 创世纪 36-41 __________ 103 使徒行传 1-7 __________ 6 创世纪 42-50 __________ 104 使徒行传 8-12 __________ 7 约伯记 1-7 __________ 105 使徒行传 13-20 __________ 8 约伯记 8-20 __________ 106 使徒行传 21-28 __________ 9 约伯记 21-31 __________ 107 雅各书 1-2 __________ 10 约伯记 32-42 __________ 108 雅各书 3-5 __________ 11 出埃及记 1-6 __________ 109 加拉太书 1-3 __________ 12 出埃及记 7-12 __________ 110 加拉太书 4-6 __________ 13 出埃及记 13-18 __________ 111 马可福音 1-5 __________ 14 出埃及记 19-30 __________ 112 马可福音 6-10 __________ 15 出埃及记 31-40 __________ 113 马可福音11-13 __________ 16 利未记 1-7 __________ 114 马可福音 14-16 __________ 17 利未记 8-17 __________ 115 帖撒罗尼迦前书 1-2 __________ 18 利未记 18-27 __________ 116 帖撒罗尼迦前书 3-5 __________ 19 民数记 1-10:10 __________ 117 帖撒罗尼迦后书 __________ 20 民数记 10:11-21 __________ 118 哥林多前书 1-3 __________ 21 民数记 22-36 __________ 119 哥林多前书 4-6 __________ 22 申命记1-11 __________ 120 哥林多前书 7-9 __________ 23 申命记 12-26 __________ 121 哥林多前书 10-12 __________ 24 申命记 27-34 __________ 122 哥林多前书 13-16 __________ 25 约书亚记 1-12 __________ 123 哥林多后书 1-3 __________ 26 约书亚记 13-24 __________ 124 哥林多后书 4-7 __________ 27 士师记 1-8 __________ 125 哥林多后书 8-10 __________ 28 士师记 9-16 __________ 126 2哥林多前书 11-13 __________ 29 士师记 17-21 __________ 127 以弗所书 1-3 __________ 30 路得记 __________ 128 以弗所书 4-6 __________ 31 撒母耳记上 1-7 __________ 129 马太福音 1-7 __________ 32 撒母耳记上 8-15 __________ 130 马太福音 8-13:52 __________ 33 撒母耳记上 16-31 __________ 131 马太福音 13:53-18 __________ 34 撒母耳记下 1-6 __________ 132 马太福音 19-25 __________ 35 撒母耳记下 7-12 __________ 133 马太福音 26-28 __________ 36 撒母耳记下 13-24 __________ 134 希伯来书 1-4 __________ 37 诗篇 1-14(第一卷) __________ 135 希伯来书 5-9 __________ 38 诗篇 15-28 __________ 136 希伯来书 10-13 __________ 39 诗篇 29-41 __________ 137 罗马书 1-5 __________ 40 列王记上 1-10 __________ 138 罗马书 6-8 __________ 41 箴言 1-10 __________ 139 罗马书 9-11 __________ 42 箴言 11-21 __________ 140 罗马书 12-16 __________ 43 箴言 22-31 __________ 141 腓立比书 1-2

通过顺序统计分析人类大脑网络的拓扑数据分析
了解整个群体中人类大脑网络的共同拓扑特征对于理解大脑功能至关重要。将人类连接组抽象为图形对于了解大脑网络的拓扑特性至关重要。在考虑到异质性和随机性的同时开发脑图中的组级统计推断程序仍然是一项艰巨的任务。在本研究中,我们使用顺序统计量开发了一个基于持久同源性的稳健统计框架来分析大脑网络。顺序统计量的使用大大简化了持久条形码的计算。我们使用全面的模拟研究验证了所提出的方法,并随后应用于静息态功能磁共振图像。我们发现男性和女性的大脑网络之间存在统计上显着的拓扑差异。

公元前600年电气发育的时间顺序史。
通过电焊接等方法负责更好的金属,更好的化学品,更好,更便宜的结构。实际上,科学的每个分支以及建立在其上的行业都取决于科学的其他分支,因为进步和态度是为了使所有人的利益达成的。
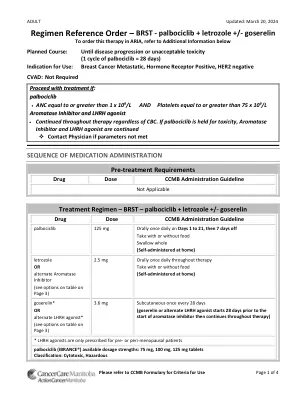
治疗方案参考顺序 – BRST - palbociclib + letrozole +
• ANC 等于或大于 1 x 10 9 /L 并且血小板等于或大于 75 x 10 9 /LAA rroommaattaassee II nnhhiibbiittoorraannd d LLHHRRHH aaggoonniisstt

多代理系统中顺序决策的因果解释
我们介绍了CEMA:c ausal e xplanations in m ulti-themens stystems;在动态的顺序多代理系统中创建因果自然语言解释的框架,以构建更值得信赖的自主代理。与假定固定因果结构的先前工作不同,CEMA仅需要一个概率模型来正向缩减系统状态。使用这种模型,CEMA模拟了反事实世界,这些世界识别了代理决定背后的显着原因。我们评估CEMA的自动驾驶运动计划任务,并在各种模拟场景中对其进行测试。我们表明,即使存在大量其他代理商,CEMA正确地识别了代理决定背后的原因,并通过用户研究表明,CEMA的解释对参与者对自动驾驶汽车的信任具有积极影响,并且对其他参与者的高度基线解释的评价也很高。我们以注释作为HeadD数据集发布了收集的解释。

PCC 顺序和异常测试 | 朴茨茅斯......
此区域包括河流或海洋的水在洪水期间必须流动或储存的土地。功能性洪泛区的确定应考虑当地情况,而不应仅根据严格的概率参数进行定义。功能性洪泛区通常包括:年洪水概率为 3.3% 或更高的土地,且任何现有的洪水风险管理基础设施均有效运行;或设计为洪水泛滥的土地(例如洪水衰减方案),即使它只会在更极端的事件(例如 0.1% 的年洪水概率)下被淹没。地方规划当局应在其战略洪水风险评估中与环境署达成一致,相应地确定功能性洪泛区及其边界。(未与洪水地图上的 3a 区分开)

高级偏好是多息顺序推荐的对比学习的积极示例
基于多功能框架的顺序推荐任务旨在模拟从不同方面的用户的多个兴趣,以预测其未来相互作用。但是,研究人员很少考虑模型产生的利益之间的差异。在极端情况下,所有兴趣胶囊都具有相同的含义,从而导致对具有多种兴趣的用户进行建模。为了解决这个问题,我们提出了高级偏好,作为对对比度学习的积极示例,用于多息序列推荐框架(HPCL4SR),该框架使用对比度学习来区分基于用户项目交互信息的利益差异。为了找到高质量的比较示例,本文介绍了构建全局图的类别信息,学习了用户高级偏好兴趣的类别之间的关联。然后,多层感知器用于适应用户项目的低级偏好兴趣功能和类别的高级偏好兴趣功能。最后,通过项目序列信息和相应的类别获得了用户多兴趣对比样本,这些样本被馈入对比度学习中,以优化模型参数并生成更符合用户序列的多功能表示。此外,在对用户的项目序列信息进行建模时,以增加项目表示之间的不同不同。

顺序细胞事件的开放式分子记录到DNA
遗传编码的DNA记录器非侵入性地将短暂生物学事件转化为细胞基因组中持久的突变,从而可以使用高吞吐量DNA测序1重建细胞体验1。现有的DNA记录器已达到高信息记录2-15,耐用记录3,5–10,13,15-19,多个蜂窝信号的多重记录5-8,19,20以及时间分辨的信号记录记录为5-8,19,20,但在哺乳动物细胞中并非全部。我们提出了一个称为Pechyron的DNA记录器(通过有序插入的Prime编辑21个细胞历史记录记录)。在Pechyron中,哺乳动物细胞经过精心设计,以表达Prime编辑器和Prime编辑指南RNA 21(PEGRNA)的集合,可促进迭代式编辑的迭代回合。在每一轮编辑中,Prime编辑器与恒定的传播序列一起插入可变的三重态DNA序列,该序列会停用以前的序列并激活下一步的插入步骤。编辑可以无限期地继续进行,因为每个插入添加了启动下一步所需的完整序列。因为在任何给定时间只有一个主动目标位点,因此插入以单向顺序依次积累。因此,时间信息是按插入顺序保留的。通过使用只有单个DNA链的主要编辑器来实现耐用性,有效地避免了删除突变,这些突变可能会损坏存储在记录基因座中的信息。高信息含量是通过共表达各种PEGRNA(每个Pegrnas)来确定的,每个Pegrnas都具有独特的三个DNA序列。我们证明,这种PegrNA库的本构表达产生插入模式,以支持细胞谱系关系的直接重建。在替代的Pegrna表达方案中,我们还通过手动脉冲表达来实现多路复用记录,然后从Pechyron记录中重建脉冲序列。此外,我们将特定PEGRNA的表达耦合到特定的生物刺激,这允许哺乳动物细胞种群中化学暴露的暂时分析,多重记录。